Titanic Machine Learning
تفاصيل العمل
مشروع Titanic: Machine Learning هو مشروع في مجال تعلم الآلة يهدف إلى التنبؤ بنجاة ركاب سفينة تايتنك اعتمادًا على بيانات الركاب المختلفة مثل العمر، الجنس، درجة التذكرة، وسعر التذكرة. تم تنفيذ المشروع بدايةً من معالجة البيانات وحتى بناء وتقييم عدة نماذج تعلم آلة للوصول إلى أفضل دقة ممكنة.
ما تم تنفيذه في المشروع:
* تنظيف البيانات ومعالجة القيم المفقودة (Data Preprocessing).
* حذف الأعمدة غير المهمة مثل:
* Cabin
* PassengerId
* Name
* Ticket
* Embarked
* معالجة القيم المفقودة في عمود Age باستخدام Median حسب الجنس.
* تحويل البيانات النصية مثل Sex إلى قيم رقمية باستخدام Label Encoding.
* تقسيم البيانات إلى:
* 70% للتدريب
* 30% للاختبار
* تطبيق Feature Scaling على Age و Fare باستخدام StandardScaler لتحسين أداء النماذج.
التحليل الاستكشافي للبيانات (EDA):
تم إنشاء عدة رسوم وتحليلات لفهم البيانات بشكل أفضل، ومنها:
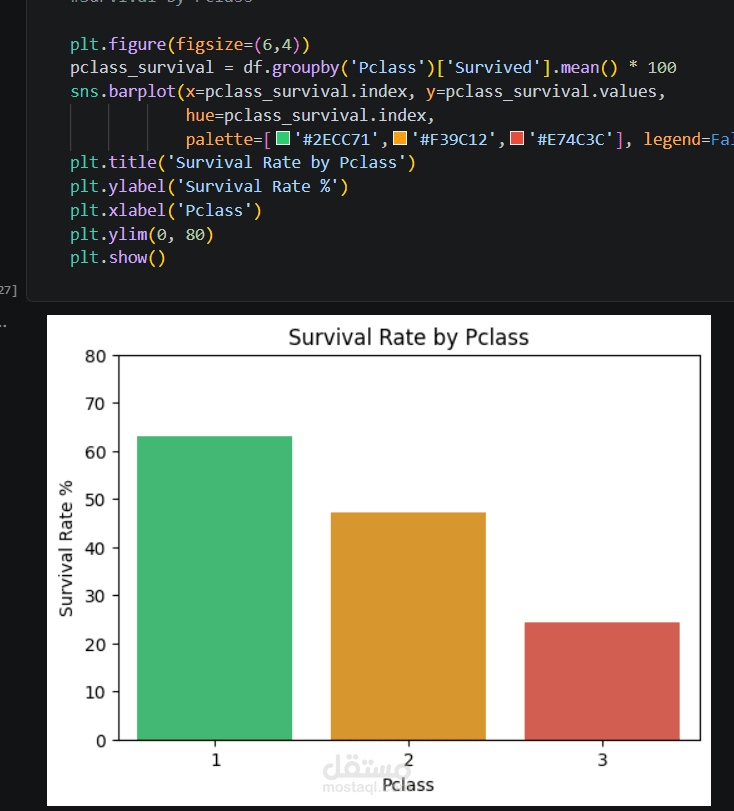
* معدل النجاة حسب درجة الركاب (Pclass).
* معدل النجاة حسب الجنس.
* توزيع الأعمار.
* توزيع أسعار التذاكر.
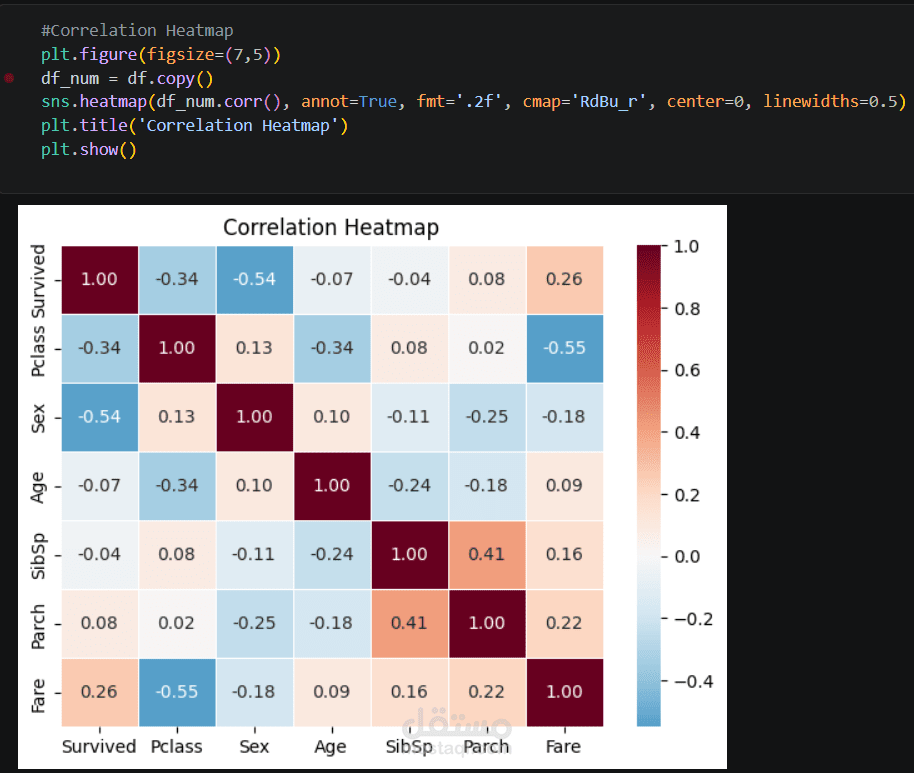
* Correlation Heatmap لمعرفة العلاقات بين المتغيرات.
النماذج المستخدمة:
تم تدريب وتجربة أكثر من نموذج تعلم آلة ومقارنة النتائج بينها:
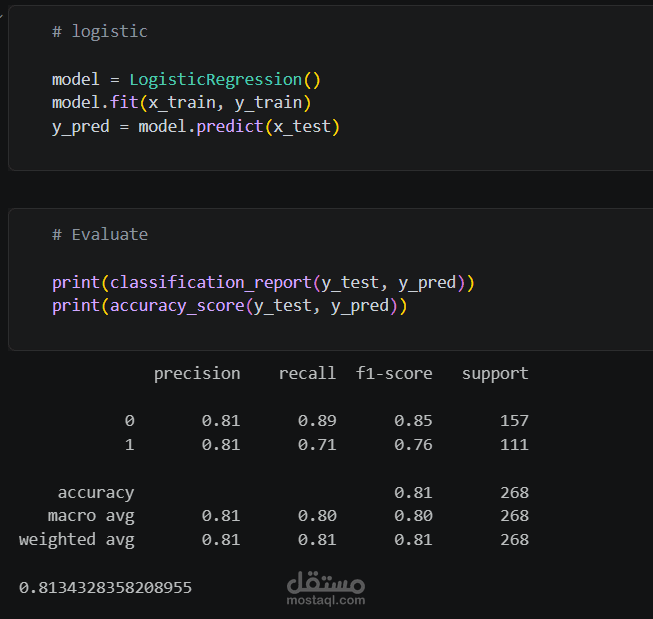
* Logistic Regression — دقة 81.3%
* Decision Tree — دقة 82%
* KNN — دقة 82%
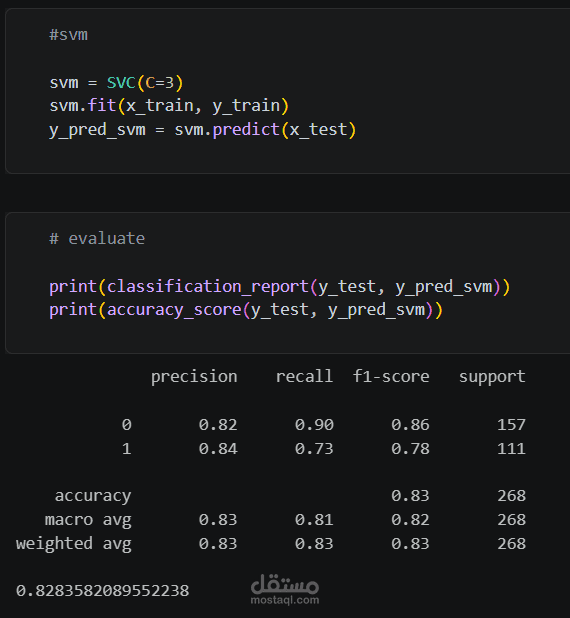
* SVM — دقة 82.8% (أفضل نموذج)
تقييم النماذج:
تم استخدام:
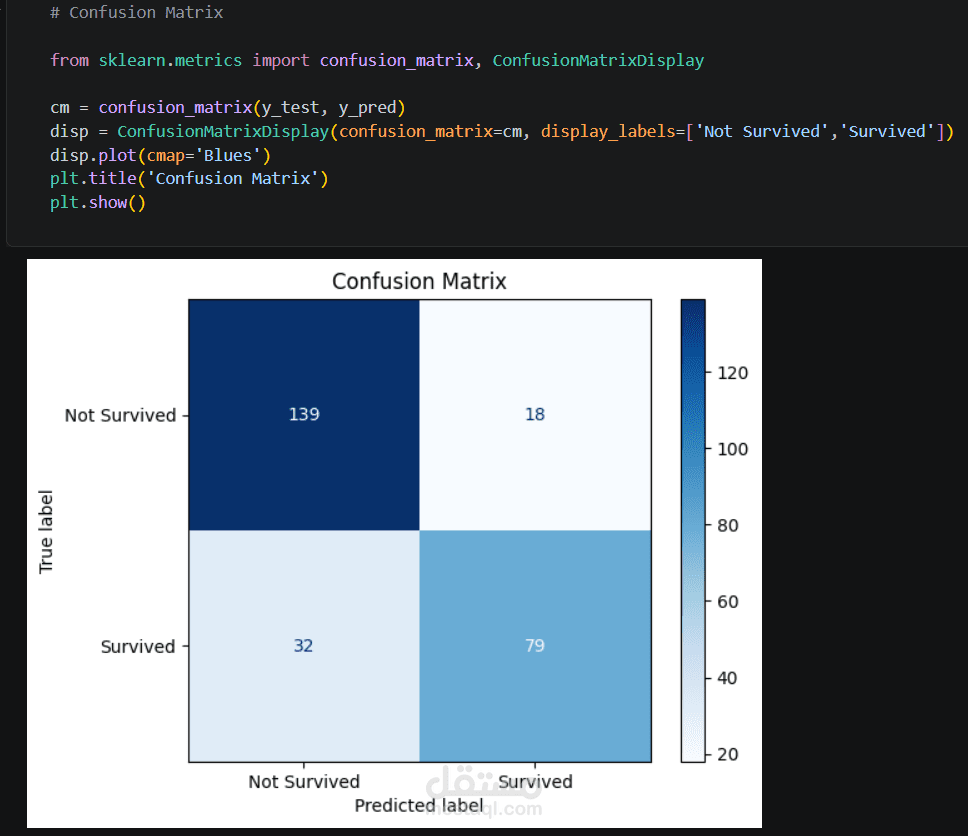
* Confusion Matrix
* ROC Curve
لقياس أداء النماذج وتحليل جودة التوقعات بشكل أدق.
نتائج المشروع:
أظهرت النتائج أن:
* النساء وركاب الدرجة الأولى كانوا الأكثر نجاة.
* الركاب ذوي التذاكر الأعلى سعرًا كانت فرص نجاتهم أكبر.
* نموذج SVM حقق أفضل أداء مقارنة بباقي النماذج.
التقنيات المستخدمة:
* Python
* Pandas
* NumPy
* Matplotlib
* Seaborn
* Scikit-learn