Spam-Ham Text Classification with Natural Language Processing Techniques
تفاصيل العمل
Final Project for DEPI 6-month training.
Spam-Ham Text Classification with Natural Language Processing Techniques
Project Overview
This project focuses on building a machine learning pipeline for classifying SMS messages as Spam or Ham (legitimate messages). The main objective is to leverage both traditional NLP techniques and modern deep learning approaches to create robust models for text classification. Additionally, the project includes deploying a Gaussian Naive Bayes model using Flask and Microsoft Azure for real-time predictions. The problem is particularly challenging due to the inherent imbalance in datasets where Spam messages are fewer than Ham messages. Problem Statement
Spam messages can clutter inboxes and potentially carry harmful content such as phishing links or scams. This project aims to develop an accurate and efficient classifier to:
Identify Spam messages with high precision and recall.
Minimize misclassification of Ham messages to avoid disruptions for legitimate users.
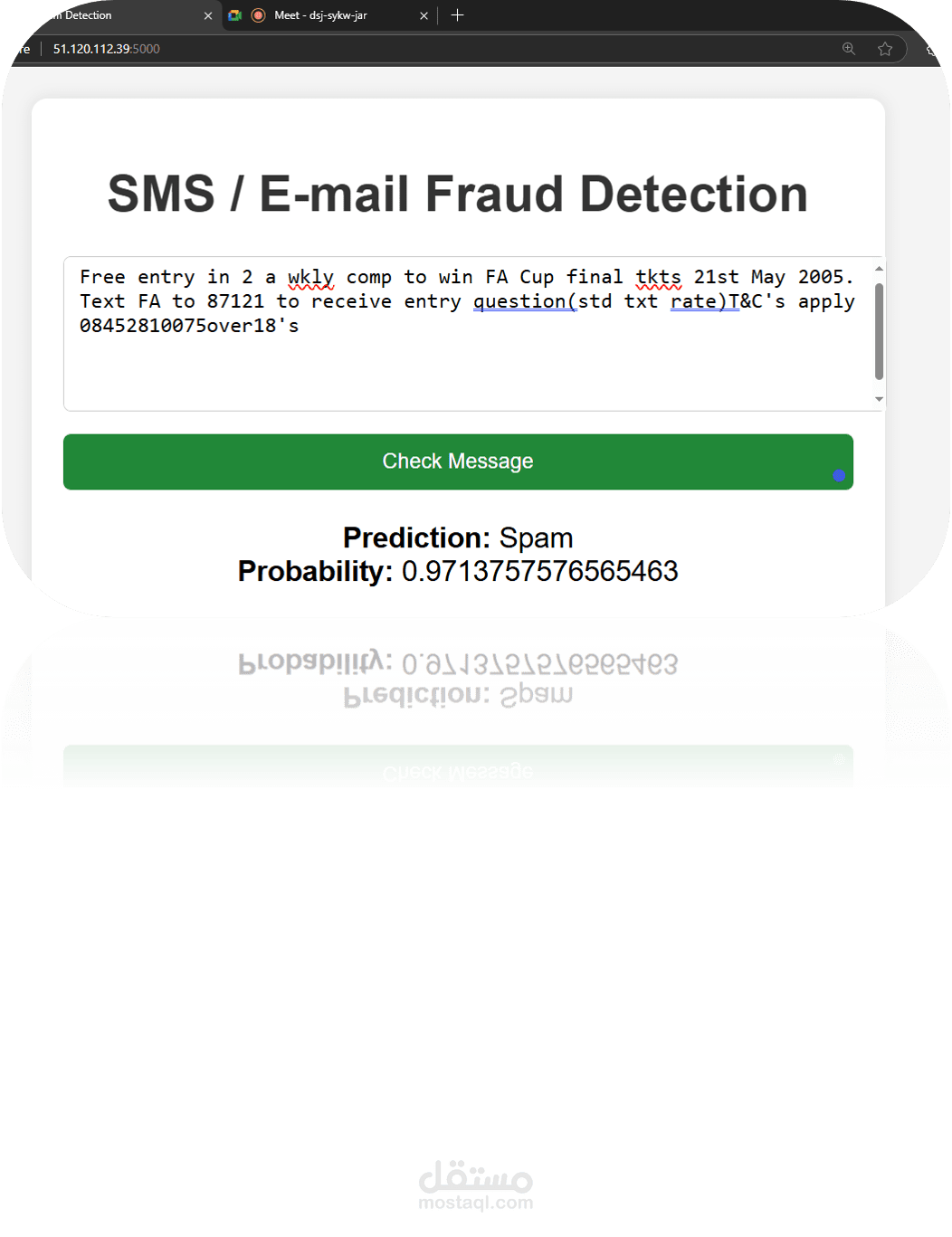
Deploy the model for real-world applications to filter messages in real-time.
Algorithms and Methods
The project implements a hybrid approach combining traditional machine learning techniques, state-of-the-art transformer models, and deployment strategies:
Data Preprocessing
Text Cleaning: Removal of URLs, punctuation, numbers, and special characters. Stopword Removal: Eliminated commonly used words (e.g., "the", "is") using NLTK. Stemming: Used Snowball Stemmer for word normalization.
Exploratory Data Analysis (EDA)
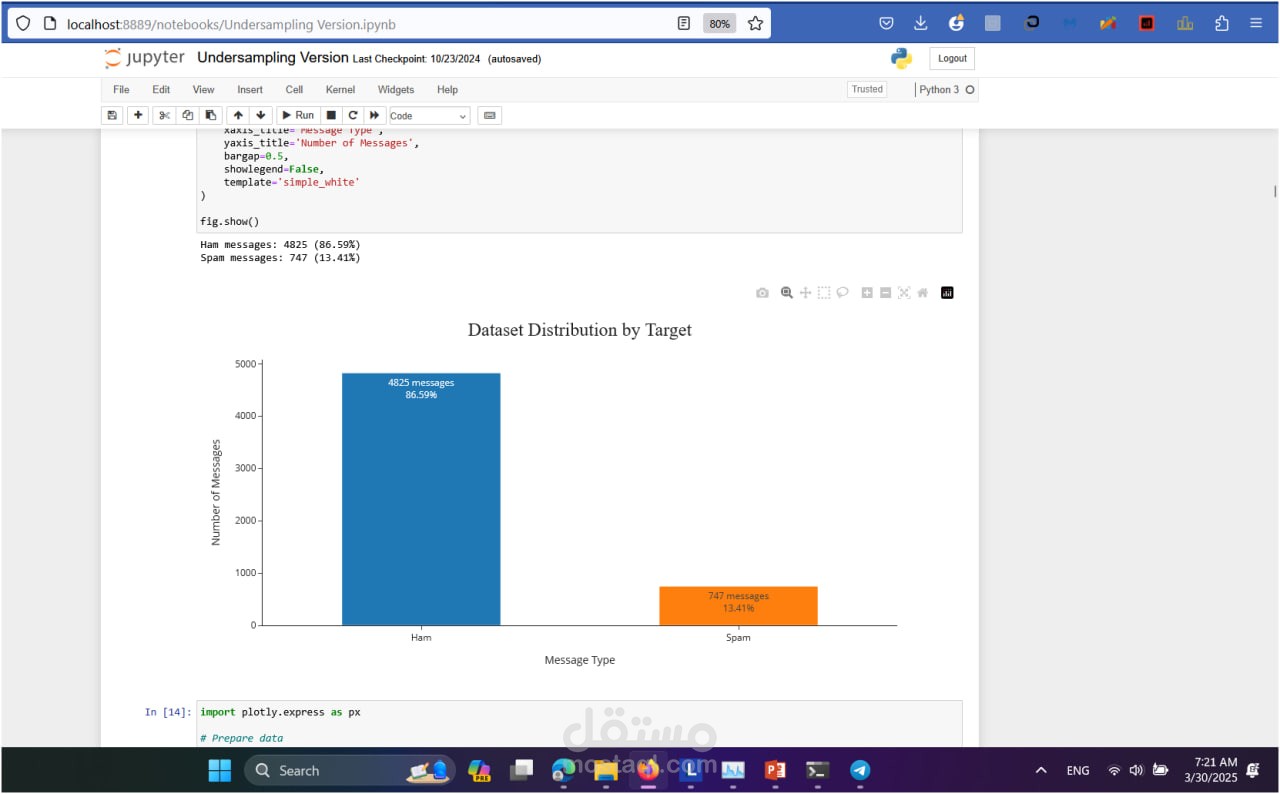
Class Distribution: Investigated using pie charts and histograms. Message Length Analysis: Analyzed message lengths (characters and words) to observe differences between Spam and Ham messages.
Algorithms Used
Traditional Approaches
Bag of Words (CountVectorizer): Transformed text into sparse matrices based on word occurrence.
TF-IDF Transformer: Adjusted feature importance by penalizing common words and emphasizing unique ones.
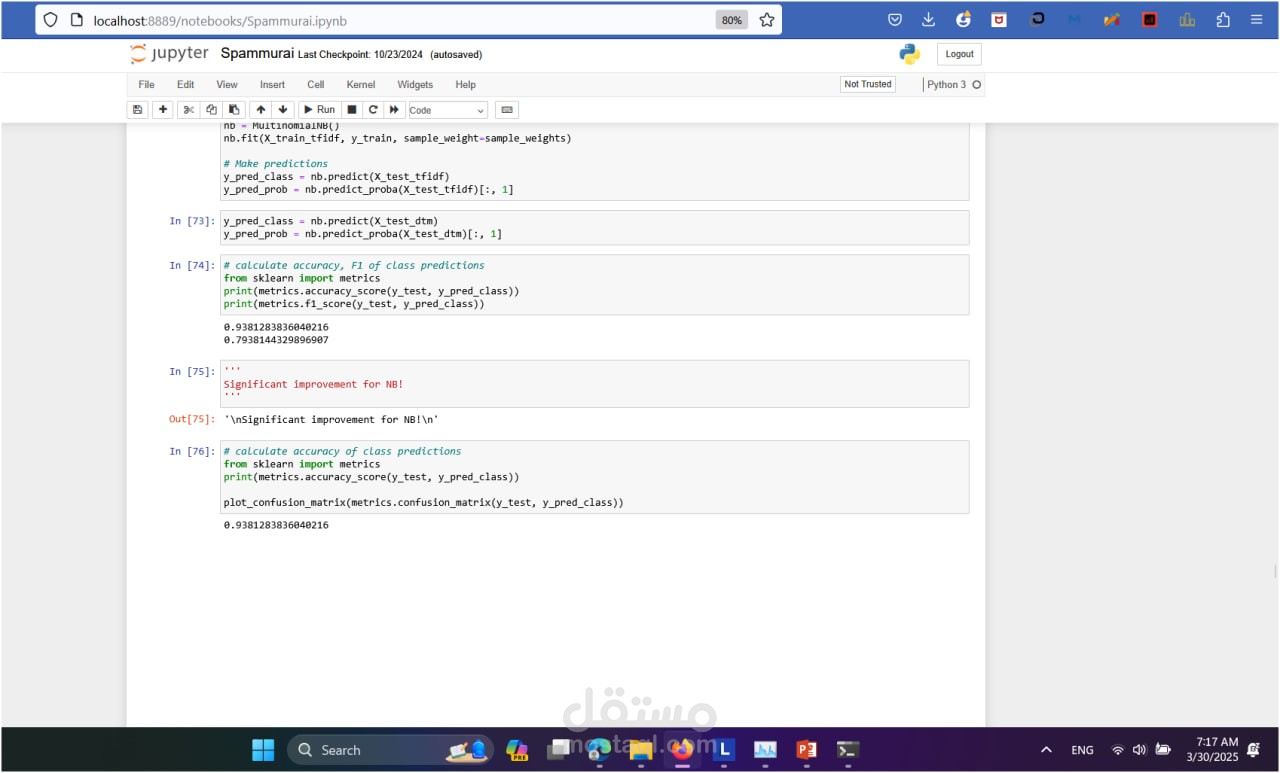
Multinomial Naive Bayes:
Lightweight and fast algorithm.
Performed well with traditional vectorizers.
Gaussian Naive Bayes:
Implemented to handle features that are continuous and assume a Gaussian (normal) distribution.
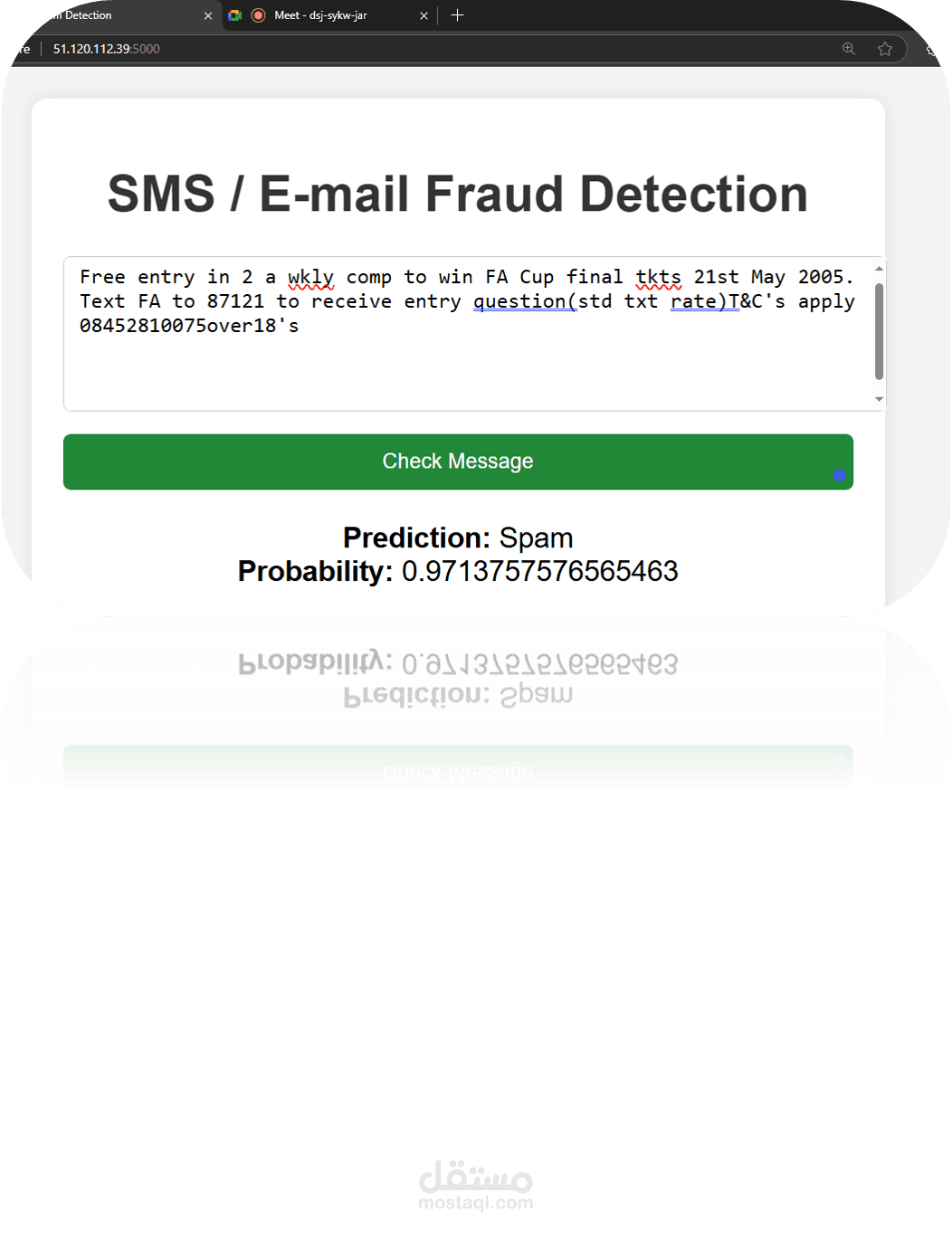
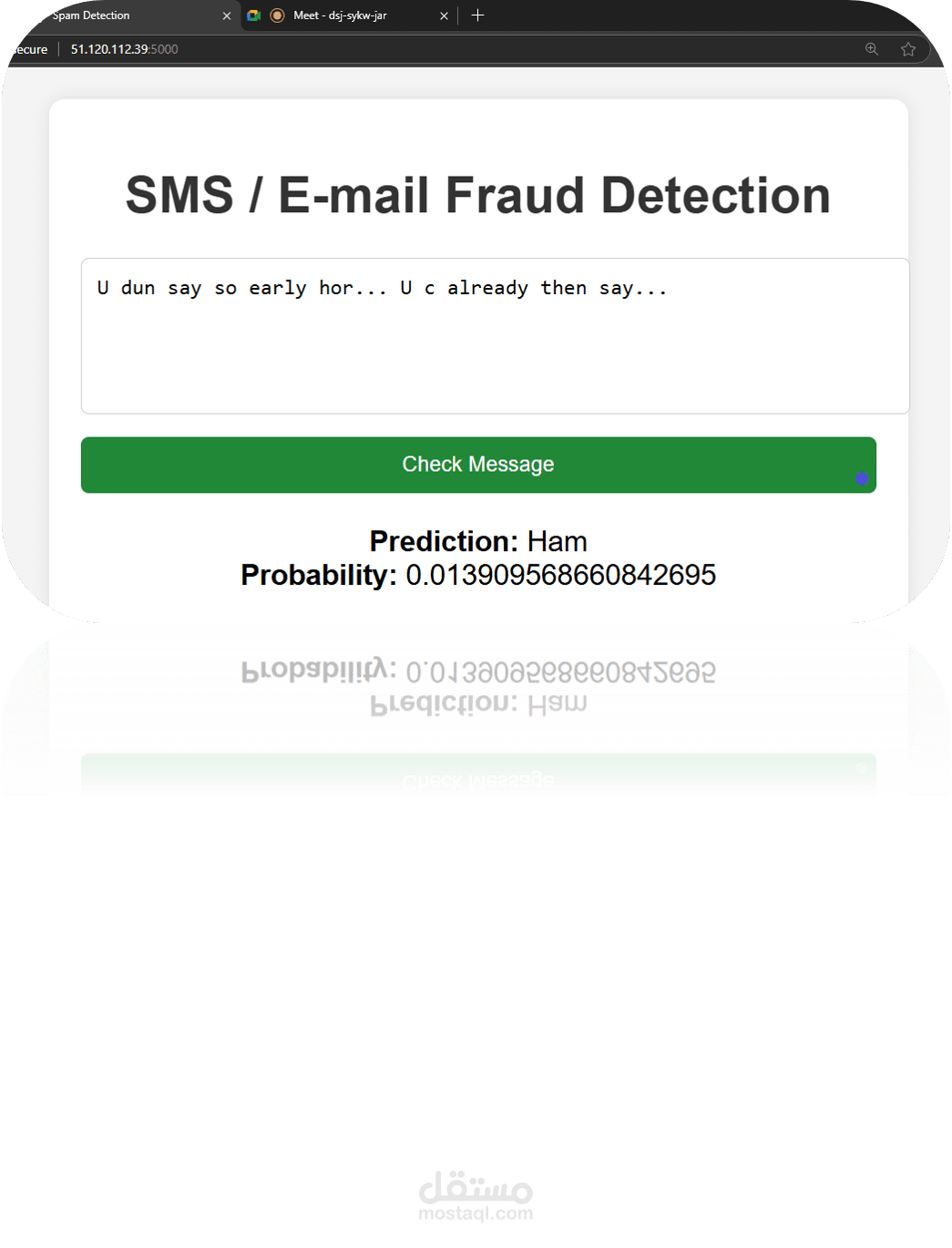
Deployed using Flask and Microsoft Azure for real-time message classification.
Deep Learning
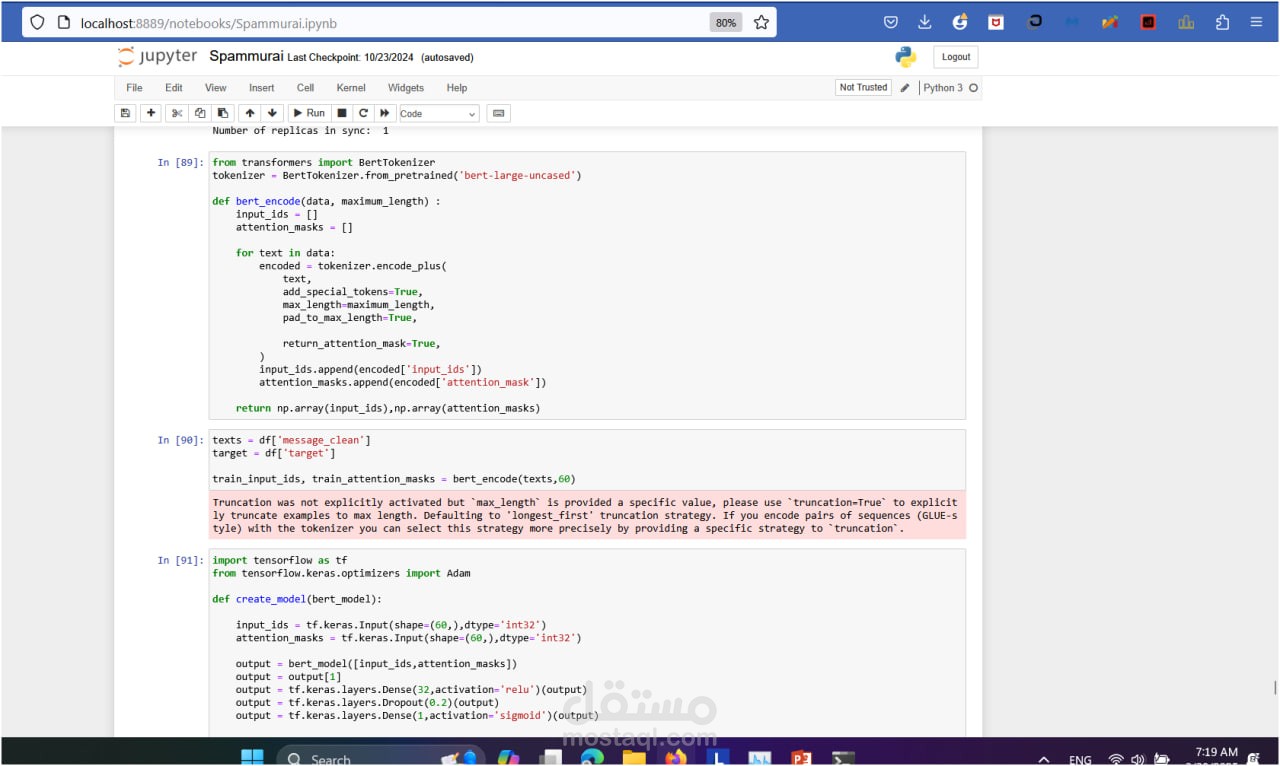
BERT (Bidirectional Encoder Representations from Transformers):
Used pre-trained bert-base-uncased for text embeddings.
Fine-tuned for the Spam-Ham classification task.
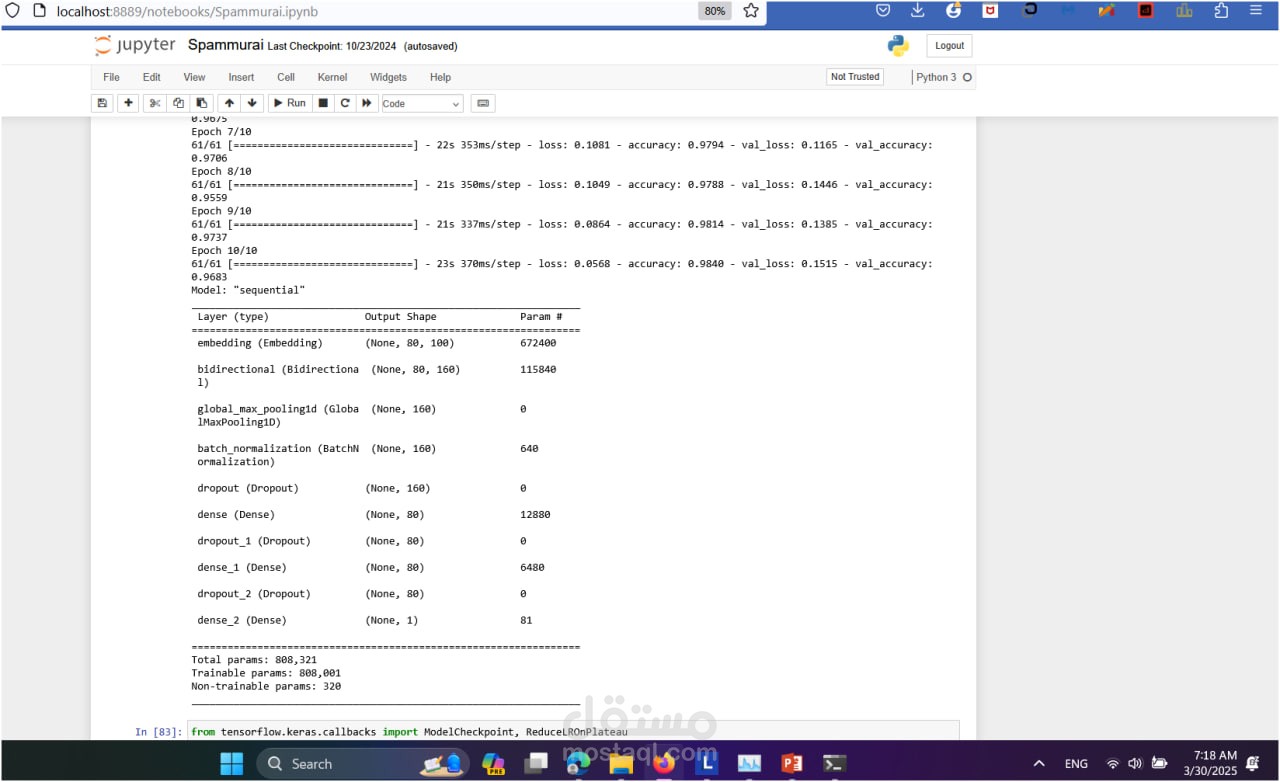
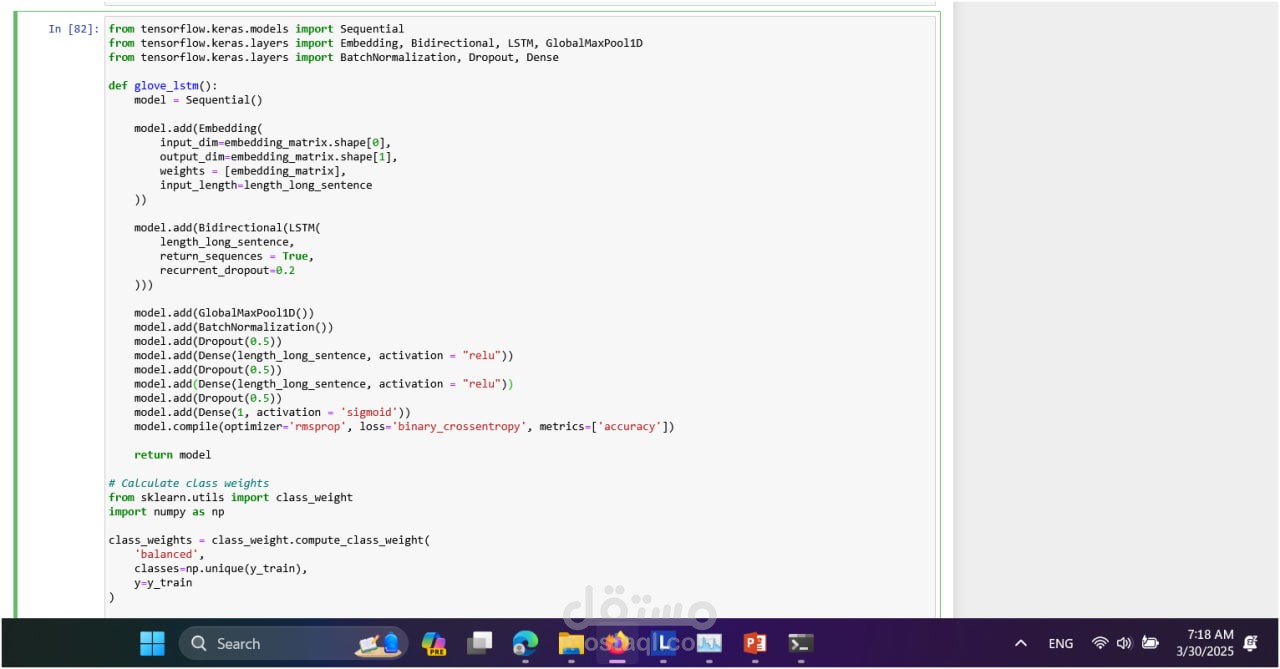
LSTM with GloVe Embeddings:
Built a custom LSTM-based architecture using GloVe embeddings for feature extraction.
Handling Data Imbalance
To address the imbalance between Ham and Spam messages, the following techniques were used:
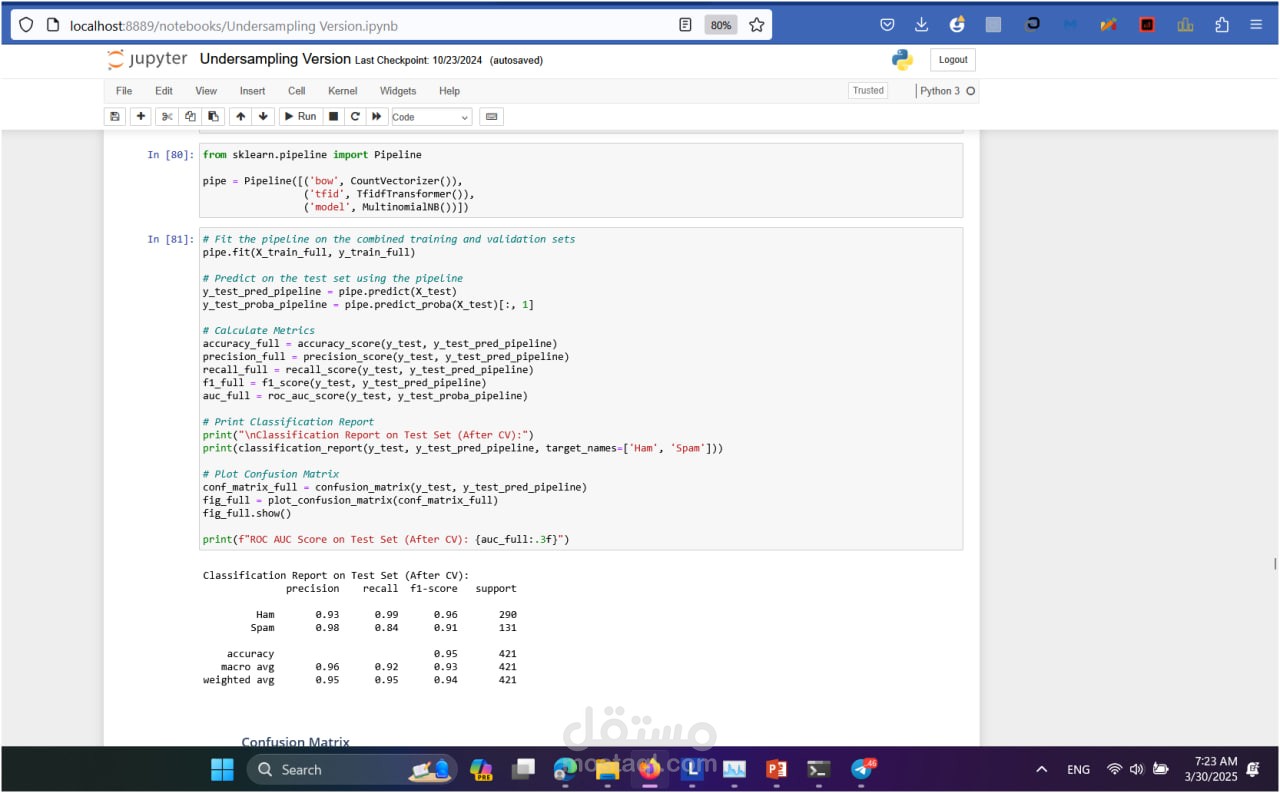
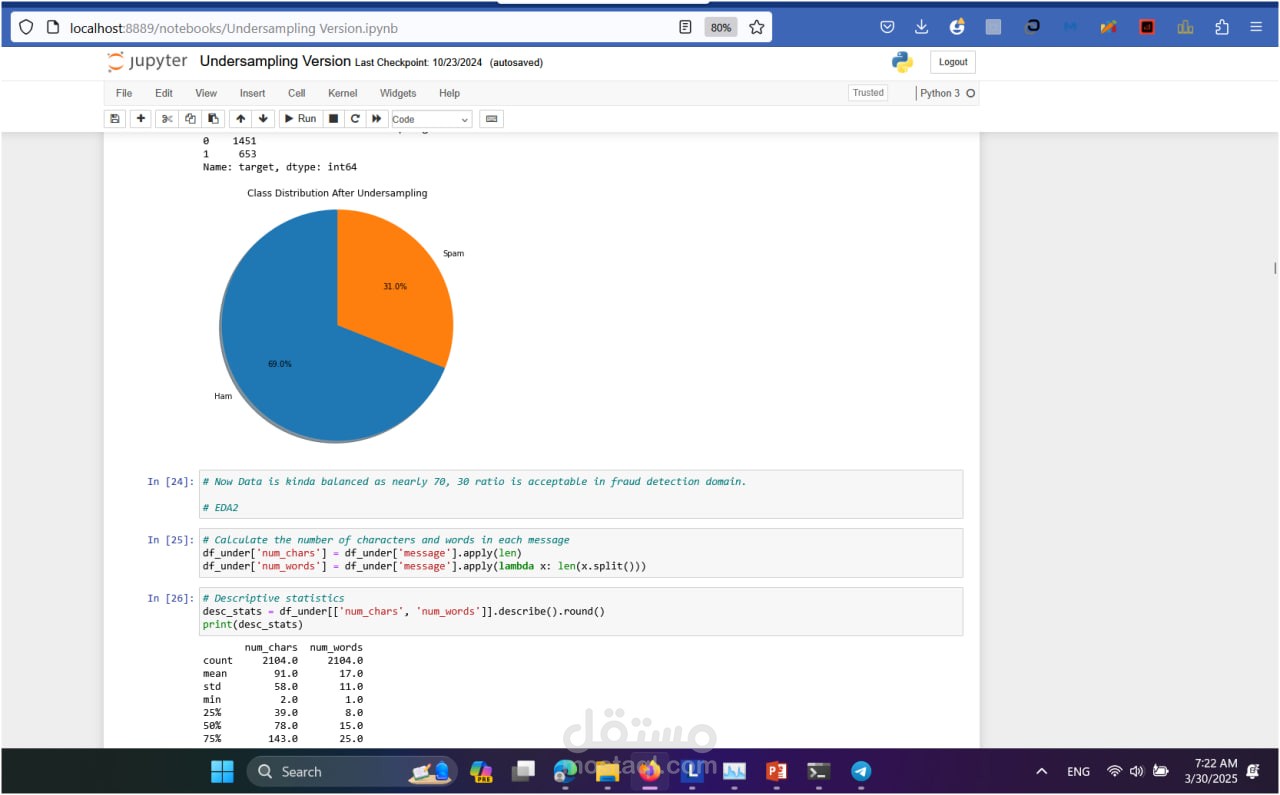
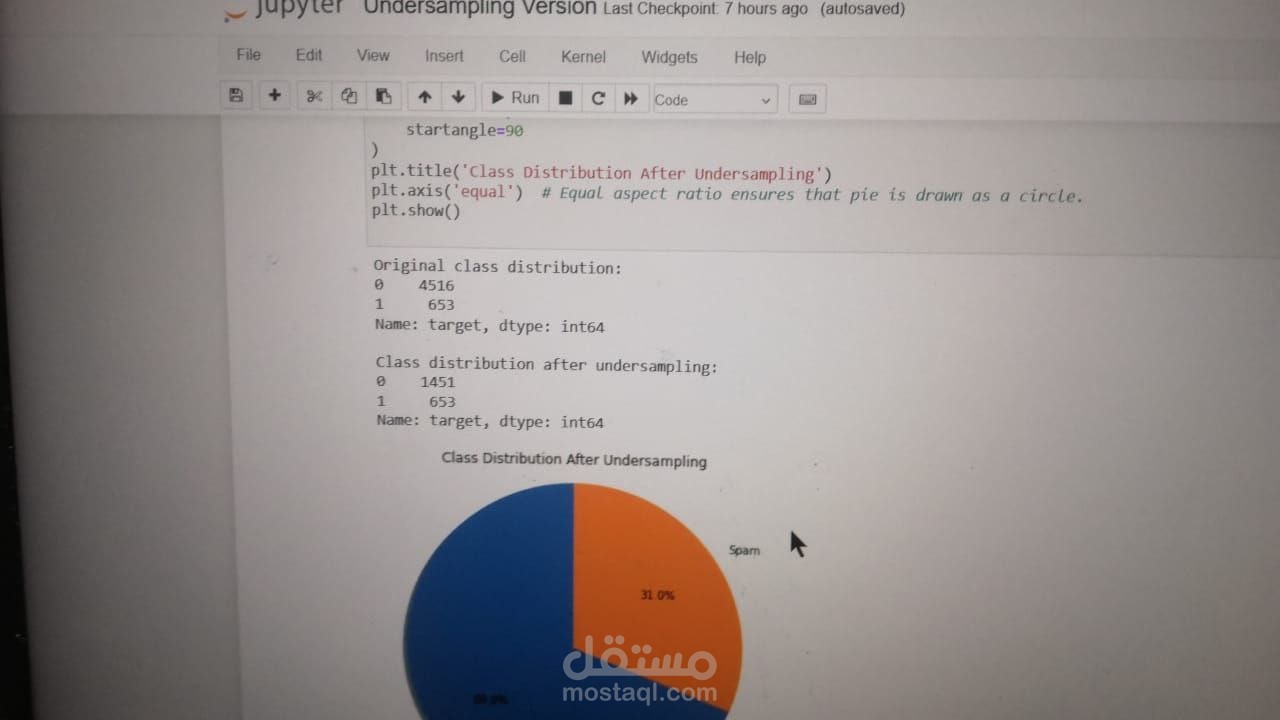
Undersampling:
Reduced the majority class (Ham) to create a balanced dataset by randomly selecting a subset of Ham samples equal to the size of the Spam class.
Ensured the model wasn't biased toward the majority class during training.
Class Weights:
Used class weighting to penalize the model more for misclassifying the minority class (Spam).
Automatically computed weights inversely proportional to the class frequencies using class_weight='balanced' in models like Logistic Regression or Naive Bayes.
Impact of Techniques:
Undersampling: Ensured a balanced representation of classes during training, though at the cost of reducing the dataset size.
Class Weights: Allowed the model to focus on both classes equally, without needing to oversample or undersample the data.
Model Deployment
Flask Web Framework: Created a RESTful API using Flask to serve the Gaussian Naive Bayes model. Enabled real-time predictions by accepting POST requests with message data. Microsoft Azure: Deployed the Flask application on Azure App Service. Leveraged Azure's scalability and reliability for handling incoming requests.
Model Evaluation
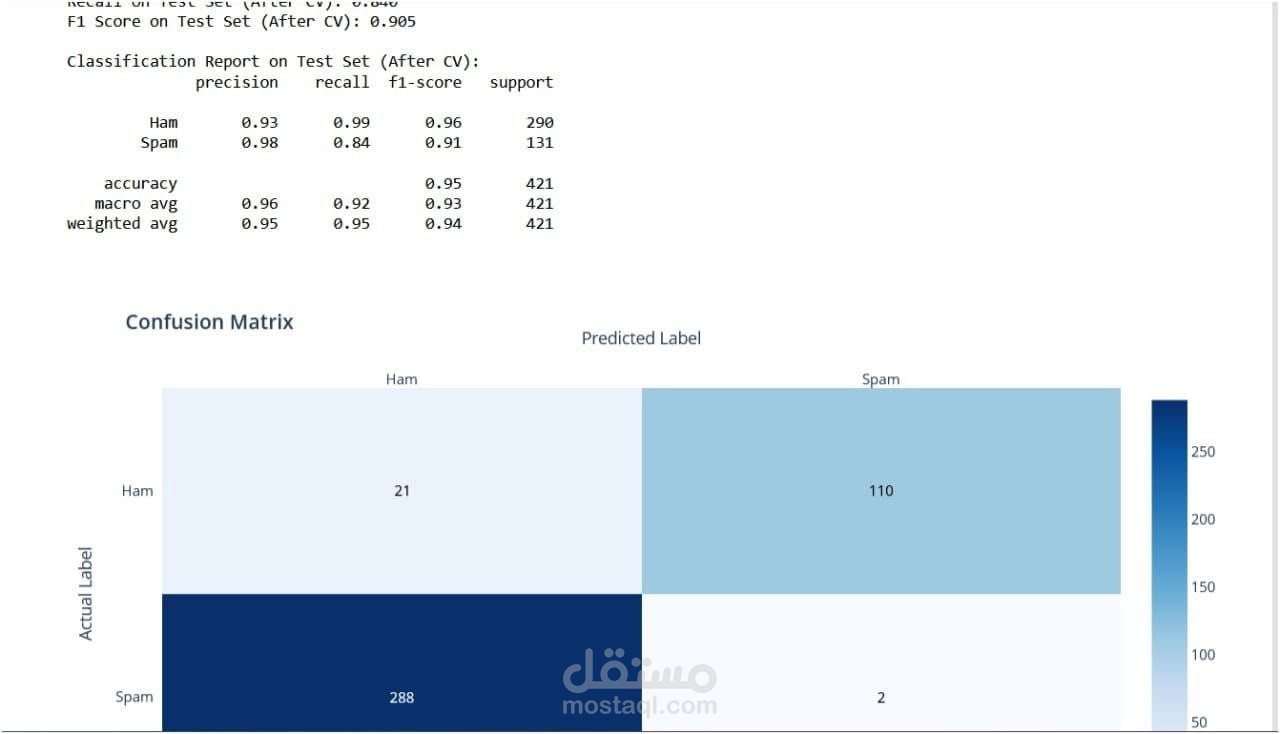
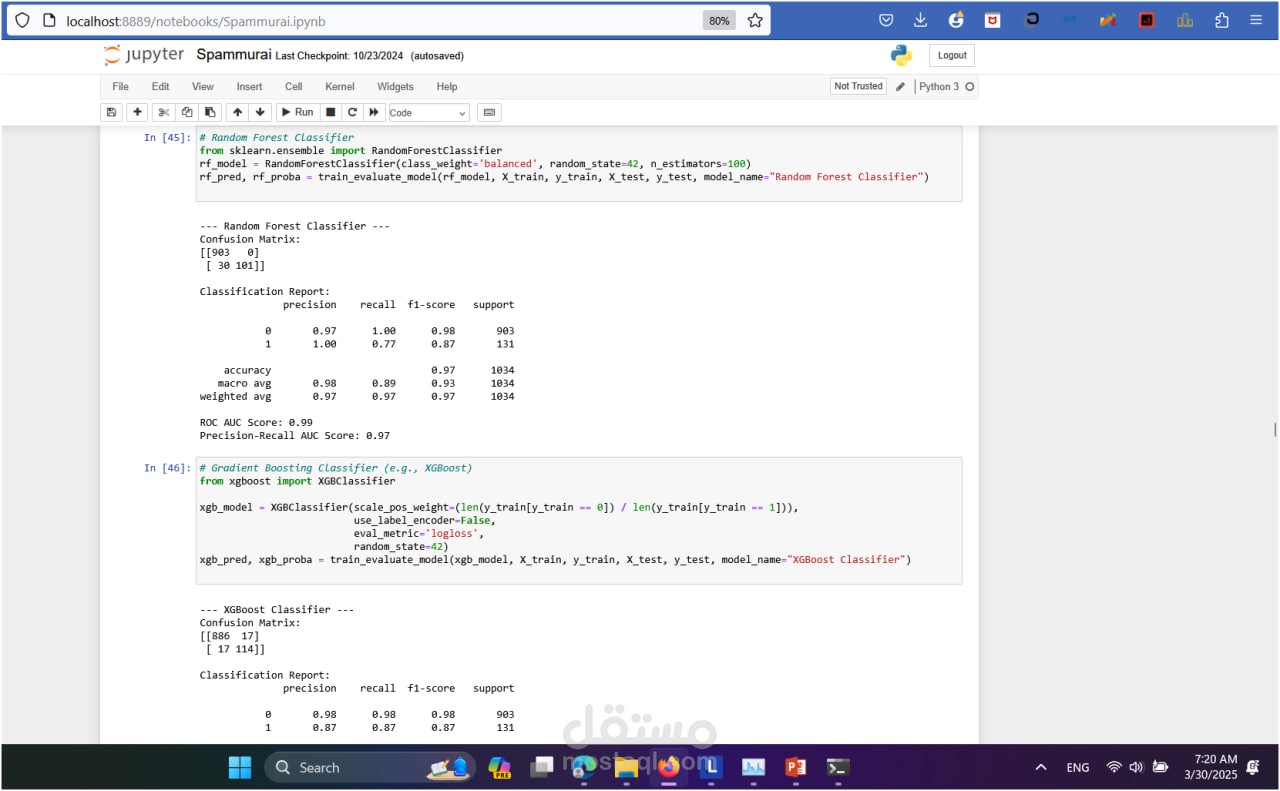
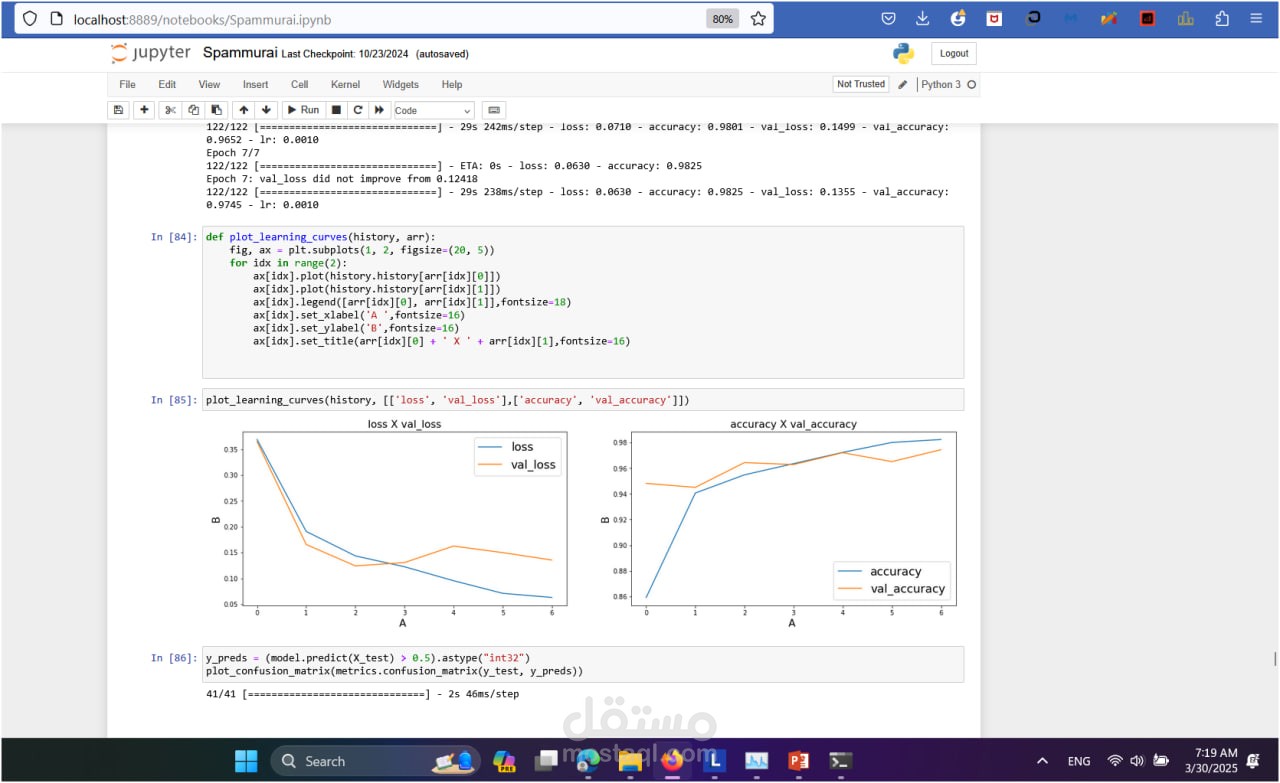
Metrics: Accuracy Precision, Recall, and F1-score (to balance false positives and false negatives) ROC-AUC Score Visualization: Confusion matrices and ROC curves to analyze model performance.
Technologies and Libraries
Programming Language: Python
NLP Tools:
nltk, scikit-learn, transformers (Hugging Face), tensorflow
Data Visualization:
matplotlib, seaborn, plotly
Deep Learning:
TensorFlow/Keras for LSTM and BERT-based models
Imbalance Handling:
imblearn for SMOTE, class weights for fairness
Model Deployment:
Flask for building the web application.
Microsoft Azure for cloud deployment and scalability.