استخراج وسحب بيانات من مواقع كتب الكترونيه وتحليل البيانات تبع الكتب مثل موقع amazon books
تفاصيل العمل

الهدف العام:
الهدف من هذا العمل هو جمع بيانات من مواقع بيع الكتب الإلكترونية (مثل Amazon Books) باستخدام تقنيات Web Scraping، ثم تحليل هذه البيانات لفهم اتجاهات السوق، تفضيلات القراء، وتقييمات الكتب. يمكن استخدام هذه البيانات لأغراض تسويقية، بحثية، أو لتحسين تجربة المستخدم.
خطوات العمل:
تحديد المصادر:
موقع Amazon Books: التركيز على صفحات الكتب الإلكترونية، التقييمات، المراجعات، والأسعار.
مواقع أخرى: مثل Goodreads, Google Books, أو Barnes & Noble (إذا لزم الأمر).
تحليل هيكل الموقع:
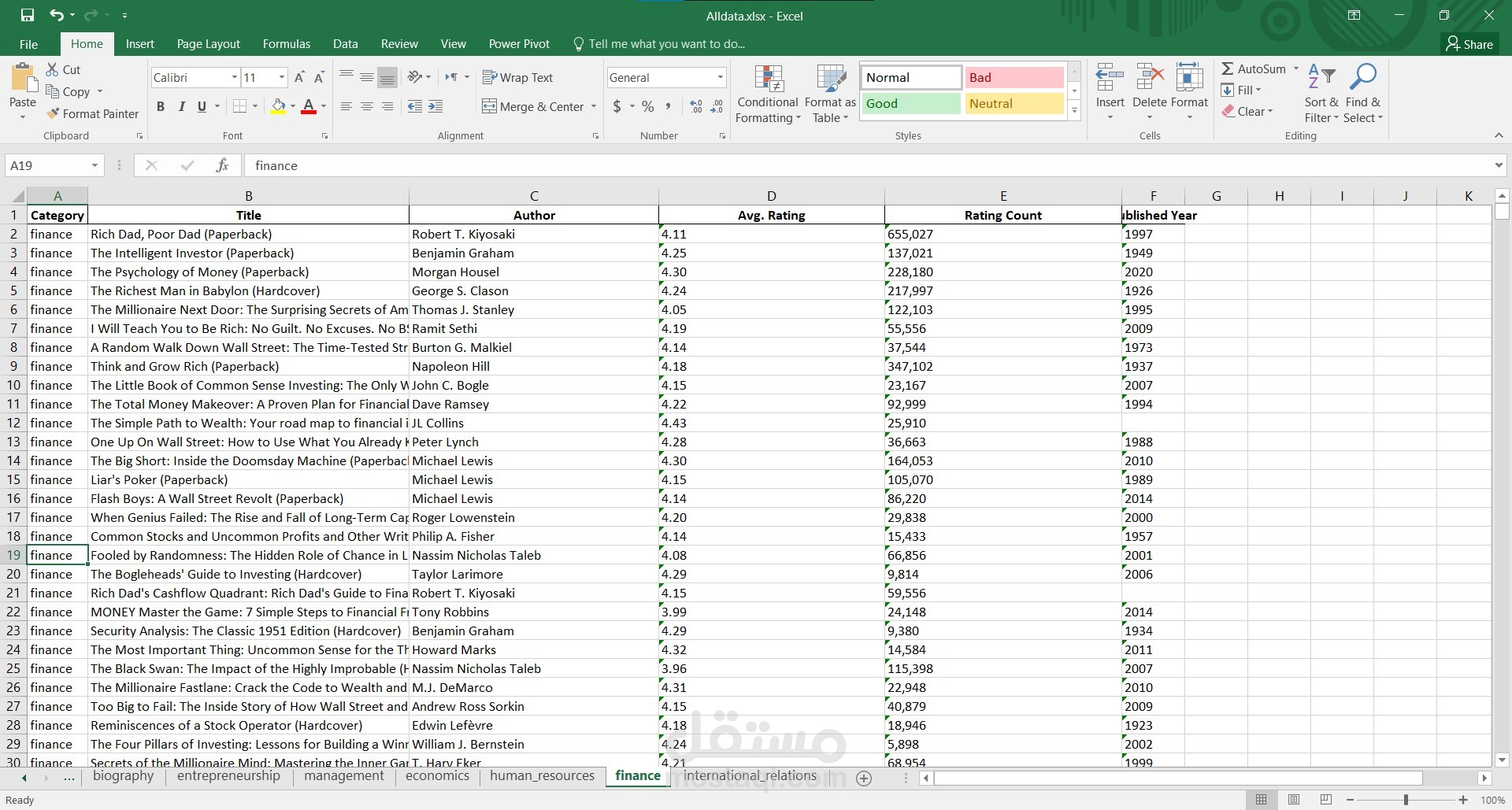
تحليل هيكل صفحات الويب (HTML) لتحديد العناصر التي تحتوي على البيانات المطلوبة مثل:
عنوان الكتاب.
اسم المؤلف.
التصنيفات (Genre).
التقييمات (Ratings).
عدد المراجعات (Reviews).
السعر (إذا كان متاحًا).
تاريخ النشر.
وصف الكتاب.
روابط الصور (غلاف الكتاب).
تطوير أدوات السحب:
استخدام لغات البرمجة مثل Python مع مكتبات مثل:
BeautifulSoup أو lxml لتحليل HTML.
Scrapy أو Selenium لسحب البيانات من صفحات ديناميكية.
Pandas لتنظيم البيانات في جداول.
ضمان الامتثال لشروط استخدام الموقع (Terms of Service) لتجنب المشاكل القانونية.
تنفيذ السحب:
كتابة نصوص برمجية (Scripts) لأتمتة عملية سحب البيانات.
التعامل مع الصعوبات مثل:
الحماية ضد الروبوتات (CAPTCHA).
التحميل الديناميكي للبيانات (AJAX).
تغيير هيكل الموقع بشكل دوري.
تخزين البيانات في ملفات (مثل CSV, JSON) أو قواعد بيانات (مثل MySQL, MongoDB).
تنظيف البيانات:
إزالة البيانات المكررة أو غير ذات الصلة.
تصحيح الأخطاء في البيانات المسحوبة (مثل الأخطاء الإملائية في العناوين أو الأسماء).
تنظيم البيانات في صيغة قابلة للتحليل.
تحليل البيانات:
استخدام أدوات التحليل مثل Python (مع مكتبات مثل Pandas, Matplotlib, Seaborn) أو Excel لاستخراج رؤى قيمة.
تحليل البيانات لمعرفة:
الكتب الأكثر مبيعًا.
الكتب الأعلى تقييمًا.
العلاقة بين السعر والتقييمات.
توزيع الكتب حسب التصنيفات (Genre).
اتجاهات النشر (مثل زيادة الإصدارات في تصنيف معين).