سحب واستخراج بيانات web scraping of different job platforms and hospitals websites
تفاصيل العمل

الهدف العام:
الهدف من هذا العمل هو جمع بيانات دقيقة وحديثة من منصات التوظيف المختلفة ومواقع المستشفيات باستخدام تقنيات Web Scraping لتحليلها واستخدامها في أغراض مختلفة مثل تحسين عمليات التوظيف، فهم اتجاهات سوق العمل، أو تحسين الخدمات الطبية.
خطوات العمل:
تحديد المصادر:
منصات التوظيف: مثل LinkedIn, Indeed, Glassdoor, Bayt, وغيرها.
مواقع المستشفيات: المواقع الرسمية للمستشفيات أو المنصات الطبية التي توفر معلومات عن الوظائف أو الخدمات الطبية.
تحليل الهيكل:
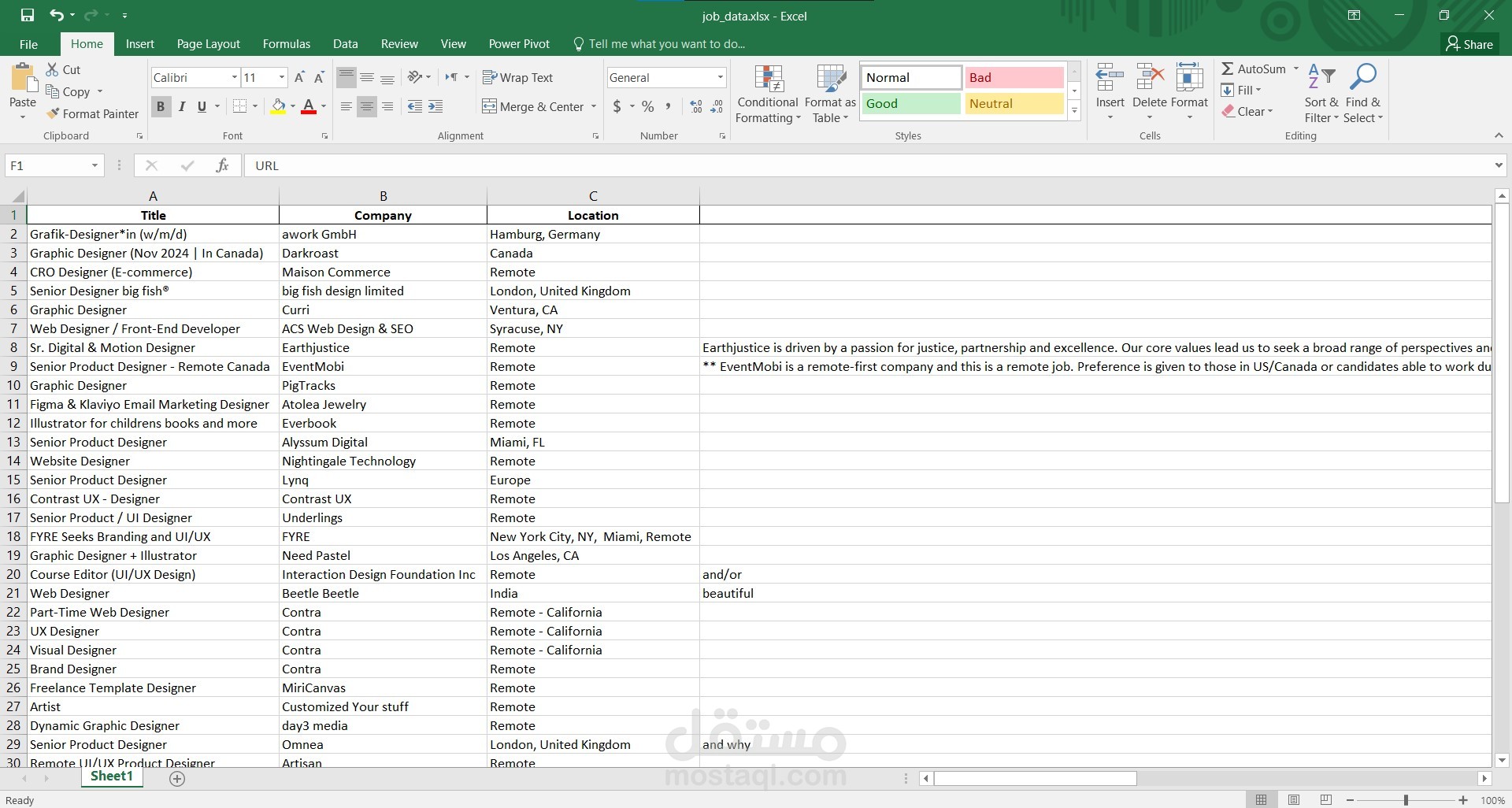
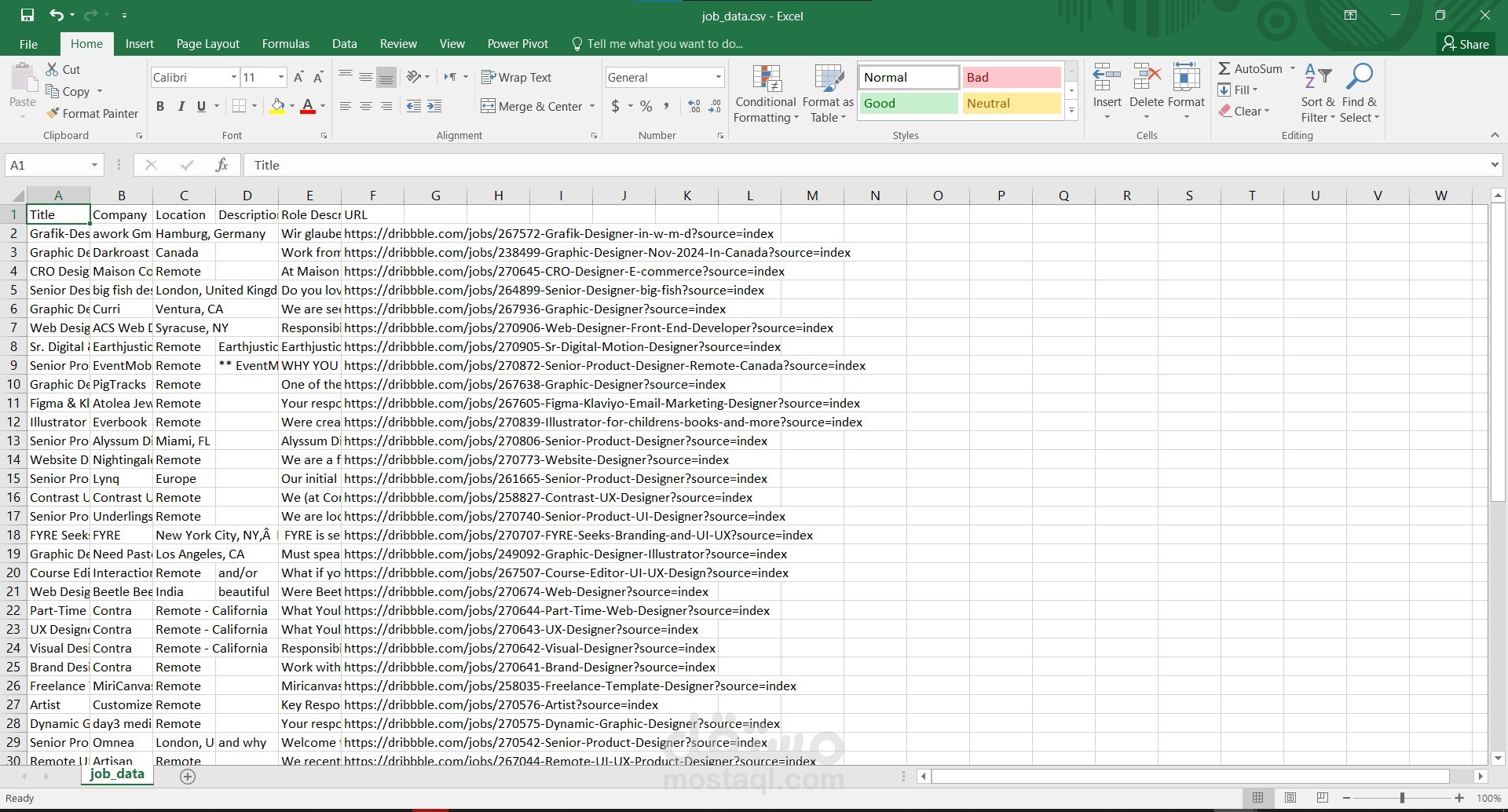
تحليل هيكل صفحات الويب (HTML) لتحديد العناصر التي تحتوي على البيانات المطلوبة مثل:
عناوين الوظائف.
الأوصاف الوظيفية.
المهارات المطلوبة.
الرواتب (إذا كانت متاحة).
معلومات الاتصال.
تفاصيل المستشفيات (العناوين، الخدمات، الوظائف الشاغرة).
تطوير أدوات السحب:
استخدام لغات البرمجة مثل Python مع مكتبات مثل:
BeautifulSoup لتحليل HTML.
Scrapy أو Selenium لسحب البيانات من صفحات ديناميكية.
Pandas لتنظيم البيانات في جداول.
ضمان الامتثال لشروط استخدام المواقع (Terms of Service) لتجنب المشاكل القانونية.
تنفيذ السحب:
كتابة نصوص برمجية (Scripts) لأتمتة عملية سحب البيانات.
التعامل مع الصعوبات مثل:
الحماية ضد الروبوتات (CAPTCHA).
التحميل الديناميكي للبيانات (AJAX).
تغيير هيكل الموقع بشكل دوري.
تنظيف البيانات:
إزالة البيانات المكررة أو غير ذات الصلة.
تصحيح الأخطاء في البيانات المسحوبة.
تنظيم البيانات في صيغة قابلة للتحليل (مثل CSV, JSON, أو قواعد بيانات).
تحليل البيانات:
استخدام أدوات التحليل مثل Excel, Tableau, أو Python لاستخراج رؤى قيمة.
تحديد الاتجاهات في سوق العمل أو الخدمات الطبية.
تقرير النتائج:
تقديم تقارير مفصلة عن البيانات المسحوبة.
تقديم توصيات بناءً على النتائج.
التحديات المحتملة:
الحماية القانونية: بعض المواقع تمنع السحب الآلي للبيانات، لذا يجب التأكد من الامتثال للقوانين.
التحديات الفنية: مثل التغييرات في هيكل الموقع أو الحاجة إلى استخدام بروكسي لتجنب الحظر.
جودة البيانات: قد تكون بعض البيانات غير مكتملة أو غير دقيقة.
الأدوات والتقنيات المقترحة:
لغات البرمجة: Python, JavaScript.
مكتبات: BeautifulSoup, Scrapy, Selenium, Pandas.
أدوات التحليل: Excel, Tableau, Power BI.