تطبيق ذكي لاستخراج البيانات من الويب (Django)
تفاصيل العمل
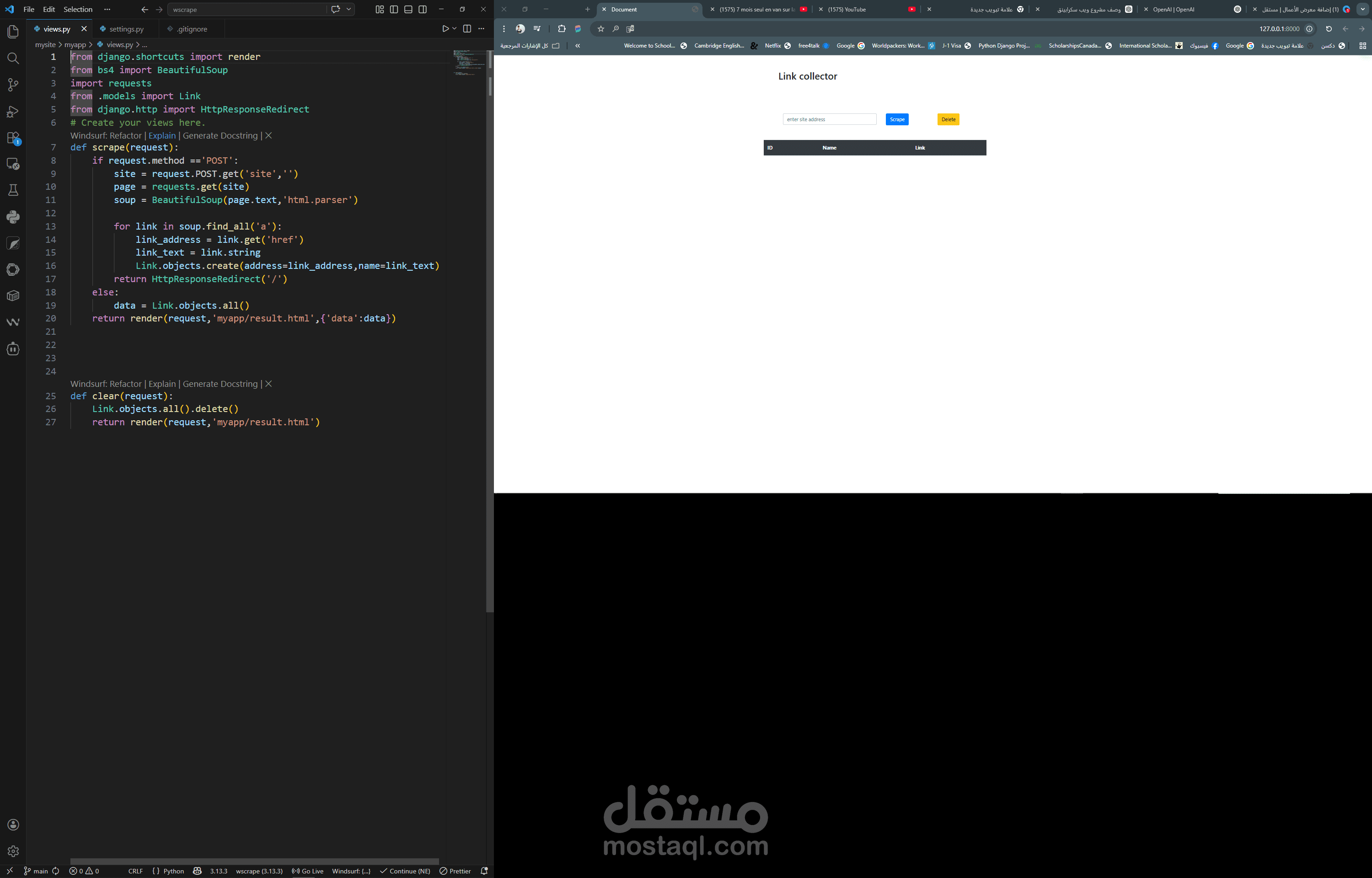
تطبيق ويب متكامل مبني باستخدام Python وإطار العمل Django يهدف إلى أتمتة عمليات Web Scraping بطريقة ذكية وسهلة الاستخدام، حيث يمكّن المستخدم من تحديد الموقع الإلكتروني والبيانات المراد استخراجها دون الحاجة إلى خبرة برمجية.
يعتمد النظام على أحدث أدوات وتقنيات السحب مثل BeautifulSoup و Scrapy و Selenium و Playwright للتعامل مع مختلف أنواع المواقع، بما في ذلك المواقع الديناميكية التي تعتمد على JavaScript.
يوفر التطبيق لوحة تحكم (Dashboard) تفاعلية تمكّن المستخدم من:
إدخال رابط الموقع المستهدف
تحديد نوع البيانات المراد سحبها (نصوص، صور، روابط، جداول...)
استخدام محددات CSS أو XPath لتخصيص عملية الاستخراج
معاينة النتائج قبل التنفيذ
يقوم النظام بتنفيذ عمليات السحب بشكل آلي في الخلفية باستخدام نظام مهام (مثل Celery)، مع إمكانية جدولة العمليات لتعمل بشكل دوري دون تدخل المستخدم.
بعد الانتهاء، يتم:
تنظيف البيانات ومعالجتها
تخزينها في قاعدة بيانات
تصديرها بصيغ متعددة مثل CSV، JSON، Excel حسب اختيار المستخدم
المميزات الرئيسية:
أتمتة كاملة لعمليات جمع البيانات
دعم المواقع الديناميكية والمعقدة
جدولة مهام السحب (Scraping Scheduler)
نظام متعدد المستخدمين مع إدارة صلاحيات
تخزين البيانات باستخدام قواعد بيانات مثل PostgreSQL
تصدير البيانات بعدة صيغ
واجهة استخدام سهلة وتجربة مستخدم احترافية
قابلية التوسع وربط APIs خارجية
التقنيات المستخدمة (Tech Stack):
Backend: Python, Django
Scraping Tools: BeautifulSoup, Scrapy, Selenium, Playwright
Task Queue: Celery + Redis
Database: PostgreSQL
Frontend: HTML, CSS, JavaScript