Titanic Survival Prediction – A Comprehensive End-to-End Machine Learning Analysis
تفاصيل العمل

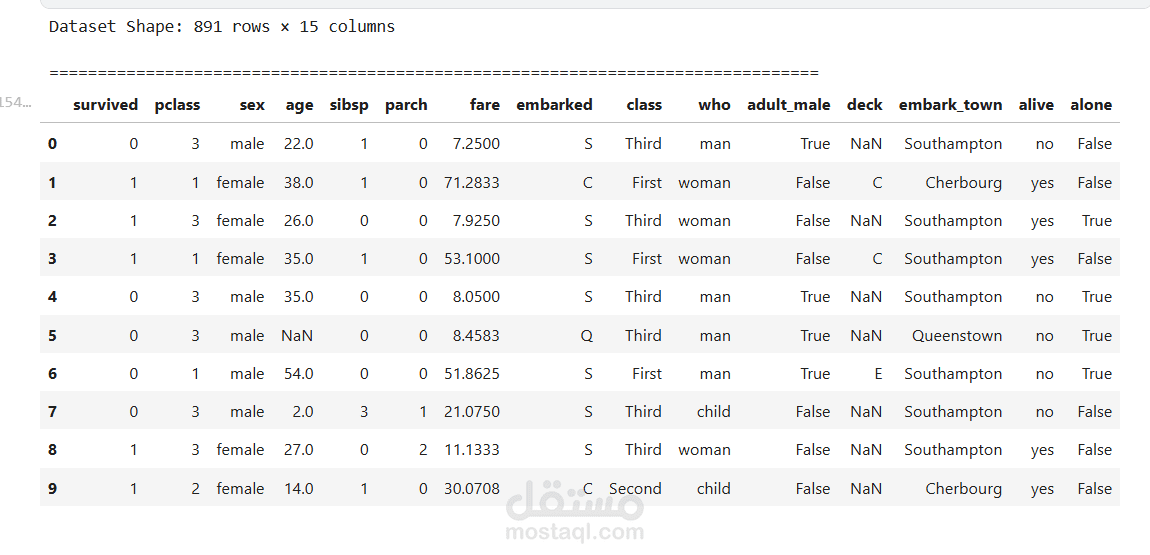
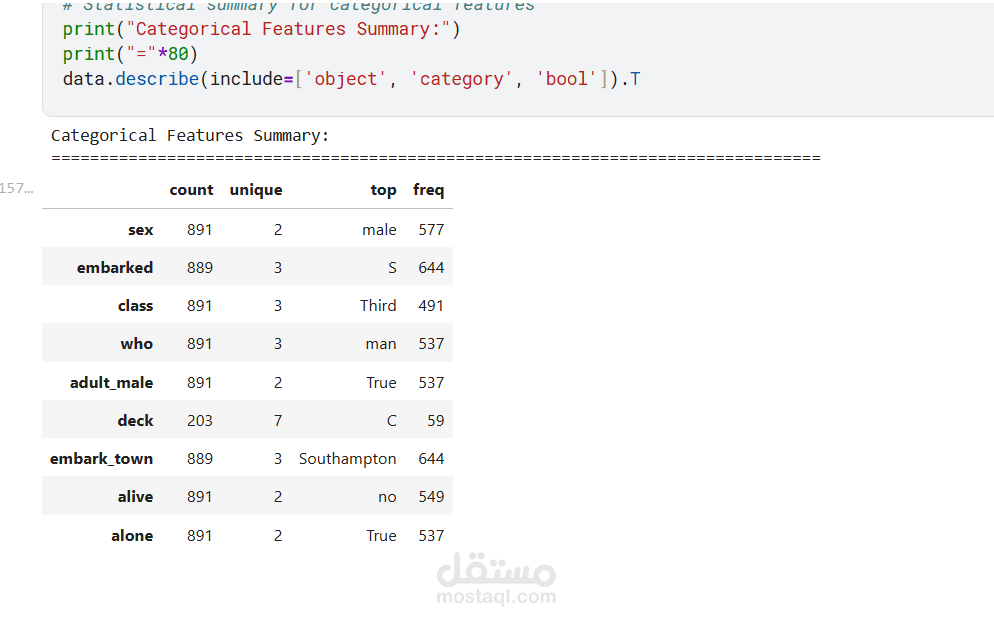
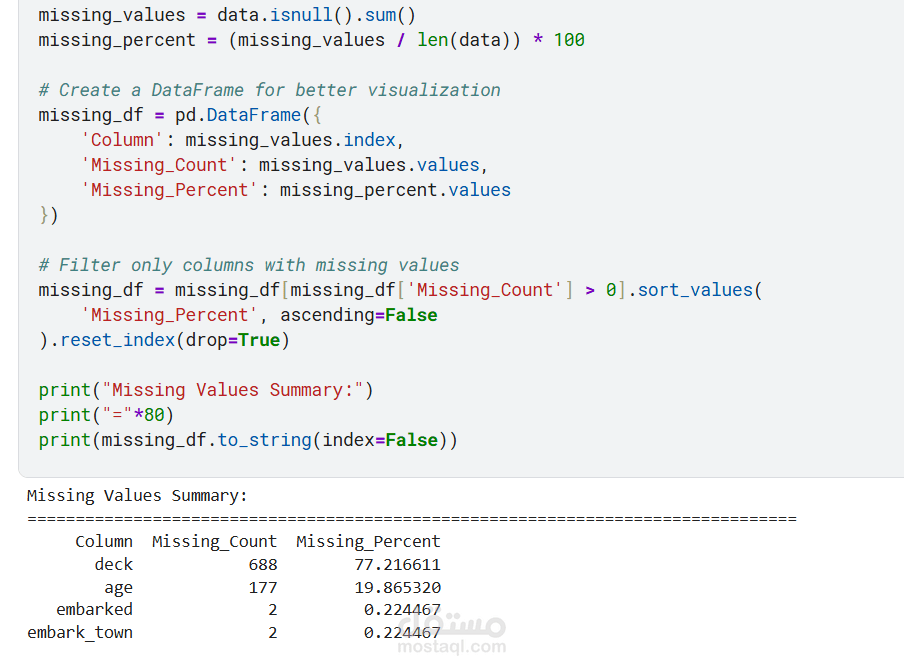
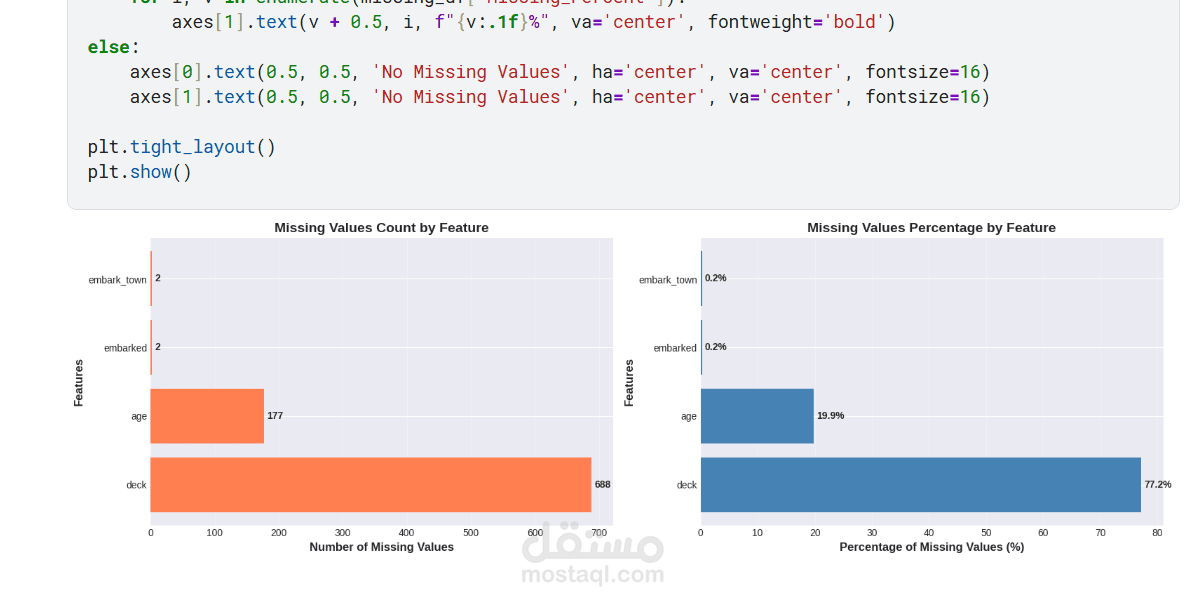
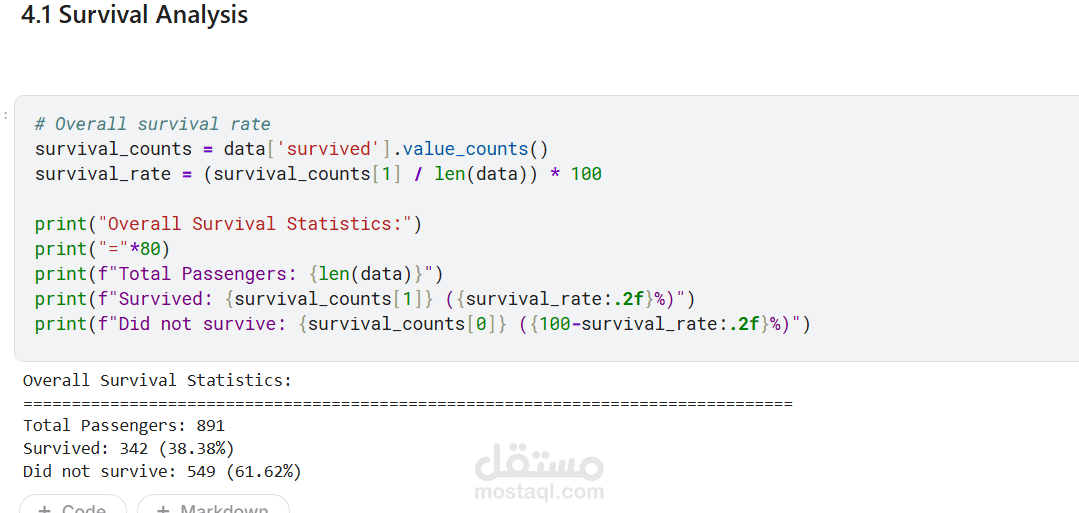
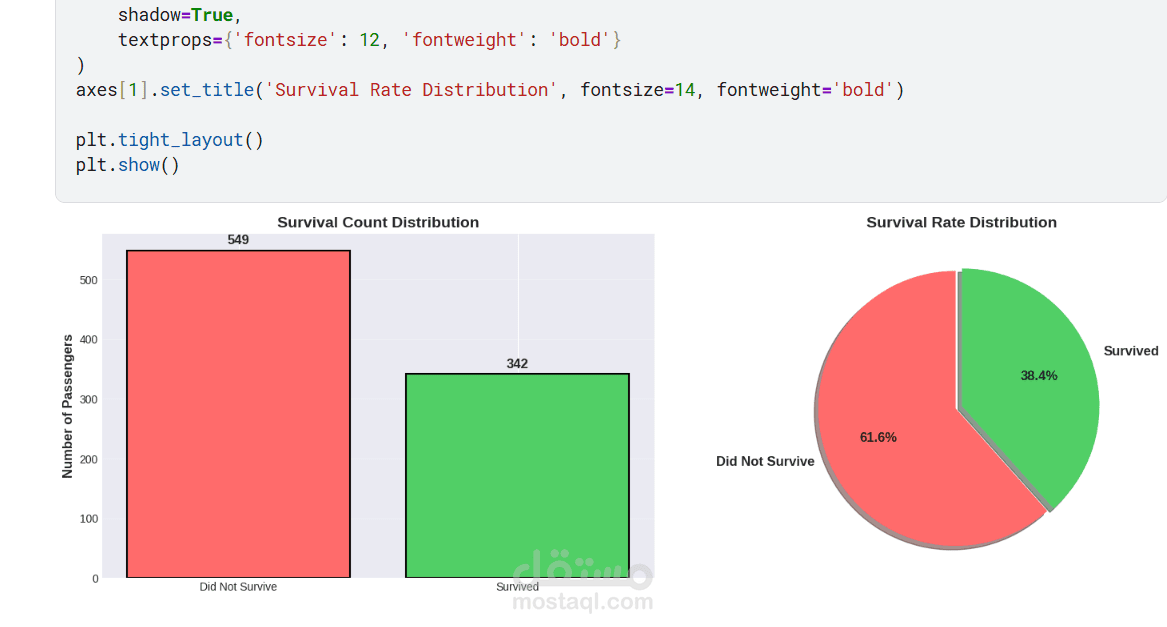
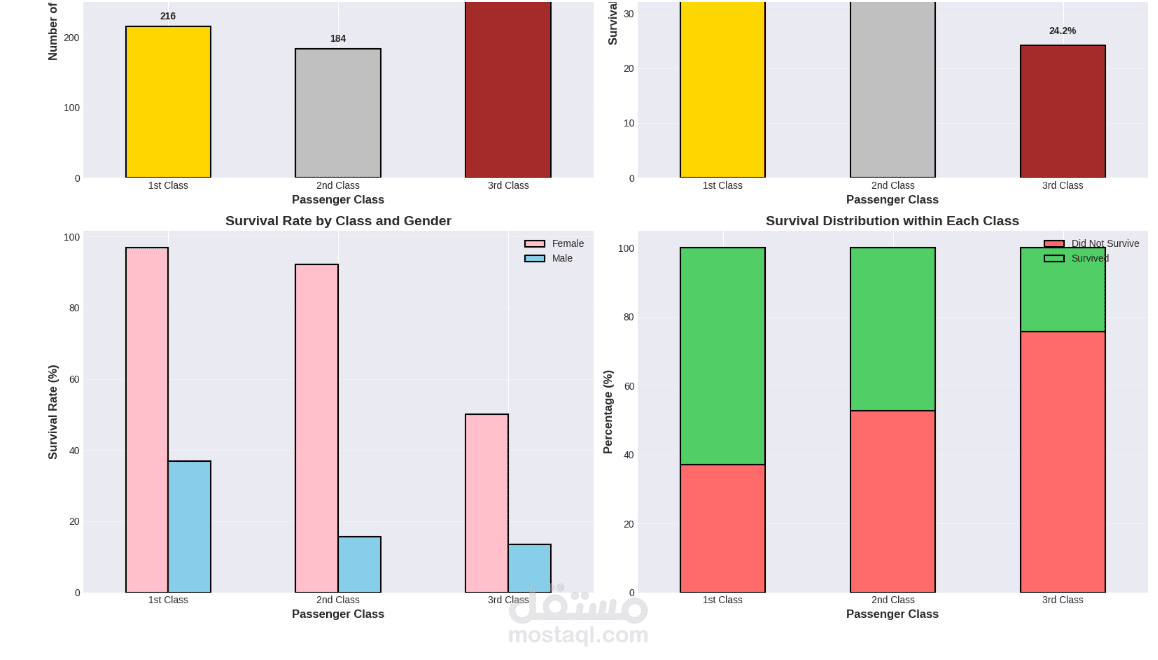
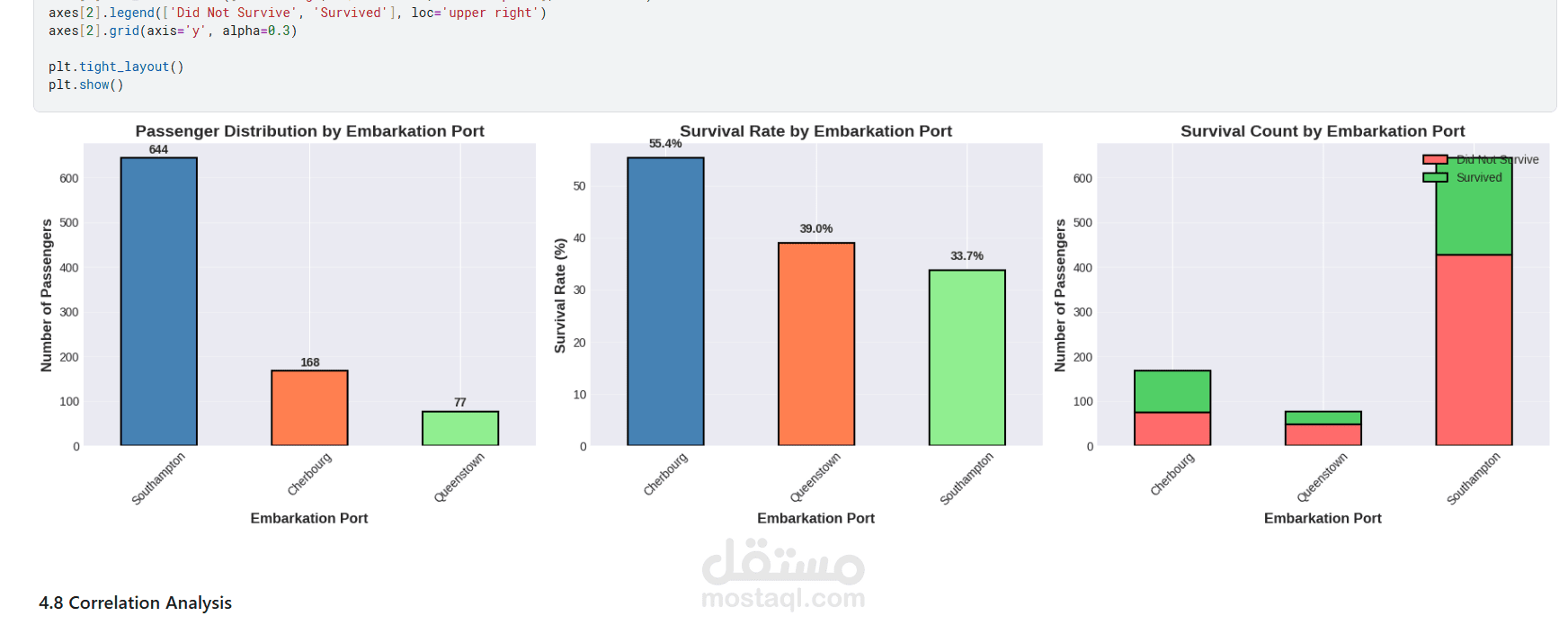
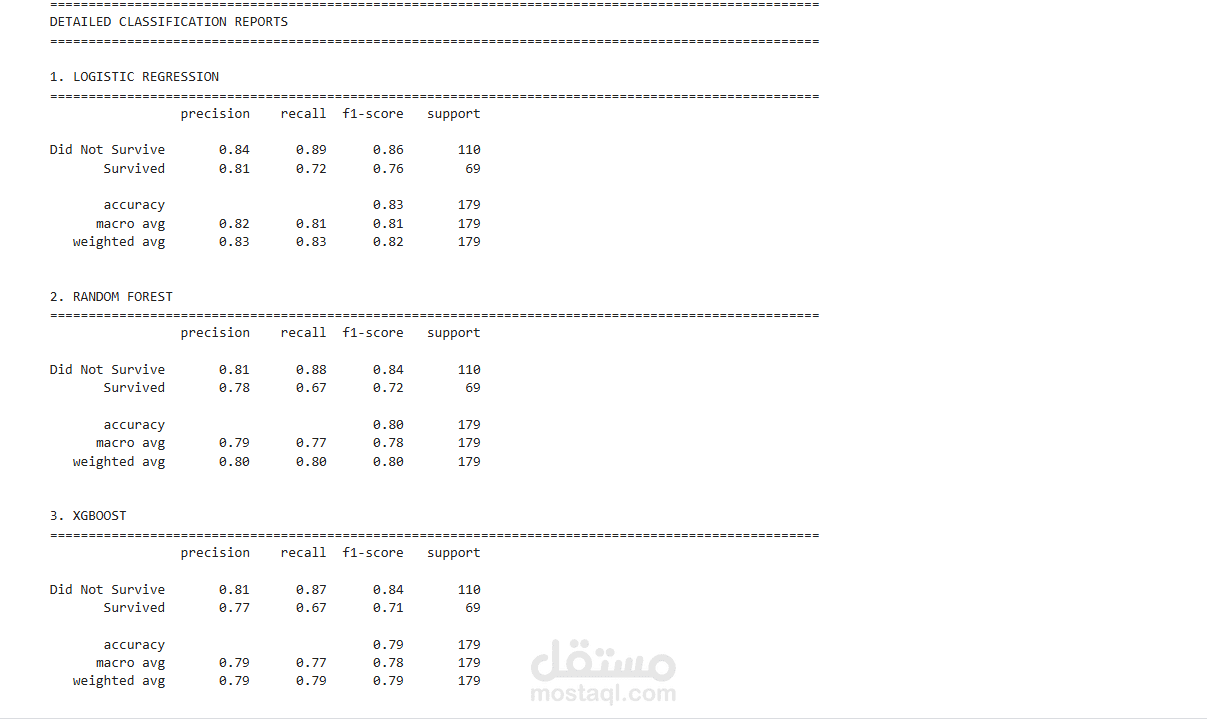

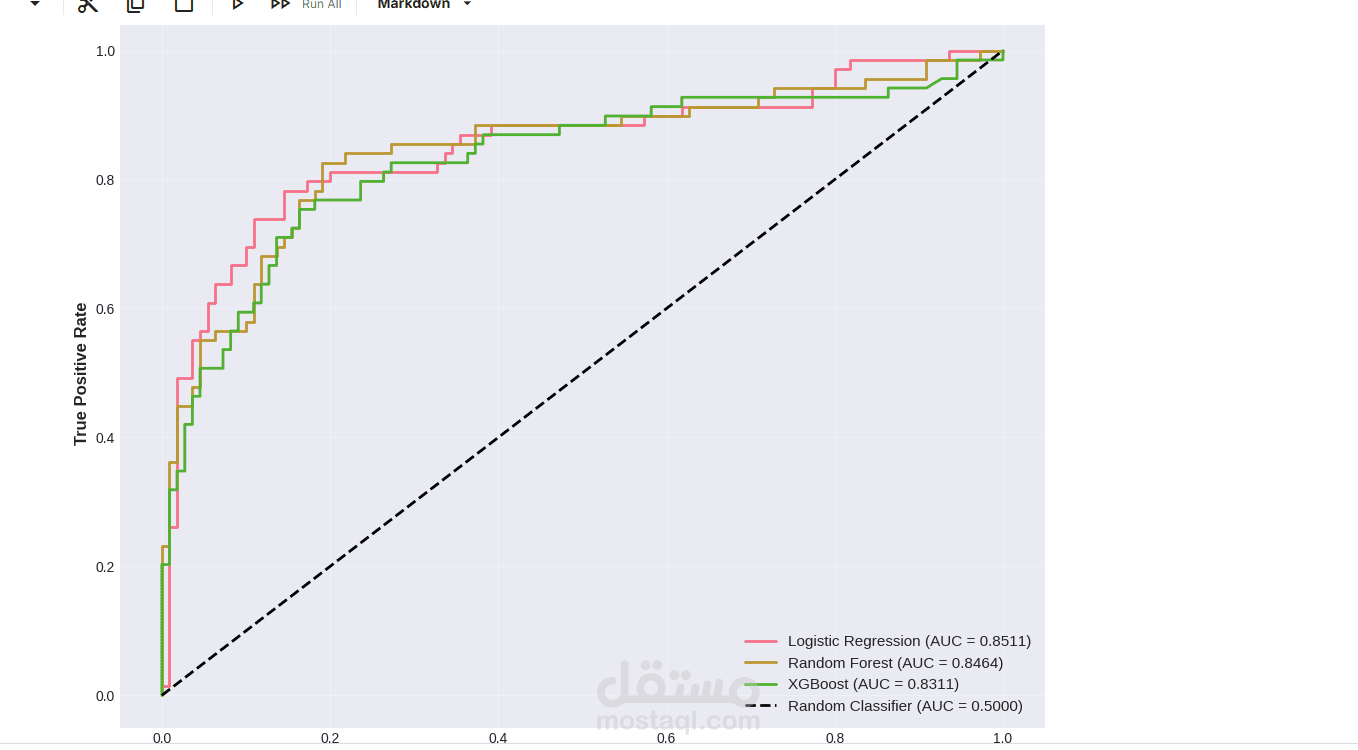
يقدم هذا المشروع تحليلاً كاملاً ومتكاملاً للبيانات للتنبؤ بنجاة ركاب تيتانيك باستخدام تقنيات تعلم الآلة. يبدأ المشروع باستكشاف البيانات وتحليلها (EDA) لاكتشاف الأنماط المؤثرة مثل الجنس، درجة السفر، العمر، حجم العائلة، وقيمة التذكرة. تمت معالجة القيم المفقودة بعناية، وهندسة ميزات جديدة (مثل حجم العائلة، السعر لكل فرد، والفئات العمرية) لتحسين أداء النماذج. بعد ترميز المتغيرات الفئوية وتقسيم البيانات، تم تدريب ثلاثة نماذج: الانحدار اللوجستي، الغابة العشوائية، و XGBoost، ثم مقارنتها باستخدام مقاييس الدقة، الاستدعاء، الدقة، F1‑score، و ROC‑AUC. يوضح التحليل أهمية الميزات ويقدم رؤى قابلة للتطبيق، مع تحقيق أداء عالٍ يتجاوز 80% من الدقة. المشروع عبارة عن قالب متكامل وقابل لإعادة الاستخدام لمهام التصنيف الثنائي.