استخراج بيانات المواقع الضخمة وتحويلها إلى تقارير Excel احترافية.
تفاصيل العمل
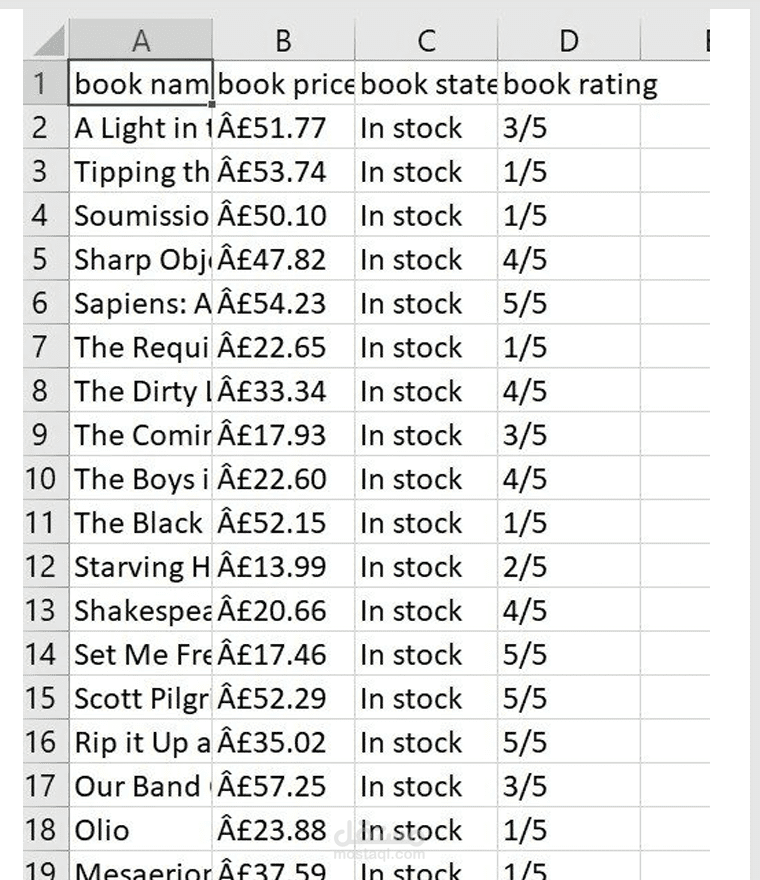
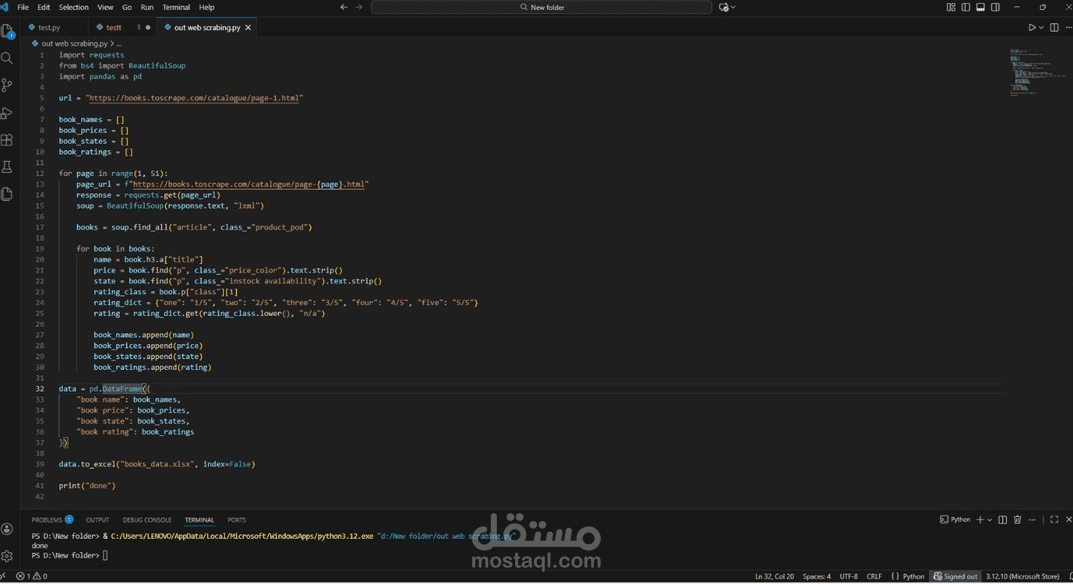
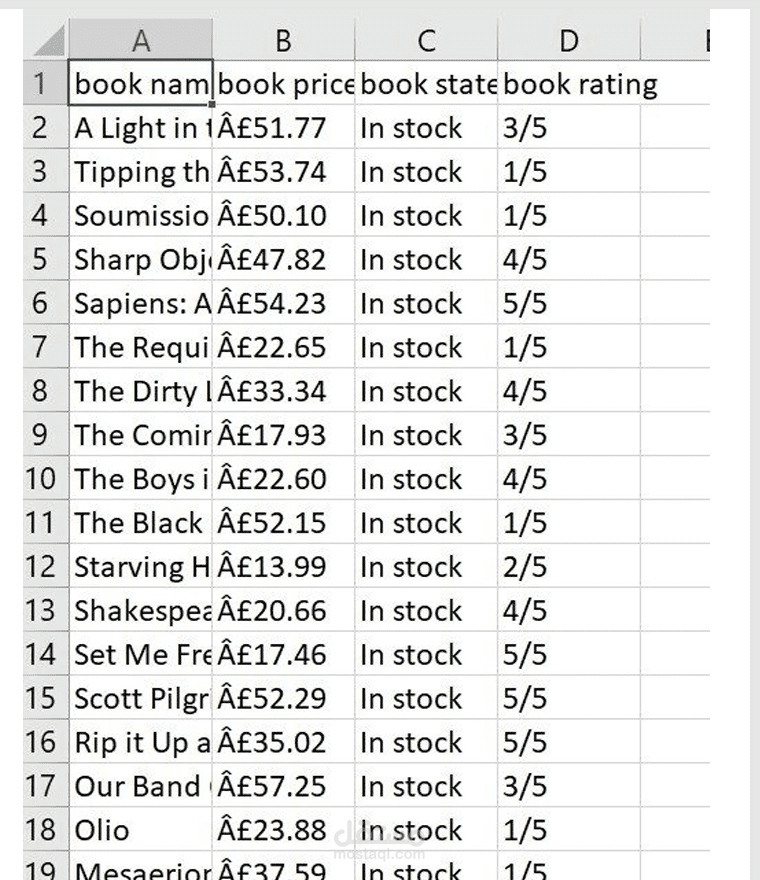
قمت بتطوير أداة متكاملة باستخدام لغة Python مخصصة لاستخراج البيانات (Data Extraction) من المواقع الإلكترونية بشكل آلي ومنظم. الأداة قادرة على تصفح صفحات متعددة واستخلاص المعلومات بدقة عالية وتحويلها إلى ملفات إكسيل جاهزة للتحليل.المميزات التقنية التي تم تنفيذها في المشروع:تصفح الصفحات المتعددة (Pagination): الكود مبرمج ليمر آلياً عبر 50 صفحة مختلفة لجمع مئات المنتجات دون تدخل بشري.استخراج بيانات دقيقة: يقوم النظام بسحب أربعة عناصر أساسية لكل منتج (اسم الكتاب، السعر، حالة التوفر، والتقييم).معالجة البيانات (Data Cleaning): يتم تحويل التقييمات النصية (مثل "Three") إلى قيم رقمية أو نسب مئوية (مثل "3/5") لتسهيل التحليل الإحصائي لاحقاً.تصدير البيانات: يتم تنظيم البيانات في "Dataframe" باستخدام مكتبة Pandas وتصديرها مباشرة إلى ملف Excel احترافي باسم books_data.xlsx.النتائج المحققة:نجاح استخراج بيانات كتب متنوعة مثل (Sapiens, Sharp Objects, وغيرها) مع تفاصيلها الكاملة.الحصول على قائمة منظمة تشمل الأسعار وحالة التوفر في المخزن (In stock) لكل منتج.إنتاج ملف بيانات نظيف وخالي من الأخطاء وجاهز للاستخدام في تطبيقات دراسة السوق.التقنيات المستخدمة:Requests: لإرسال الطلبات للموقع وجلب محتوى الصفحات.BeautifulSoup: لتحليل كود HTML واستخراج البيانات المطلوبة.Pandas: لإدارة الجدولة وتصدير البيانات إلى ملفات Excel.LXML: لسرعة معالجة وتحليل البيانات.