PySpark Data Processing Portfolio
تفاصيل العمل
يهدف هذا المشروع إلى توضيح أساسيات معالجة وتحليل البيانات الضخمة باستخدام لغة Python وإطار العمل Apache Spark (PySpark). يركز المشروع على تطبيق بعض العمليات الأساسية في تحليل البيانات مثل قراءة البيانات، معالجتها، تصفيتها، وإجراء عمليات التجميع والتحليل باستخدام قدرات المعالجة الموزعة التي يوفرها Spark.
يتكون المشروع من ثلاثة أمثلة تطبيقية بسيطة:
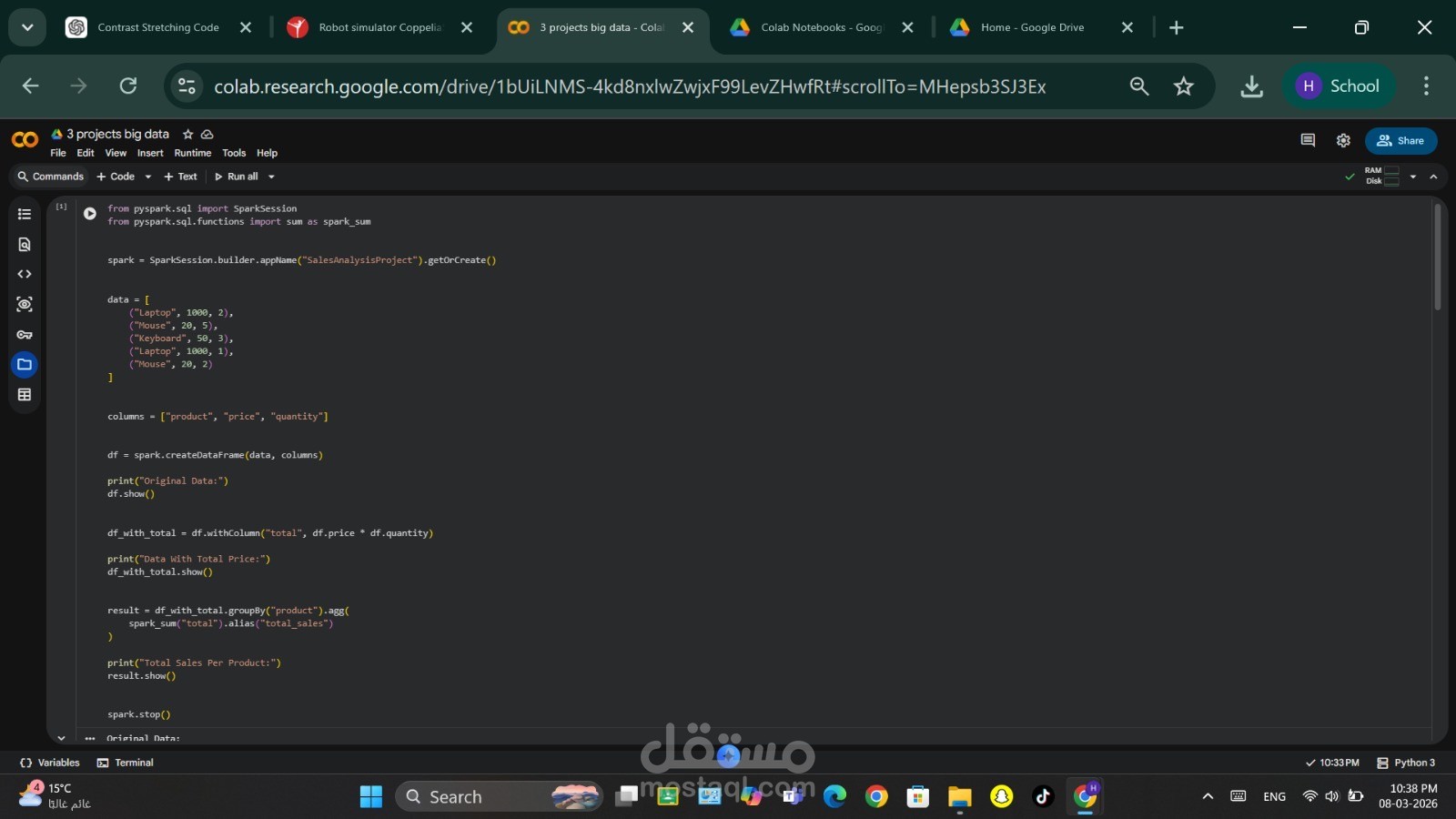
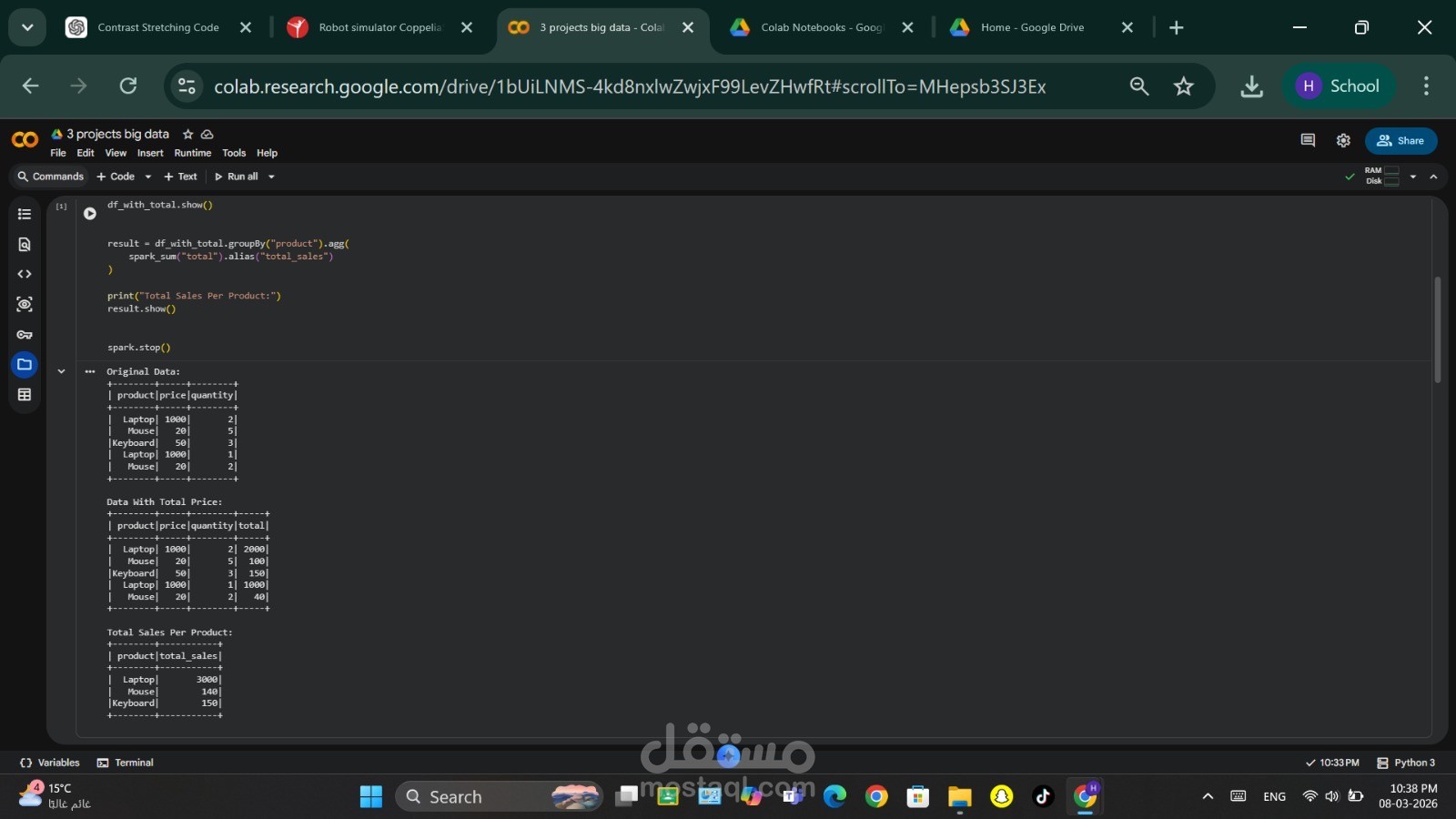
1. تحليل بيانات المبيعات
يقوم هذا الجزء بتحليل بيانات مبيعات بسيطة وحساب إجمالي المبيعات لكل منتج باستخدام عمليات DataFrame في Spark وعمليات التجميع (Aggregation).
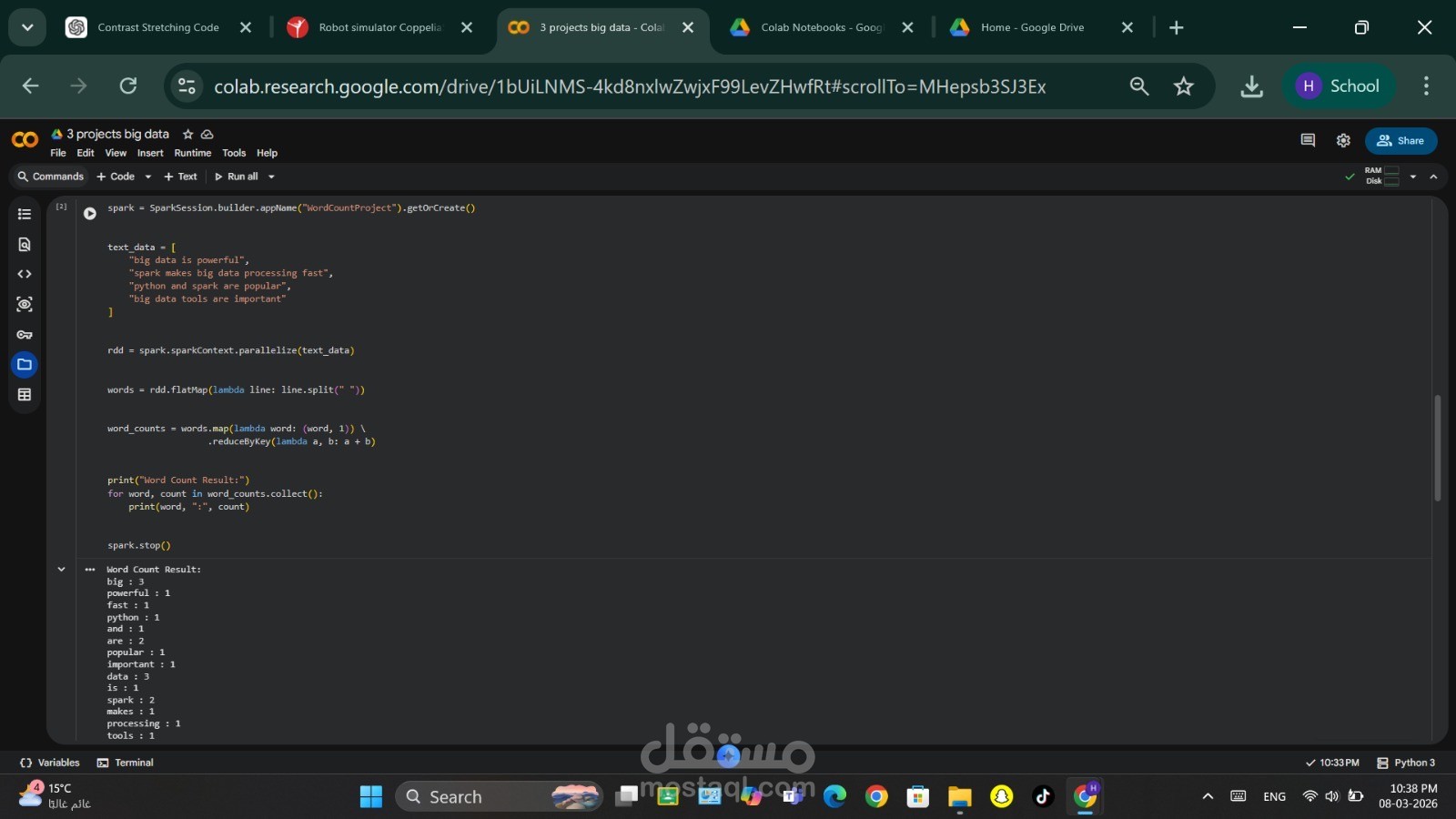
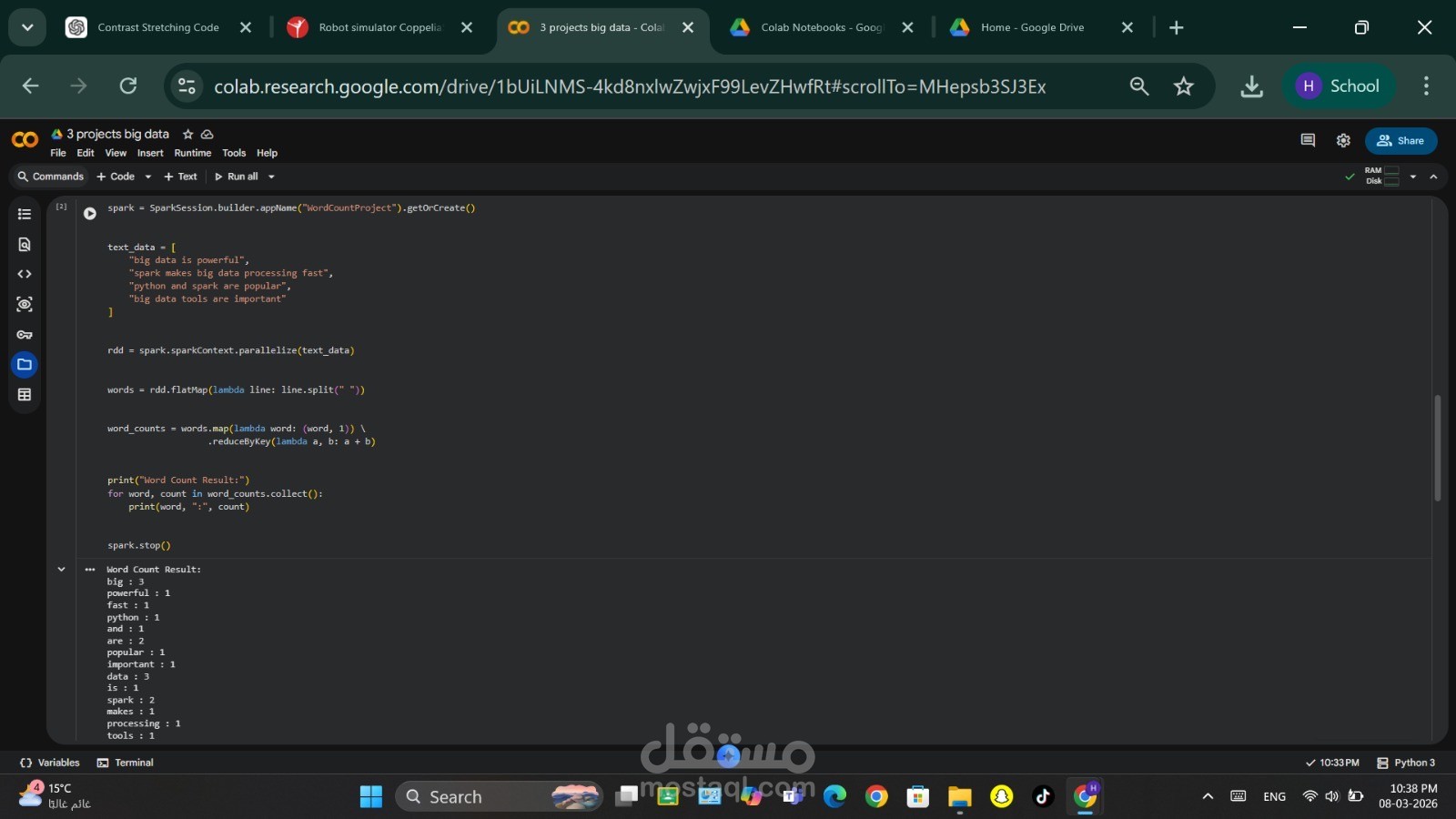
2. حساب تكرار الكلمات (Word Count)
وهو أحد أشهر الأمثلة في مجال البيانات الضخمة، حيث يتم تحليل نص معين وحساب عدد مرات تكرار كل كلمة باستخدام عمليات RDD مثل flatMap و reduceByKey.
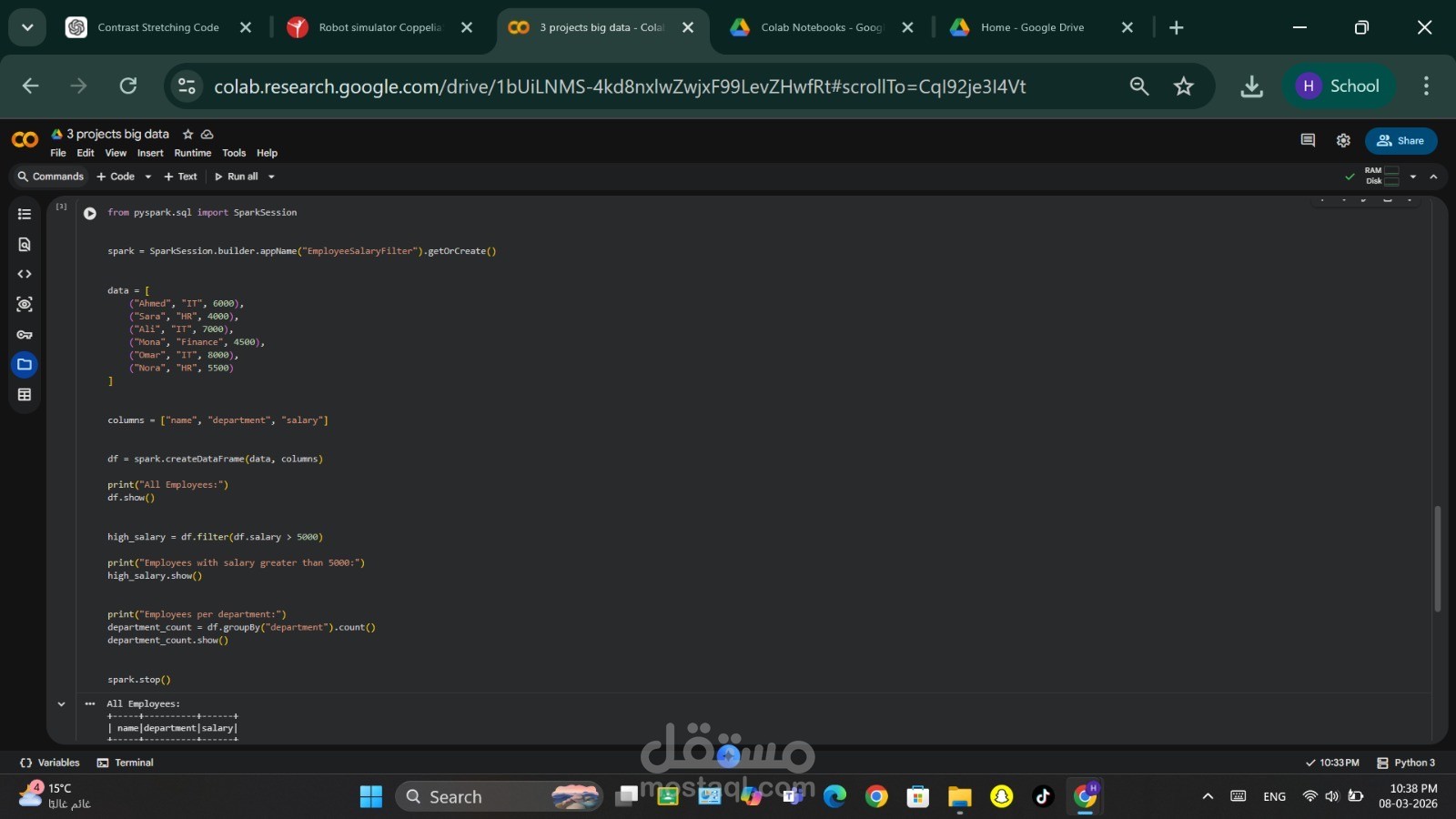
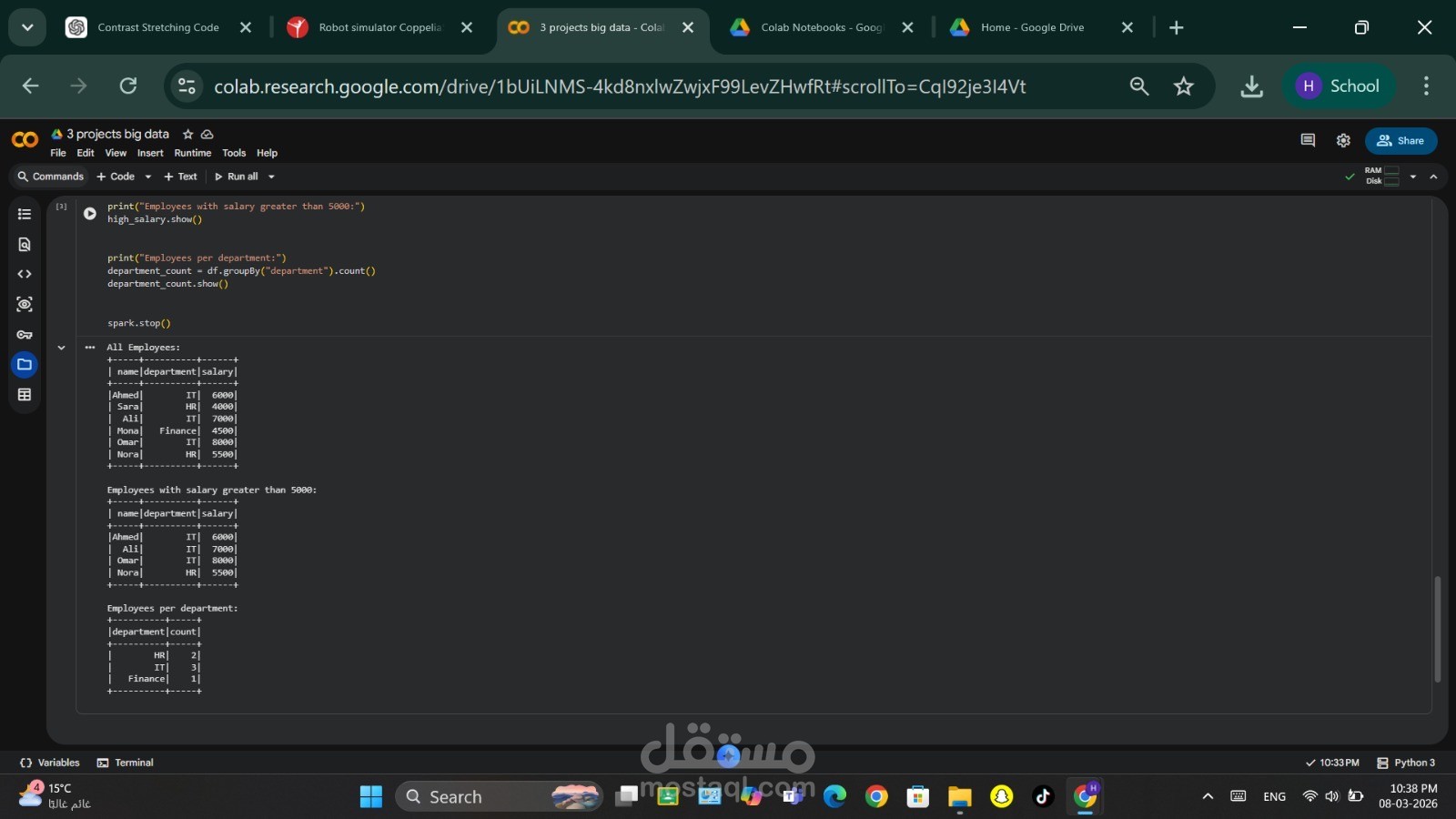
3. تصفية بيانات الموظفين
يقوم هذا المثال بمعالجة بيانات موظفين واستخراج الموظفين الذين تزيد رواتبهم عن قيمة معينة، بالإضافة إلى إجراء تحليل بسيط مثل حساب عدد الموظفين في كل قسم.
يهدف هذا المشروع إلى إظهار فهم أساسيات العمل باستخدام Spark مثل:
* إنشاء Spark Session
* التعامل مع DataFrames و RDDs
* تصفية البيانات (Filtering)
* إجراء عمليات التحويل والتحليل على البيانات
* استخدام عمليات التجميع والتجميع حسب الفئات (Grouping)
ويُعد هذا المشروع خطوة أساسية لبناء فهم عملي لمفاهيم تحليل البيانات الضخمة باستخدام PySpark وتطبيقها على أمثلة تحاكي سيناريوهات تحليل بيانات حقيقية.