نموذج ذكاء اصطناعي لتحليل المشاعر (Sentiment Analysis) باستخدام شبكات LSTM.
تفاصيل العمل
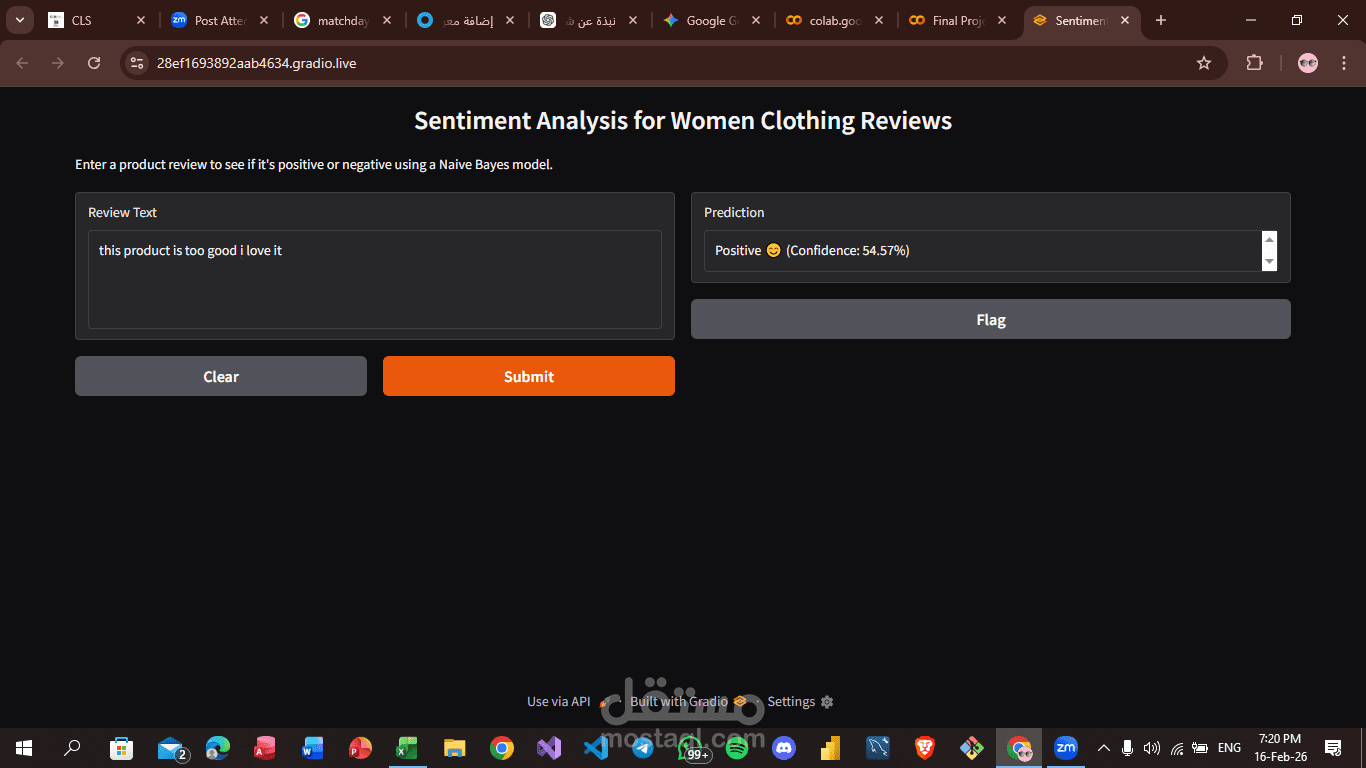
قمت بتطوير نموذج تعلم عميق (Deep Learning) متخصص في معالجة اللغات الطبيعية (NLP) لتصنيف النصوص وتحليل الآراء بدقة عالية، سواء كانت إيجابية، سلبية، أو محايدة.
أبرز ما قمت به في المشروع:
معالجة النصوص (Text Pre-processing): قمت بتنظيف البيانات النصية وإجراء عمليات الـ Tokenization والـ Padding لتحويل النصوص إلى صيغة رقمية يفهمها النموذج.
بناء وتطوير النموذج: استخدمت بنية متطورة تعتمد على شبكات LSTM (Long Short-Term Memory) لقدرتها العالية على فهم السياق في الجمل الطويلة.
تدريب وتحسين الأداء: تم تدريب النموذج على مدار 15 دورة (Epochs) مع استخدام تقنية Early Stopping لتفادي الـ Overfitting، مما أدى لتقليل نسبة الخطأ (Loss) إلى 0.692.
تحليل النتائج: النموذج قادر على التنبؤ بمشاعر المستخدمين بدقة، مما يساعد الشركات على فهم آراء عملائهم وتحسين جودة خدماتهم بناءً على ردود الأفعال.