نظام ذكاء اصطناعي واحد… يرى كل بياناتك، ويفهمها، ويُحدّث نفسه بنفسه.
تفاصيل العمل
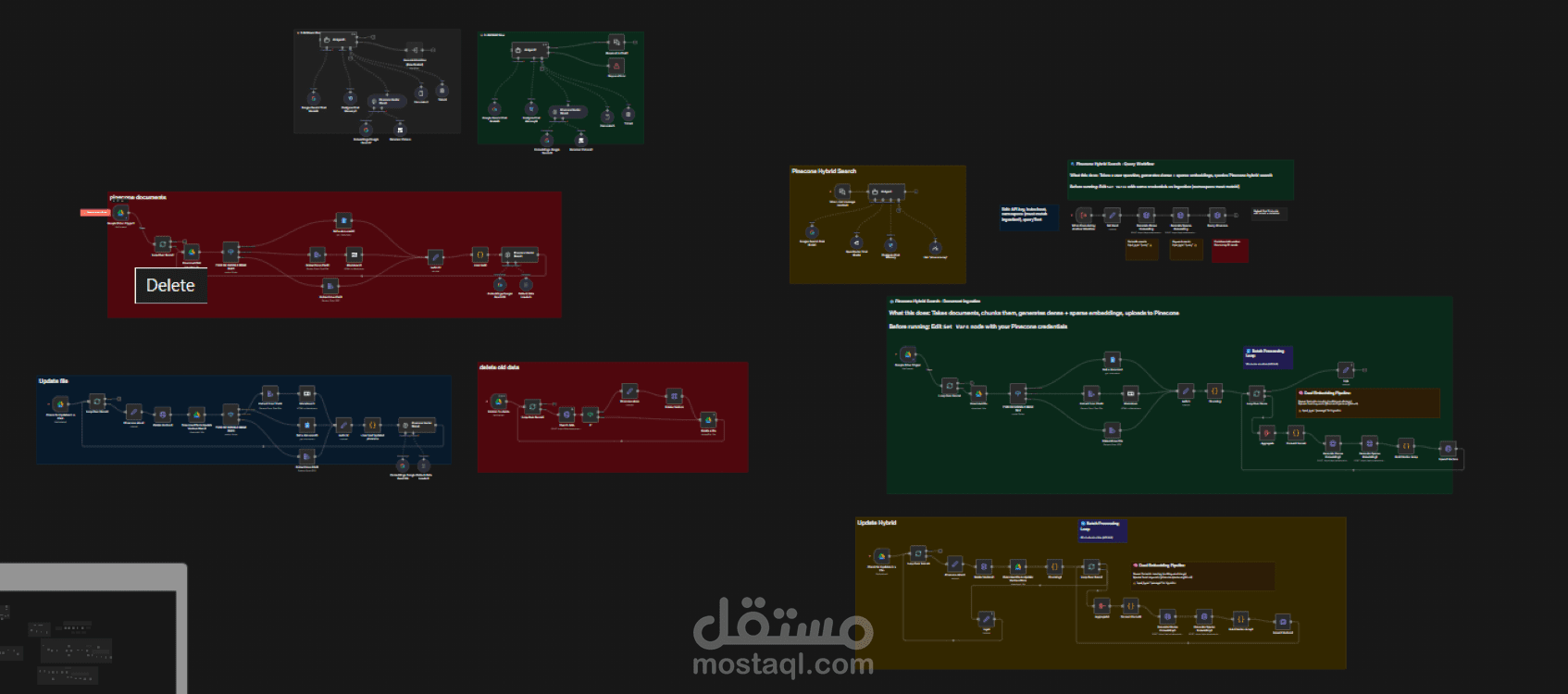
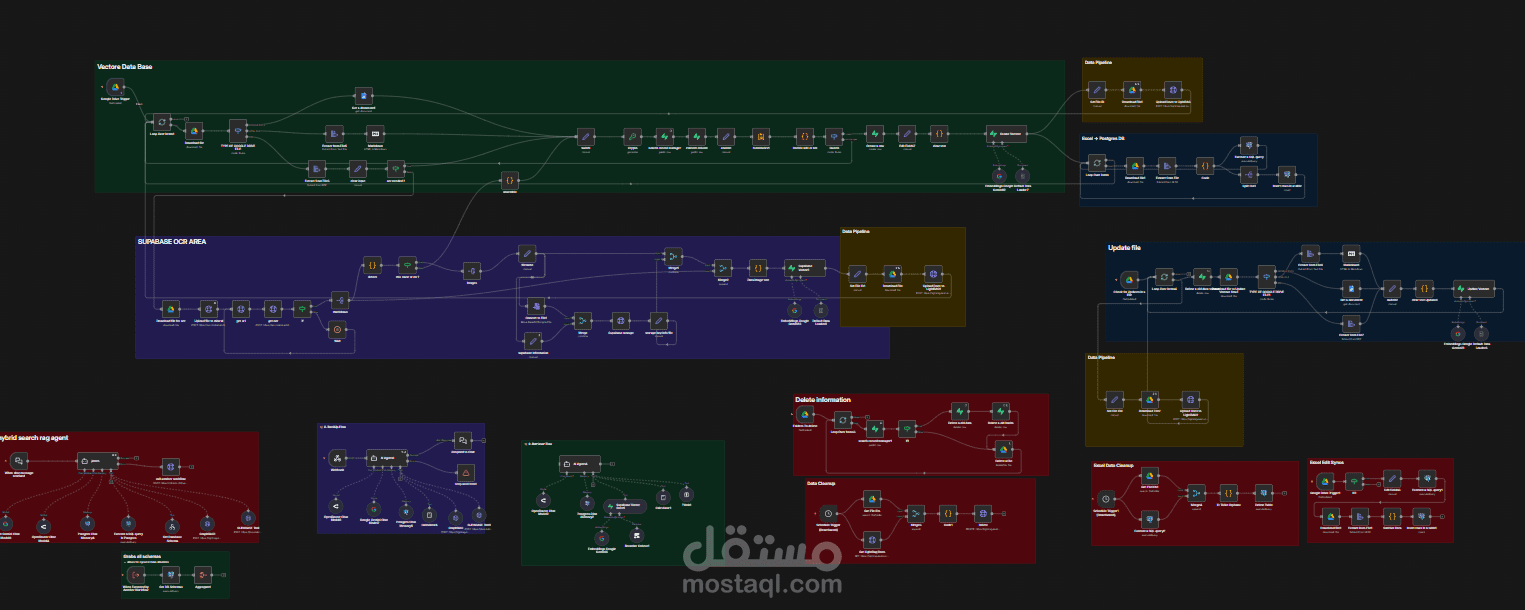
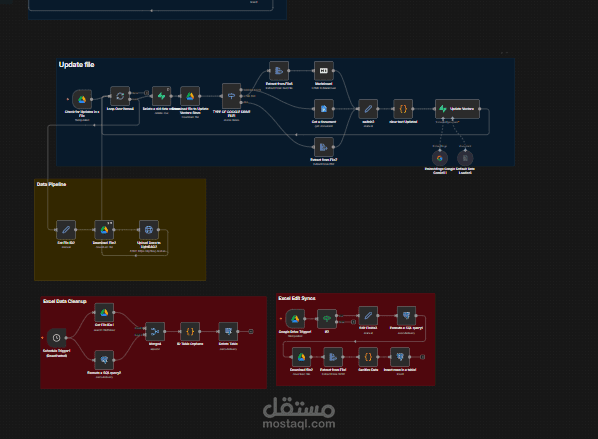
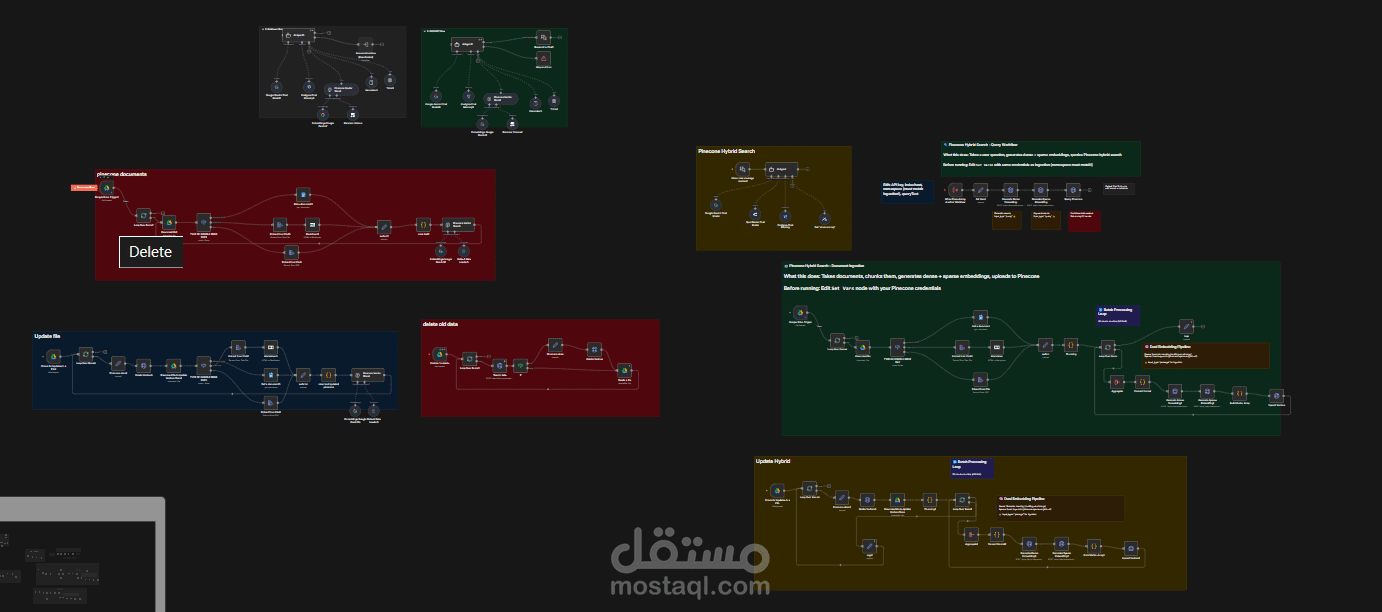
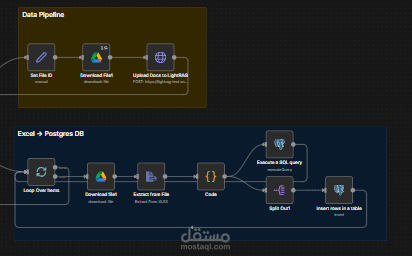
كان الهدف بناء نظام ذكاء اصطناعي قادر على الإجابة عن أي سؤال يتعلق ببيانات الشركة بالكامل —
سواء كانت:
ملفات Excel وGoogle Sheets
مستندات PDF وWord
ملفات ممسوحة ضوئيًا أو صور
وذلك بدون أي صيانة يدوية عند إضافة أو تعديل الملفات.
? ماذا بنيت؟
قمتُ بتصميم وتنفيذ Agentic RAG Production System داخل n8n يجمع ثلاثة محركات استرجاع في وكيل ذكي واحد:
? 1) LightRAG (GraphRAG)
يبني مخطط معرفة حي من المستندات، ما يسمح للنظام بفهم العلاقات بين البيانات عبر ملفات متعددة.
النتيجة؟
إجابات مبنية على السياق والعلاقات، وليس مجرد بحث كلمات أو تشابه متجهات.
الفائدة:
تحليل أعمق
استنتاجات مترابطة
فهم سياقي لا يستطيع البحث التقليدي تقديمه
? 2) SQL RAG
يقوم تلقائيًا باستيراد بيانات Excel وGoogle Sheets إلى قاعدة Supabase PostgreSQL، ثم يُنشئ استعلامات SQL بالذكاء الاصطناعي للحصول على إجابات دقيقة رياضيًا.
الفائدة:
أرقام دقيقة 100%
لا أخطاء تقريبية
تقارير مالية وتحليل بيانات موثوق
? 3) Hybrid Vector Search + Cohere Reranker
بحث دلالي + كلمات مفتاحية مع إعادة ترتيب دقيقة قبل تمرير النتائج إلى Gemini 2.
الفائدة:
تقليل الهلوسة
إجابات أكثر دقة
اختيار أفضل السياقات فقط
? OCR Pipeline
أي ملف PDF ممسوح أو صورة يتم معالجته تلقائيًا قبل الفهرسة.
الفائدة:
لا توجد ملفات "غير قابلة للبحث" بعد الآن.
? Auto Sync مع Google Drive
النظام يراقب Google Drive باستمرار:
الملفات الجديدة يتم إدخالها تلقائيًا
الملفات المعدّلة يتم إعادة معالجتها
الملفات المحذوفة يتم حذفها من جميع مخازن البيانات
الفائدة الكبرى:
قاعدة معرفة تُحدّث نفسها تلقائيًا بدون أي تدخل بشري.
? النتيجة
✔ قاعدة معرفة ذكية ذاتية الصيانة
✔ توجيه تلقائي لكل سؤال إلى محرك الاسترجاع المناسب
✔ تقليل التكاليف التشغيلية
✔ جاهز للنشر كـ n8n JSON Workflow قابل للنقل
✔ قابل للتوسع لأي حجم بيانات
? لماذا هذا حل مثالي؟
بدلاً من أن يكون لديك:
نظام بحث منفصل
قاعدة بيانات منفصلة
OCR منفصل
تحديث يدوي
أخطاء عند تغيير الملفات
تحصل على عقل رقمي موحد يدير كل ذلك تلقائيًا.
هذا ليس مجرد RAG تقليدي…
بل نظام Agentic يتخذ قرارًا ذكيًا حول كيف يجيب قبل أن يجيب.