توقع مخاطر الإصابة بأمراض القلب باستخدام تقنيات تعلم الآلة (Heart Failure Prediction)
تفاصيل العمل
أبرز ما قمت به في المشروع:
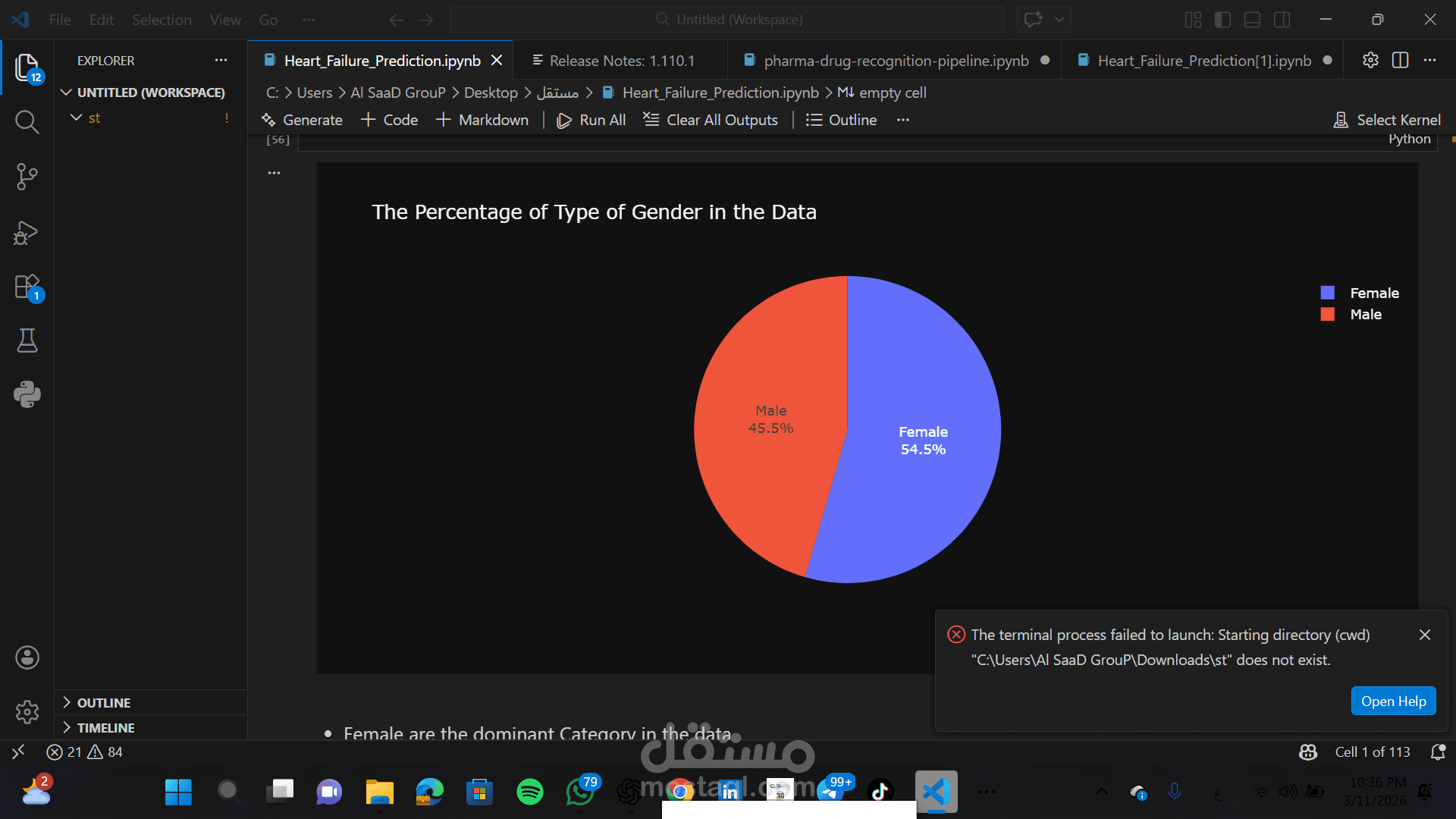
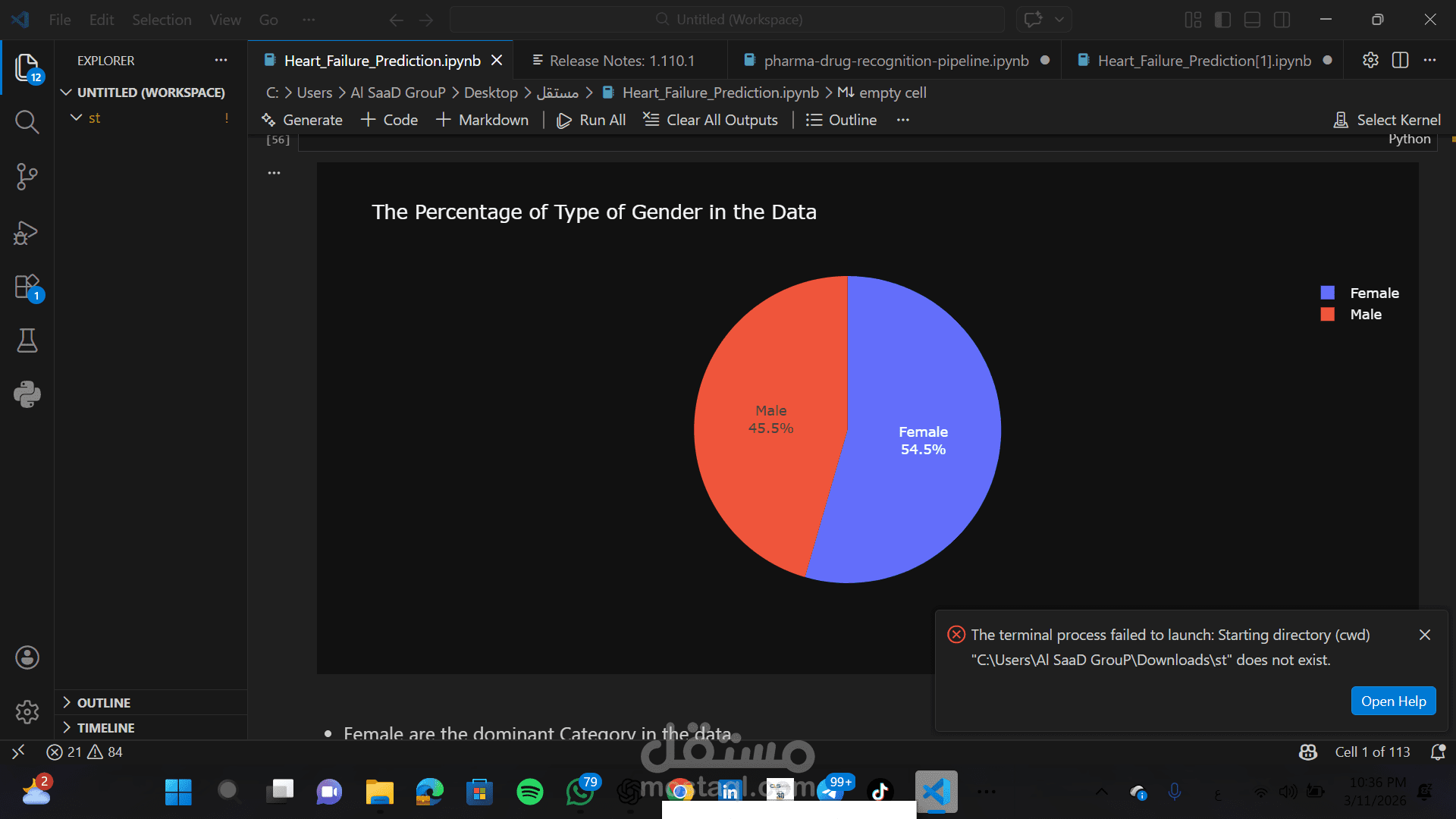
استكشاف وتحليل البيانات (EDA): استخدام مكتبات Matplotlib و Seaborn و Plotly لعمل رسوم بيانية تفاعلية لفهم توزيع الأعمار والعوامل الصحية.
تنظيف البيانات (Data Pre-processing): التعامل مع القيم المكررة (Duplicated rows)، وفحص القيم المفقودة (Null values)، ومعالجة القيم الشاذة (Outliers).
هندسة الميزات (Feature Engineering): تجهيز البيانات وتوسيمها لتناسب خوارزميات التصنيف.
بناء النماذج وتدريبها: قمت بتجربة عدة خوارزميات مثل (Random Forest, Logistic Regression, Decision Tree, KNN).
النموذج الأفضل: تفوق نموذج XGBoost محققاً دقة فائقة (Accuracy) ونسبة استدعاء (Recall) بلغت 99%.
تصدير النموذج: حفظ النموذج النهائي بصيغة .pkl باستخدام مكتبة joblib ليكون جاهزاً للدمج في تطبيقات الويب أو الموبايل.
الأدوات المستخدمة:
Python, Pandas, NumPy, Scikit-learn, XGBoost, Plotly, Seaborn."