نظام تصنيف قبول السيارات باستخدام Support Vector Machine (SVM)
تفاصيل العمل

في هذا المشروع، قمت ببناء نموذج تعلم آلي خاضع للإشراف (Supervised Learning) قادر على تصنيف السيارات إلى أربع فئات بناءً على مدى قبولها: غير مقبولة (unacc)، مقبولة (acc)، جيدة (good)، ممتازة (vgood).
استخدمت مجموعة البيانات الشهيرة Car Evaluation Dataset من UCI Machine Learning Repository، والتي تحتوي على 1728 سيارة (صف) و6 خصائص (أعمدة) تصف كل سيارة.
1. تجهيز البيانات (Preprocessing)
قراءة البيانات: تم تحميل ملف CSV وتنظيف أسماء الأعمدة من المسافات الزائدة.
تشفير الفئات (Encoding): بدلاً من استخدام LabelEncoder الافتراضي، قمت بإنشاء maps يدوي لكل عمود للتحكم الكامل في التشفير:
إزالة القيم المفقودة: التأكد من عدم وجود null values.
فصل الميزات عن الهدف: X = df.drop('class', axis=1) و y = df['class'].
توحيد المقاييس (Standardization): استخدام StandardScaler لأن SVM حساس لنطاق القيم.
تقسيم البيانات: 80% تدريب و20% اختبار مع الحفاظ على توزيع الفئات (stratify=y).
2. تجربة وتدريب النموذج
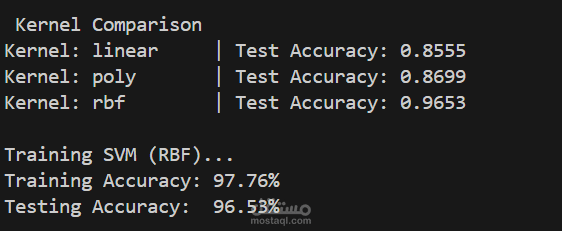
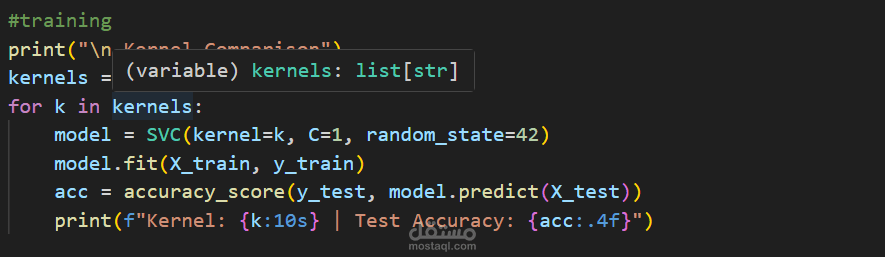
قمت بتجربة 3 أنواع من دوال kernel في SVM:
النتيجة: kernel = RBF أعطى أعلى دقة.
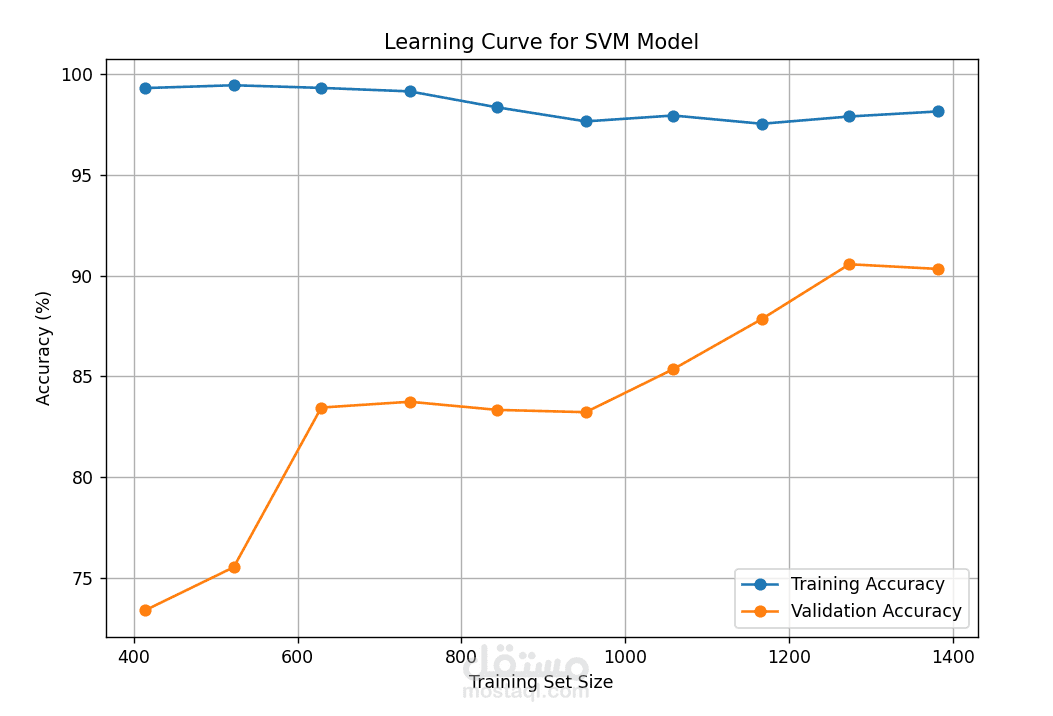
3. تقييم النموذج
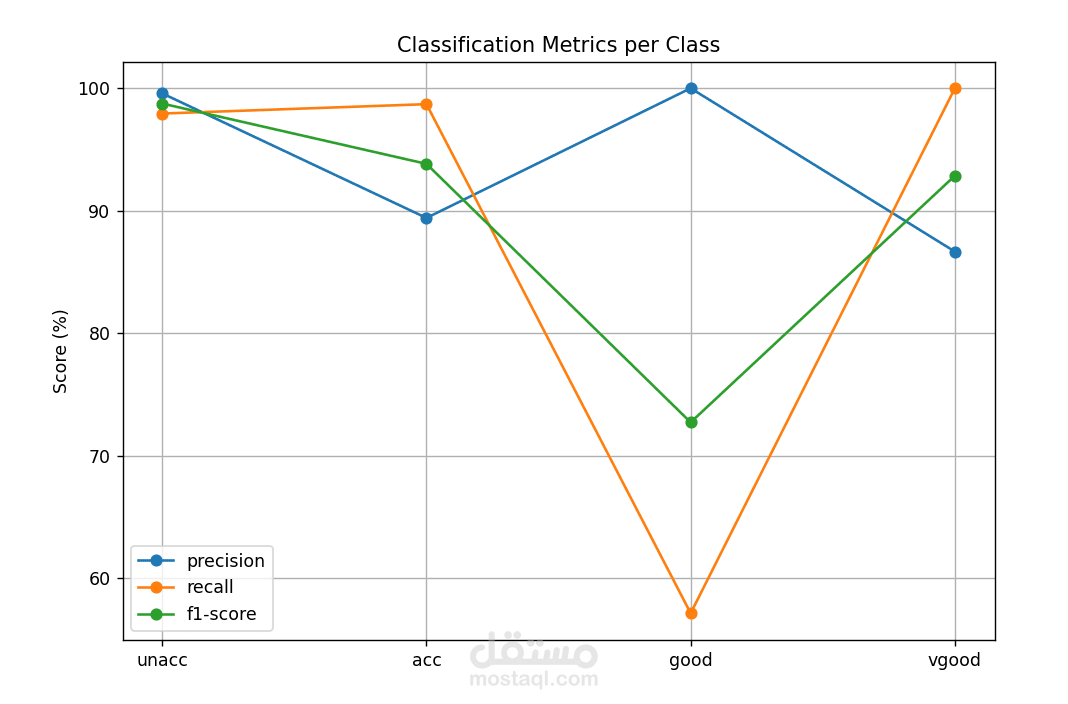
تقرير التصنيف (Classification Report): يظهر الـ precision, recall, f1-score لكل فئة.
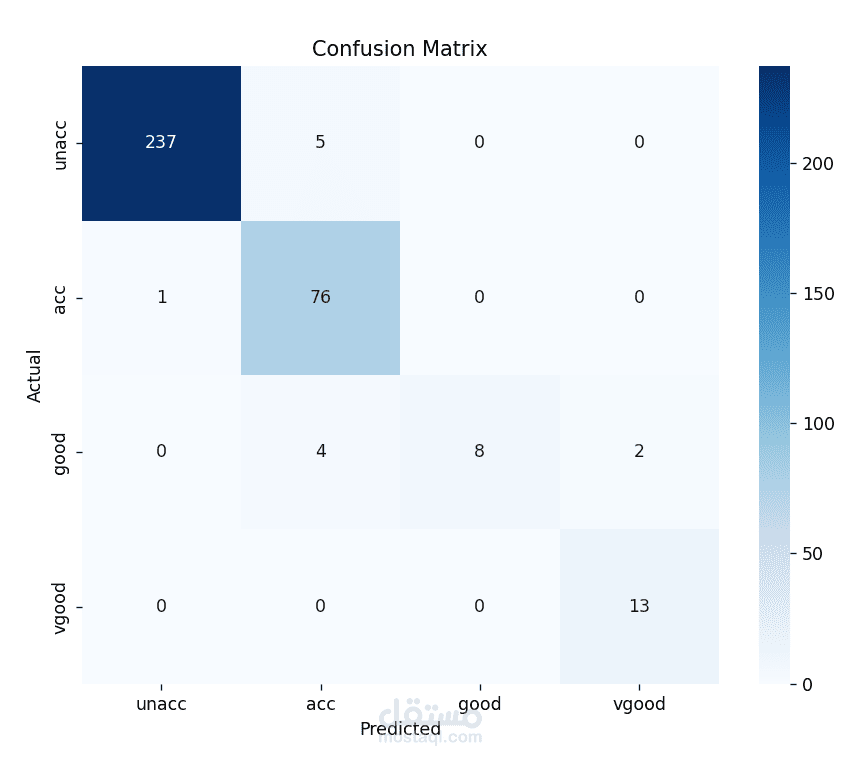
مصفوفة الارتباك (Confusion Matrix): لفهم أين يخطئ النموذج.