"Handwritten Digit Classification using a Multi-Layer Perceptron (MLP)"
تفاصيل العمل

هذه الصور توضح دورة حياة بناء نموذج شبكة عصبية اصطناعية (Artificial Neural Network) باستخدام مكتبة TensorFlow/Keras لتصنيف الأرقام المكتوبة بخط اليد (قاعدة بيانات MNIST).
إليك وصف الأكواد:
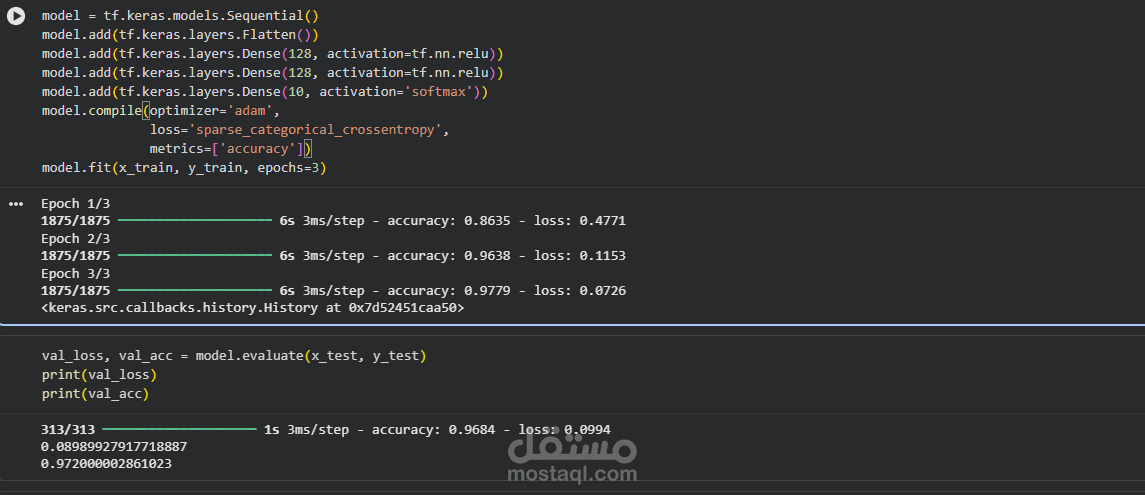
1. بناء وتدريب النموذج:
في هذه المرحلة، تم تصميم وهيكلة الشبكة العصبية
هيكل النموذج: تم استخدام نموذج متسلسل (Sequential) يتكون من:
طبقة Flatten: لتحويل الصورة من مصفوفة ثنائية الأبعاد إلى صف واحد (متجه).
طبقتين Dense (مخفية): تحتوي كل منهما على 128طبقع مع دالة تنشيط relu.
طبقة Dense (الإخراج): تحتوي على 10 طبقات (تمثل الأرقام من 0 إلى 9) مع دالة softmax لتحويل المخرجات إلى احتمالات.
الإعداد (Compile): استخدم المحسن adam ودالة الخسارة sparse_categorical_crossentropy.
التدريب (Fit): تم تدريب النموذج لمدة 3 دورات (epochs).
النتائج:
نلاحظ تطور الدقة (accuracy) من 86% في الدورة الأولى إلى 97.7% في الدورة الثالثة.
انخفاض الخسارة (loss) بشكل كبير من 0.47 إلى 0.07، مما يدل على تعلم الموديل بكفاءة.
2. تقييم النموذج:
بعد التدريب، تم اختبار النموذج على بيانات لم يرها من قبل (x_test):
النتيجة: حقق النموذج دقة اختبار (val_acc) تصل إلى 97.2%. هذه نتيجة ممتازة وتؤكد أن النموذج قادر على التعميم (Generalization) وليس مجرد حفظ البيانات.
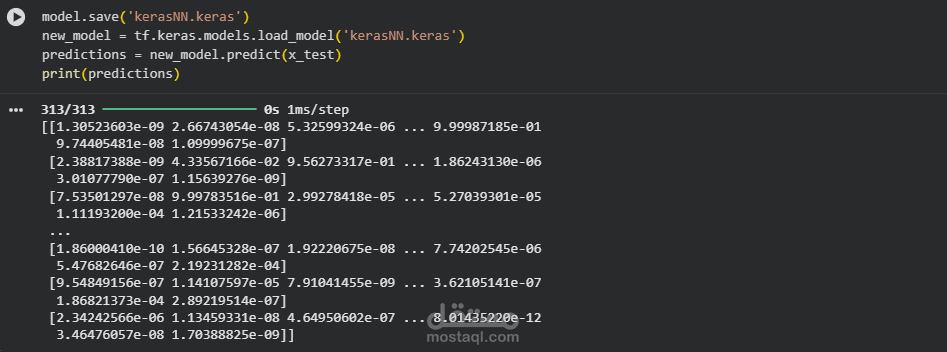
3. حفظ وتحميل النموذج والتنبؤ :
هذه الخطوة ضرورية لاستخدام النموذج لاحقاً دون الحاجة لإعادة التدريب
الحفظ: تم حفظ النموذج باسم kerasNN.keras.
التحميل: تم استدعاء النموذج المحفوظ في متغير جديد new_model.
التنبؤ: تم استخدام النموذج للتنبؤ بكل صور الاختبار.
النتائج: تظهر المصفوفة المطبوعة احتمالات لكل رقم. نلاحظ أرقاماً بصيغة (e-09)، وهي قيم صغيرة جداً، بينما توجد قيمة واحدة قريبة من 1 (مثلاً 9.99e-01)، وهي الرقم الذي اختاره الموديل.
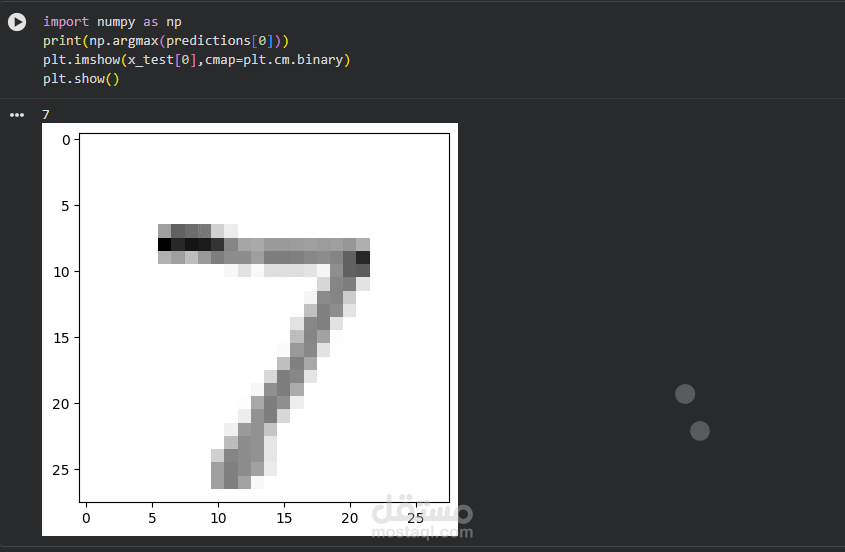
4. عرض وتأكيد التنبؤ :هنا نتحقق من صحة تنبؤ النموذج بشكل مرئي:
الكود: تم استخدام np.argmax لاستخراج الرقم صاحب أعلى احتمال من نتيجة التنبؤ للصورة الأولى، ثم تم عرض الصورة باستخدام plt.imshow.
النتيجة:
خرج الكود أعطى الرقم 7.
الصورة المعروضة هي فعلاً للرقم 7.
هذا يثبت نجاح النموذج تماماً في التعرف على الرقم بشكل صحيح.