streaming data pipeline using kafka
تفاصيل العمل
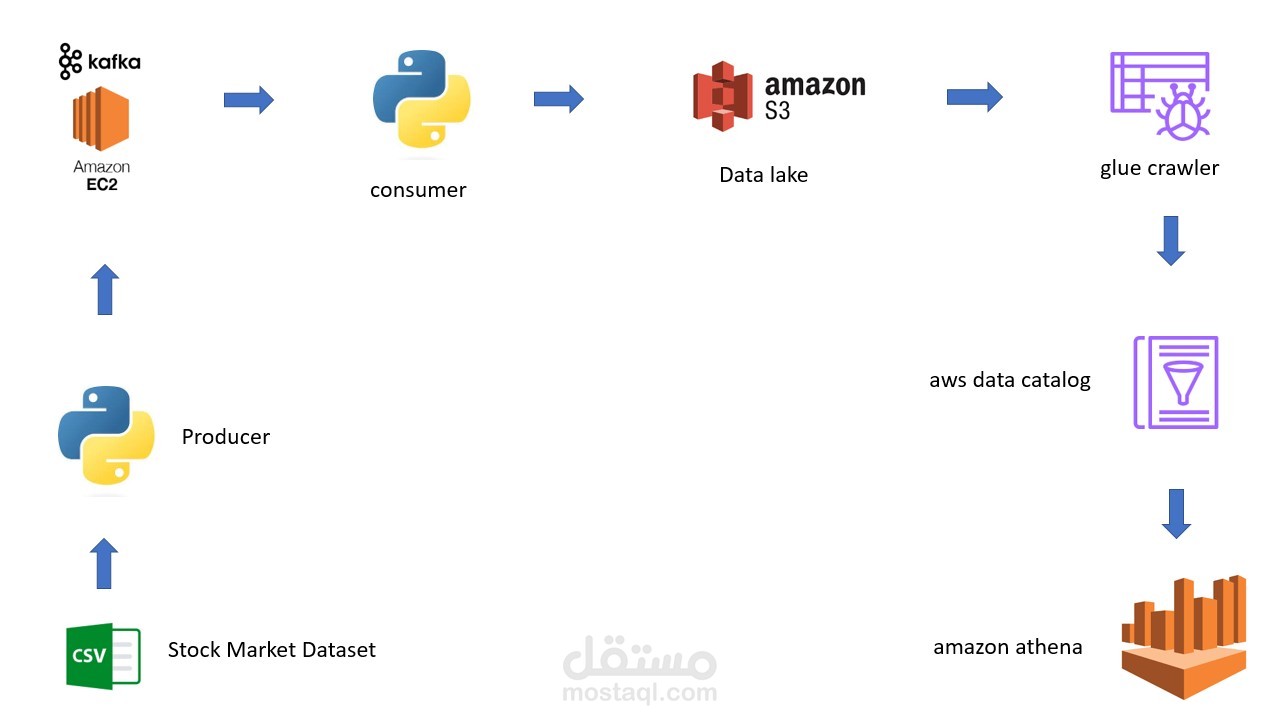
implemented a streaming data pipeline using Kafka to ingest data from producers and deliver it to consumers. The data is then pushed to Amazon S3, where it is subsequently crawled using the Amazon Glue crawler, enabling the execution of SQL queries on Amazon Athena.