استخراج ومعالجة بيانات الوظائف من Wuzzuf باستخدام Web Scraping
تفاصيل العمل
نبذة عن المشروع:
طورت نظام متكامل لاستخراج بيانات الوظائف تلقائياً من موقع Wuzzuf باستخدام Web Scraping المتقدم، يتضمن ثلاث مراحل: تجاوز أنظمة الحماية، استخراج البيانات، وتنظيفها لتصبح جاهزة للتحليل.
مراحل العمل
المرحلة الأولى: اختبار الوصول
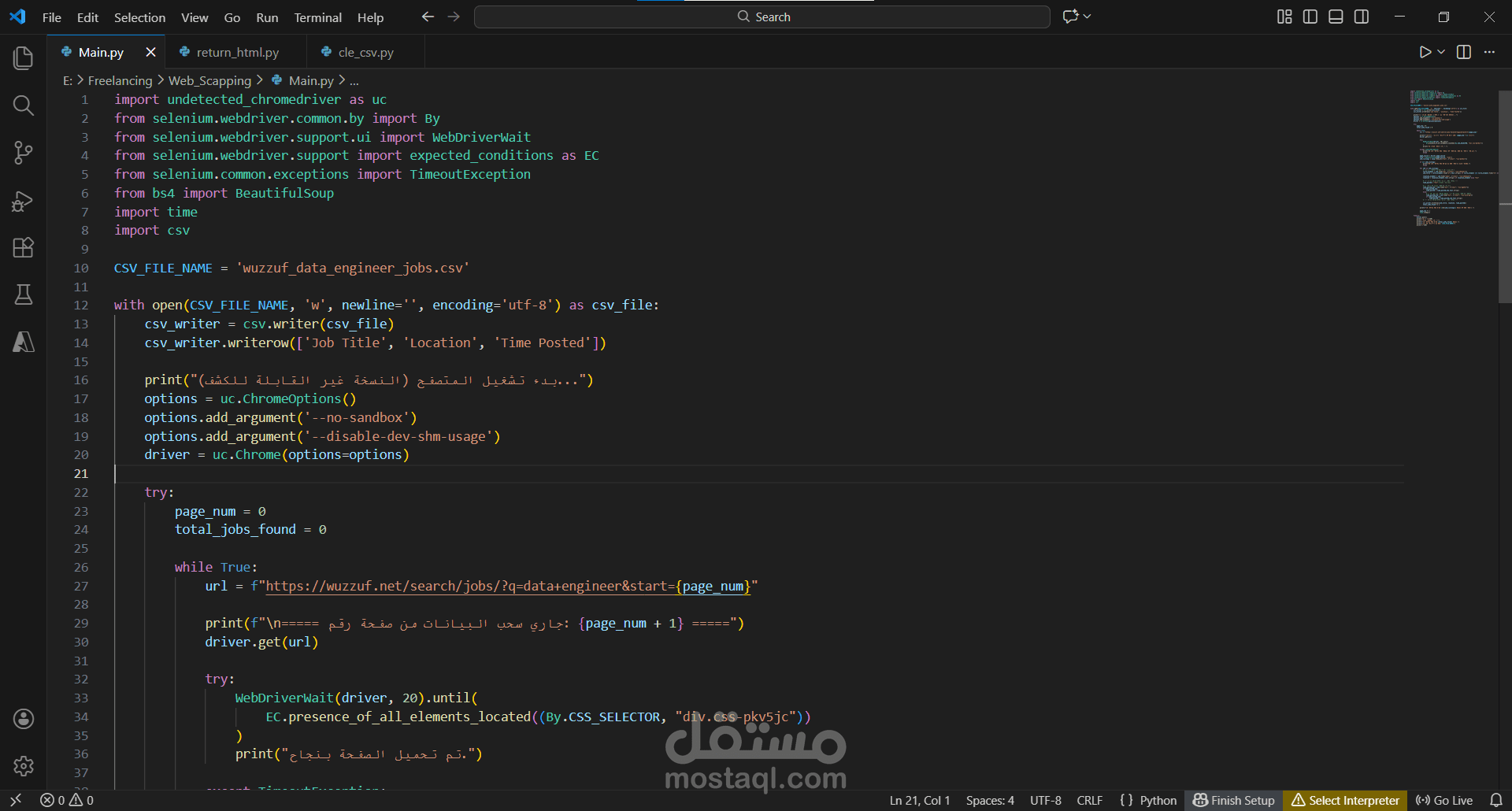
استخدمت Undetected ChromeDriver لتجاوز أنظمة كشف البوتات، مع ضبط خيارات المتصفح وانتظار 15 ثانية لتحميل المحتوى الديناميكي، وحفظ الصفحة كاملة في HTML.
المرحلة الثانية: الاستخراج التلقائي
التنقل بين الصفحات:
بنيت نظام pagination ذكي باستخدام معامل start في URL مع آلية توقف تلقائي.
استخراج البيانات:
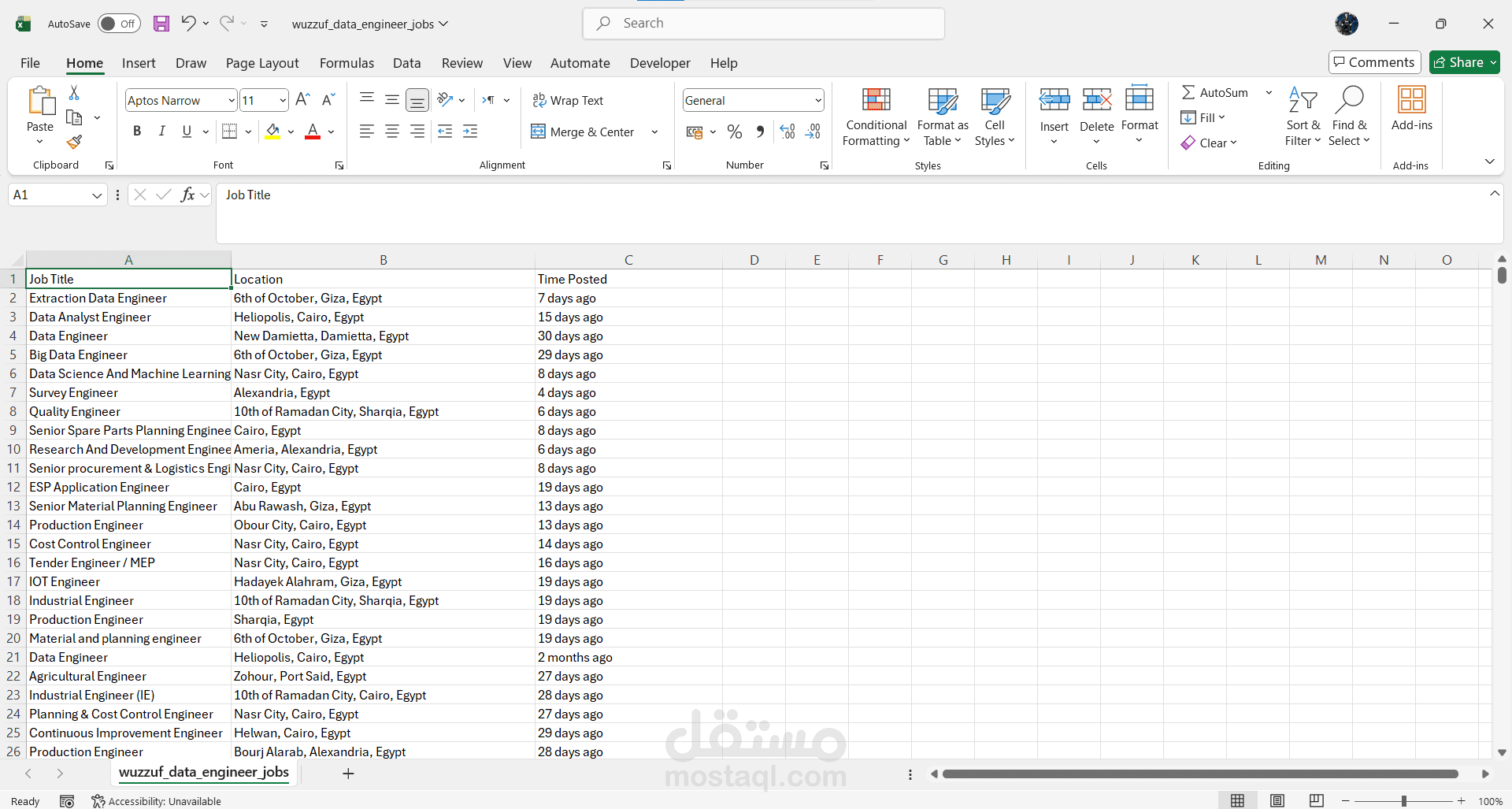
استخدمت BeautifulSoup لاستخراج ثلاثة حقول: عنوان الوظيفة، الموقع، ووقت النشر، مع معالجة حالتين مختلفتين للعرض وإضافة "N/A" للحقول المفقودة.
الحفظ:
حفظت البيانات في CSV بترميز UTF-8 مع عداد للتتبع وتقارير بعد كل صفحة، واستخدمت try-finally لضمان إغلاق المتصفح.
المرحلة الثالثة: تنظيف البيانات
بناء دالة ذكية:
صممت parse_relative_date لتحويل النصوص الزمنية:
"hour" → 0 أيام
"yesterday" → 1 يوم
الأسابيع → ×7
الأشهر → ×30
السنوات → ×365
النتيجة:
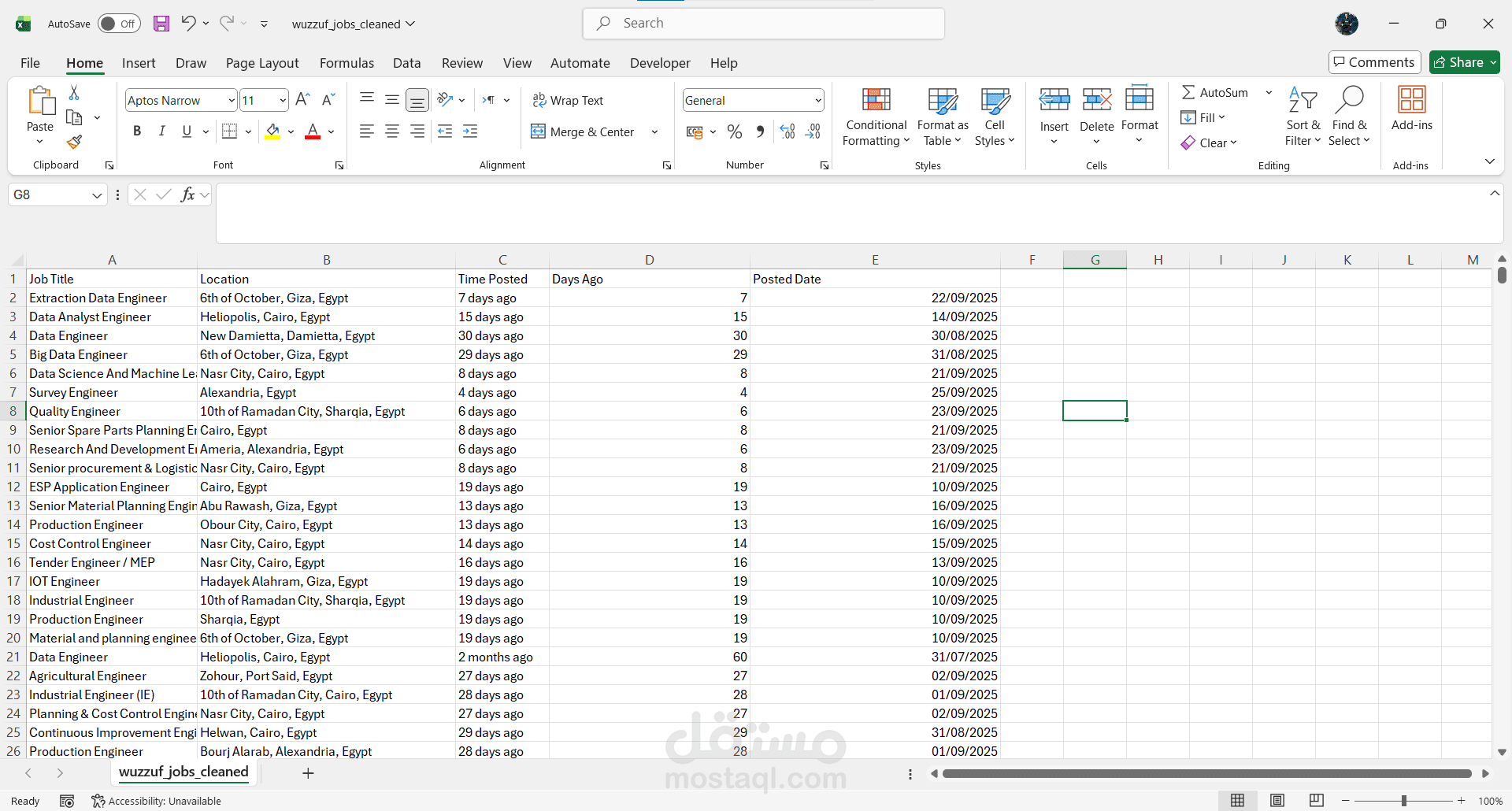
أضفت عمودين جديدين (Days Ago و Posted Date) بصيغة YYYY-MM-DD، وحفظت الملف النهائي بترميز UTF-8.
التحديات والحلول
أنظمة الحماية: استخدام Undetected ChromeDriver
المحتوى الديناميكي: WebDriverWait بدلاً من time.sleep
اختلاف التنسيقات: منطق مرن لحالتين مختلفتين
دقة التواريخ: دالة شاملة بتقريبات معقولة
النتائج
استخراج مئات الوظائف في دقائق
ملف CSV جاهز للتحليل
سهولة تعديل الكود لمسميات وظيفية أخرى
تواريخ دقيقة قابلة للفرز
المهارات المستخدمة
Web Scraping (Selenium)
Bot Detection Bypass
HTML Parsing (BeautifulSoup)
Dynamic Content Handling
String Parsing
Data Cleaning
Error Handling
CSV Management
Python Programming
المكتبات المستخدمة
Python 3 - Undetected ChromeDriver - Selenium - BeautifulSoup4 - CSV - Datetime - LXML