نظام استخراج بيانات من مواقع الويب بتنسيقات متعددة مع قابلية للتخصيص بسهولة
تفاصيل العمل
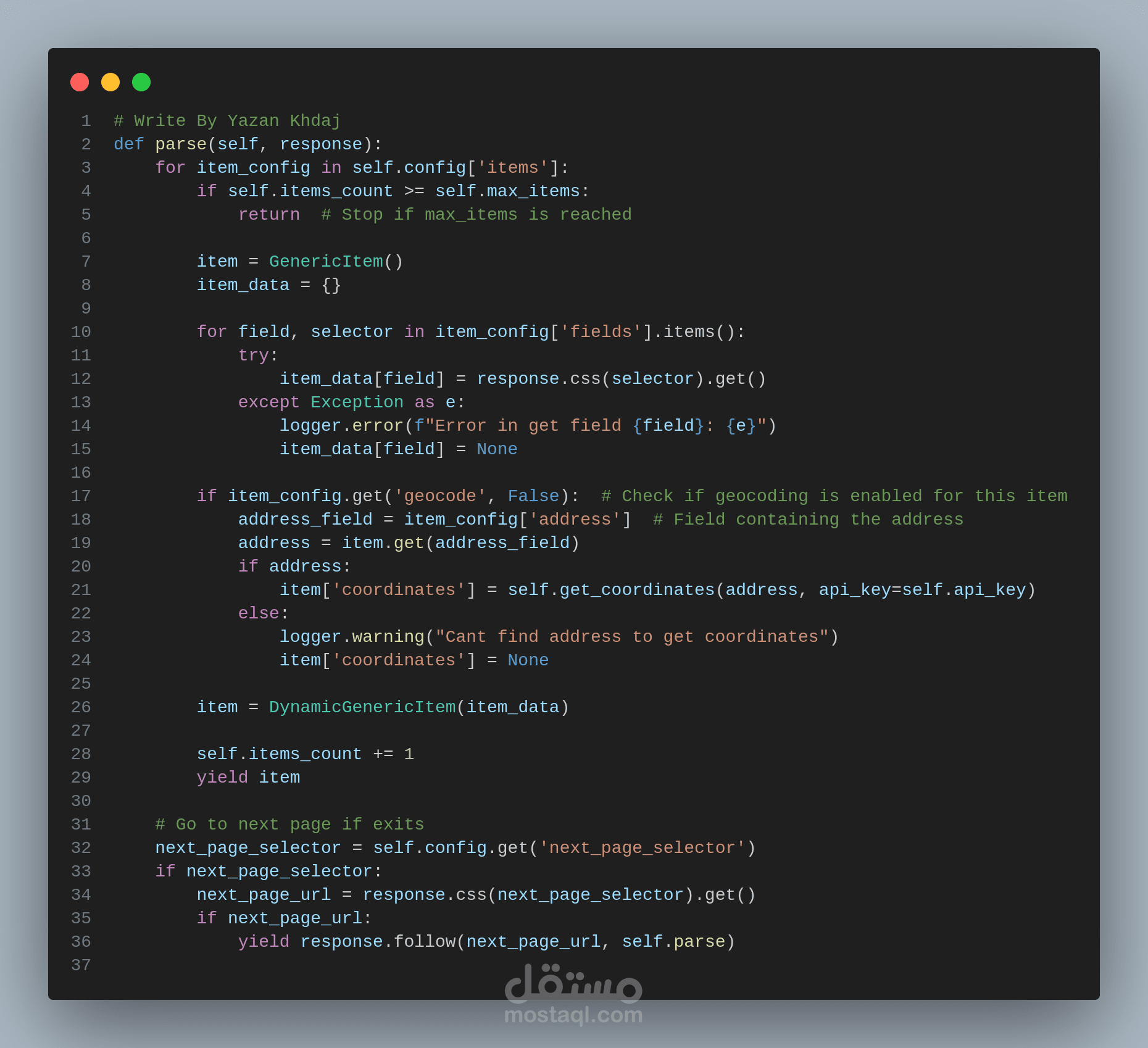
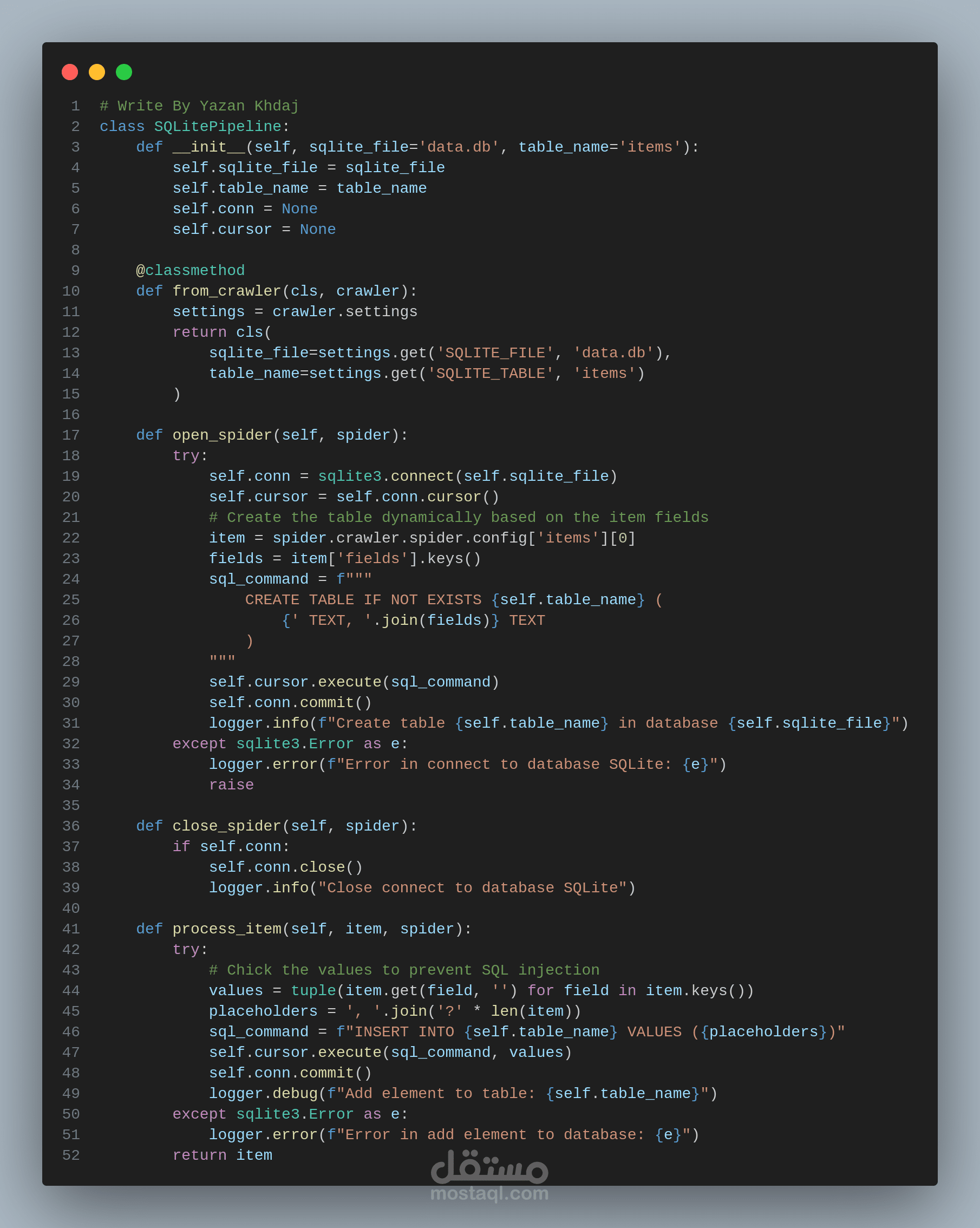
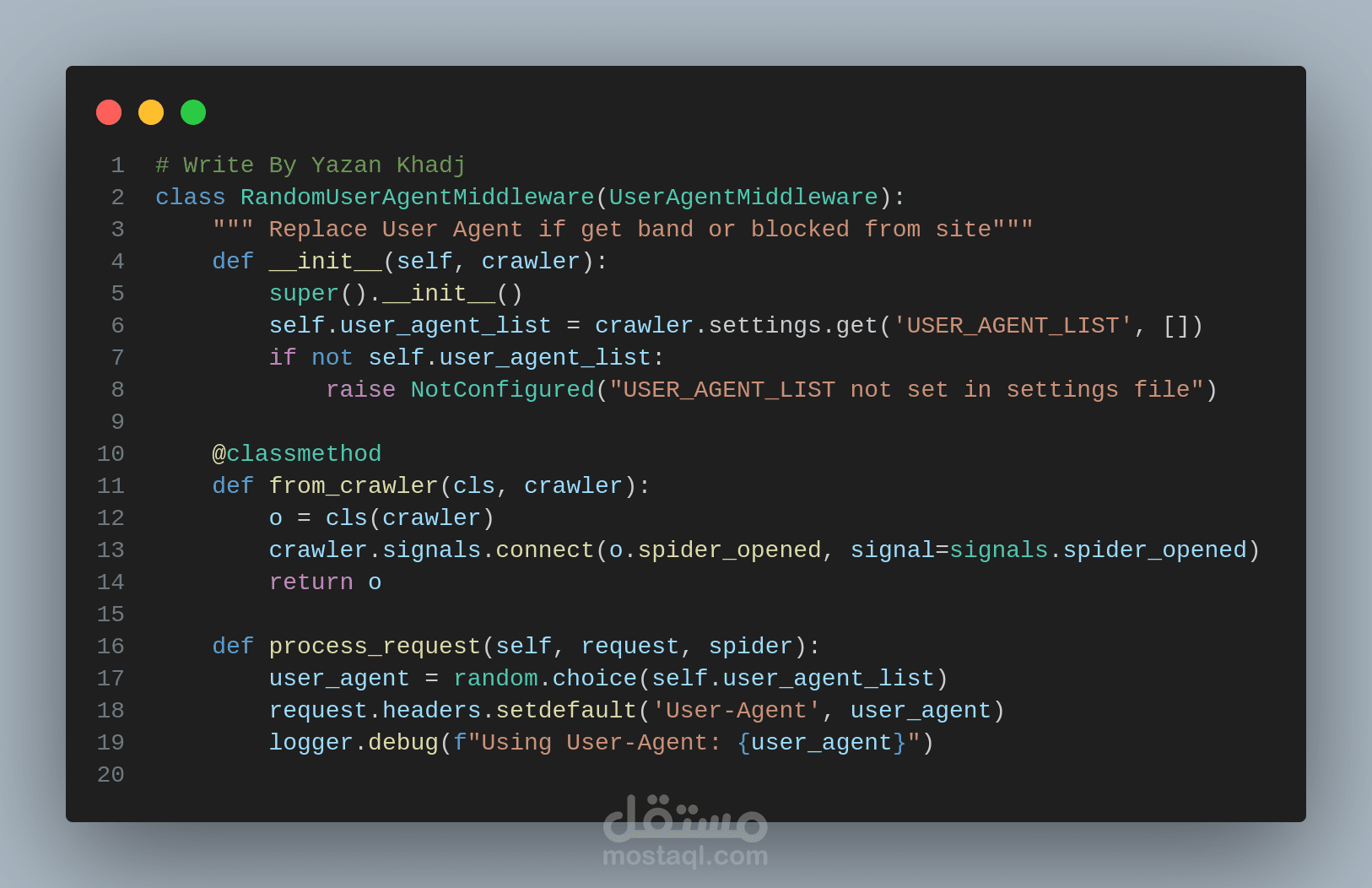
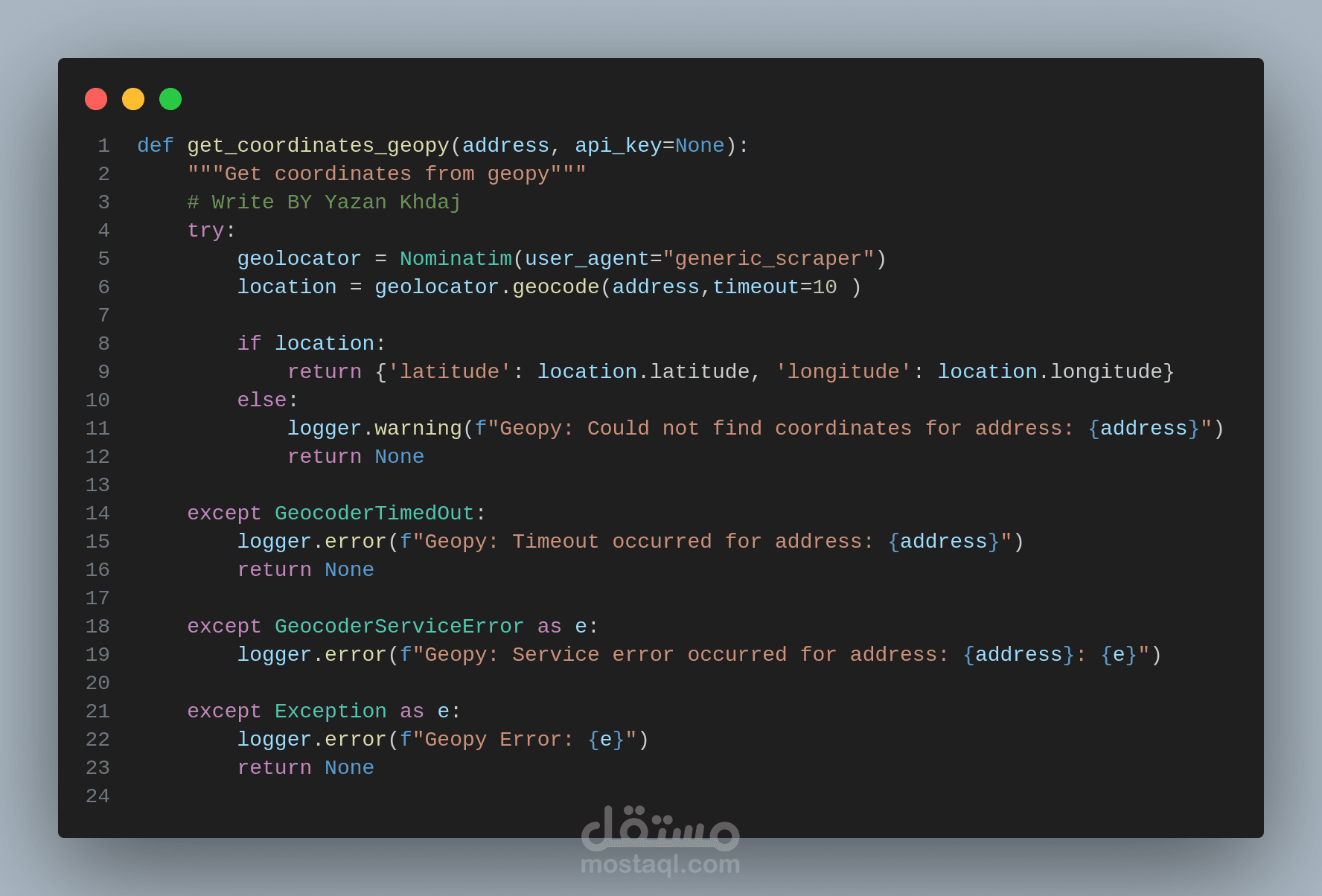


هذا المشروع هو نظام مصمم لاستخراج البيانات من أي موقع ويب بكفاءة وموثوقية. يعتمد على Python و Scrapy، ويتميز ببنيته المعيارية التي تسمح بتخصيص كامل لسلوك الاستخراج دون الحاجة لتعديل الكود الأساسي.
- المكونات الأساسية:
* Scrapy Spider: المحرك الرئيسي لاستخراج البيانات.
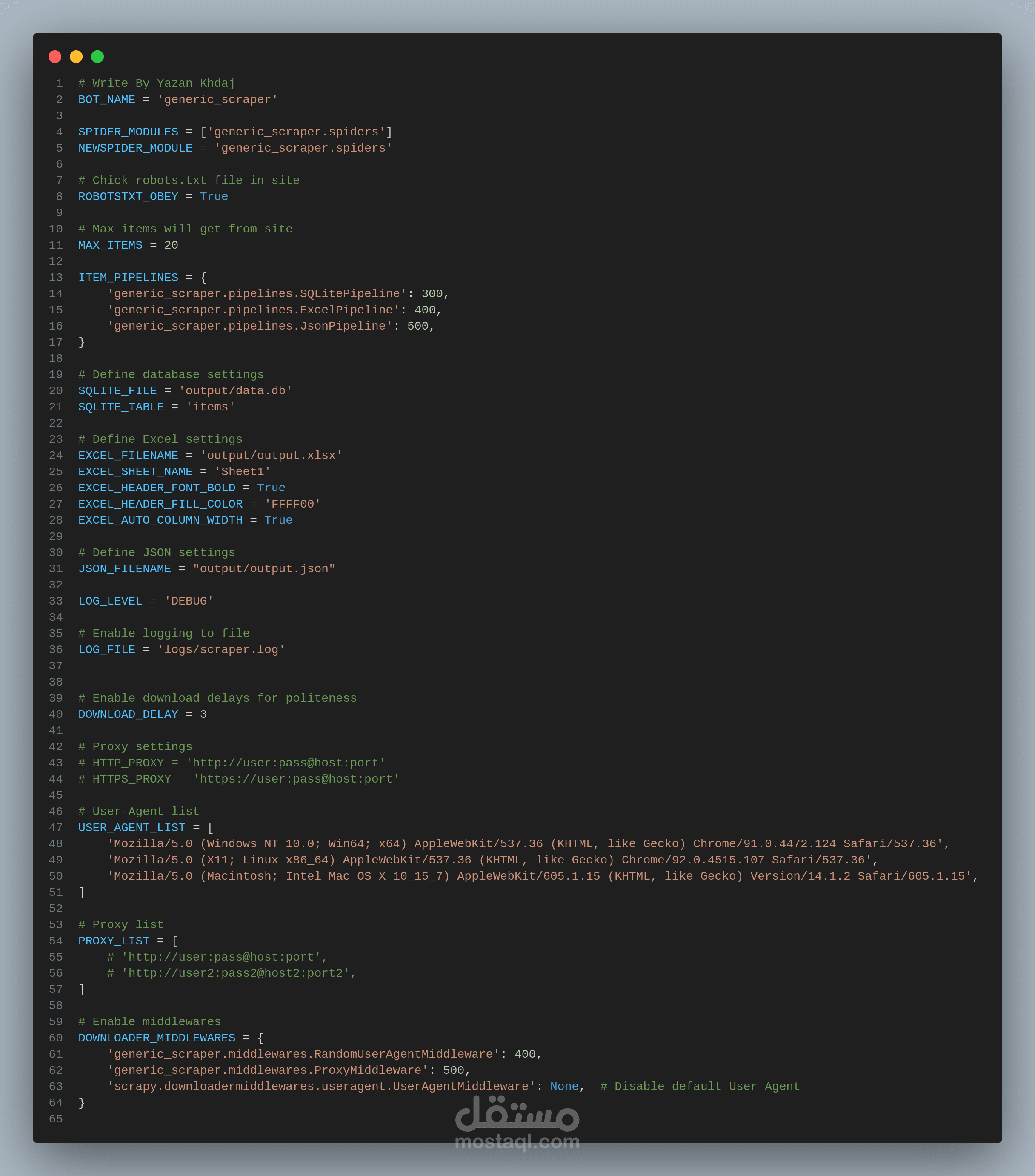
* ملف الإعدادات (settings.py): يحتوي على إعدادات عامة للنظام، مثل مسارات الملفات والوكلاء (Proxies).
* ملف التكوين (config.json): يحدد المواقع المستهدفة، عناصر البيانات، وقواعد المعالجة.
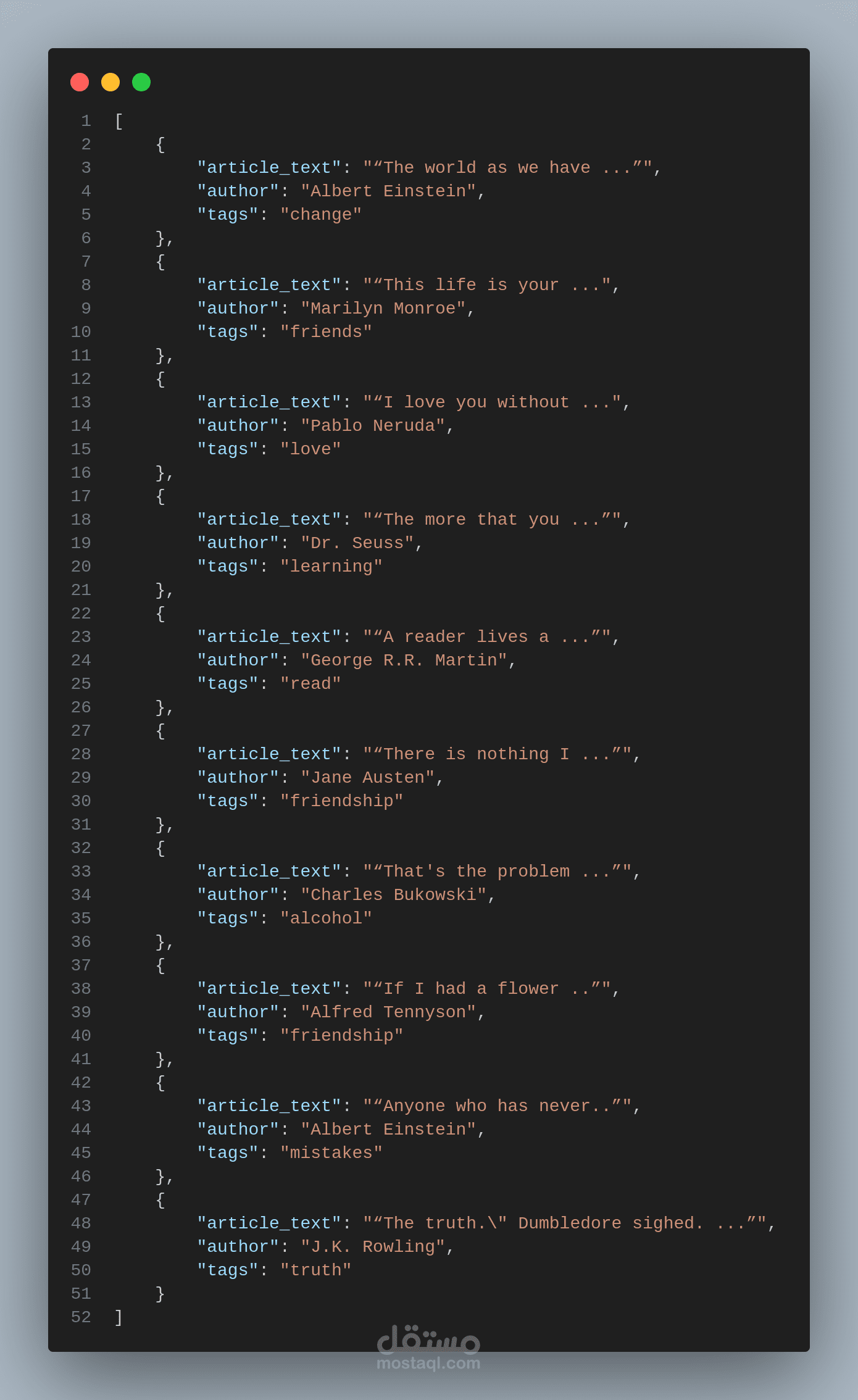
* Data Pipeline: يقوم بتحويل البيانات وتخزينها في تنسيقات: SQLite، JSON، و Excel (باستخدام openpyxl).
(Geolocation Module): تستخدم APIs خارجية أو قواعد بيانات محلية لاستخلاص خطوط الطول والعرض من العناوين أو المعلومات الأخرى ذات الصلة.
* Middlewares: مكونات وسيطة لإدارة الطلبات والاستجابات (تأخير، وكلاء، ملفات تعريف الارتباط).
* آلية مكافحة الحظر (Anti-Blocking): تتضمن تأخيرات عشوائية، تدوير User-Agent، وإدارة الوكلاء.
- الخصائص المميزة:
* فصل التكوين عن الكود: يتم تعريف منطق الاستخراج بالكامل في ملف JSON، مما يتيح تعديل السلوك بسهولة.
* بنية معيارية: تصميم معياري (OOP) يسمح بإضافة مكونات جديدة بسهولة لتوسيع وظائف النظام.
* معالجة مرنة للبيانات: يمكن تطبيق سلسلة من العمليات على البيانات المستخرجة لتنظيفها وتنسيقها.
* دعم تحديد الموقع الجغرافي: استخراج خطوط الطول والعرض وتضمينها في البيانات المستخرجة.
* حماية متكاملة من الحظر: تضمن استمرارية عملية الاستخراج دون انقطاع.
- المهارات المطبقة:
* Python و Scrapy: تطوير تطبيقات استخراج البيانات.
* JSON: تصميم ملفات التكوين.
* تصميم أنظمة برمجية معيارية: إنشاء بنى مرنة وقابلة للتطوير.
* تحديد الموقع الجغرافي (Geolocation): استخدام APIs وقواعد بيانات لتحديد المواقع.
* تجنب الحظر (Anti-Scraping): تنفيذ استراتيجيات للحفاظ على استمرارية العمل.