Islam Web Medical Data scrapping
تفاصيل العمل
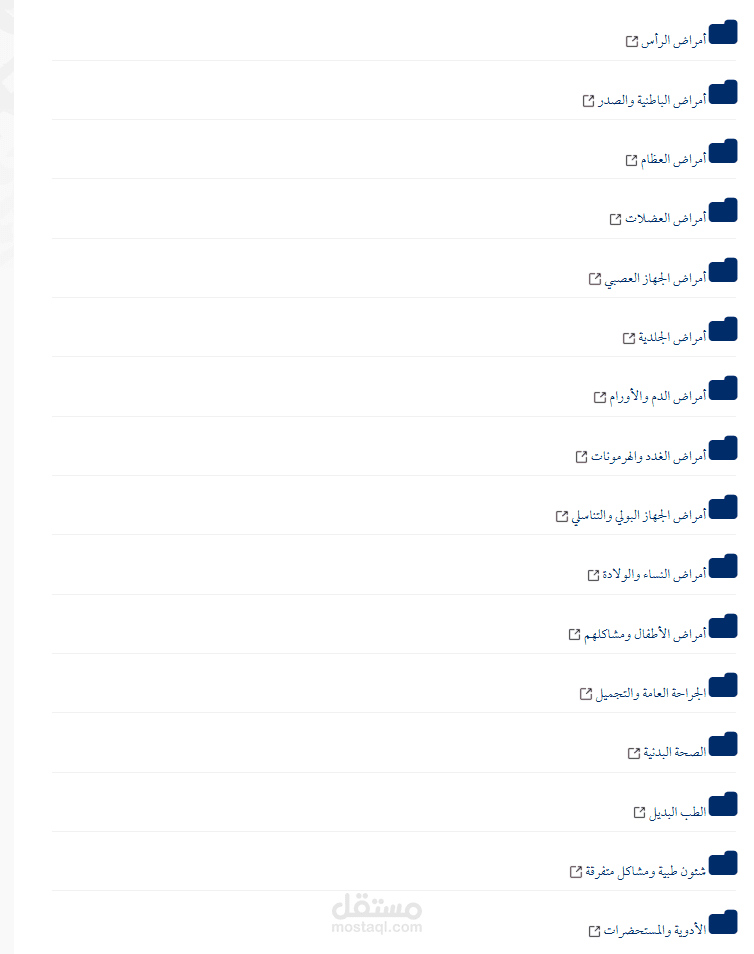
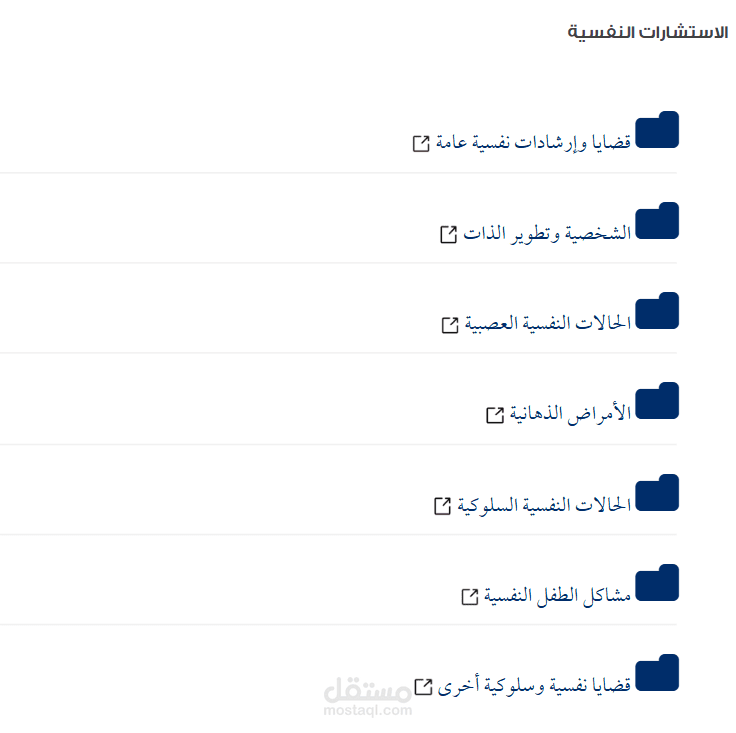
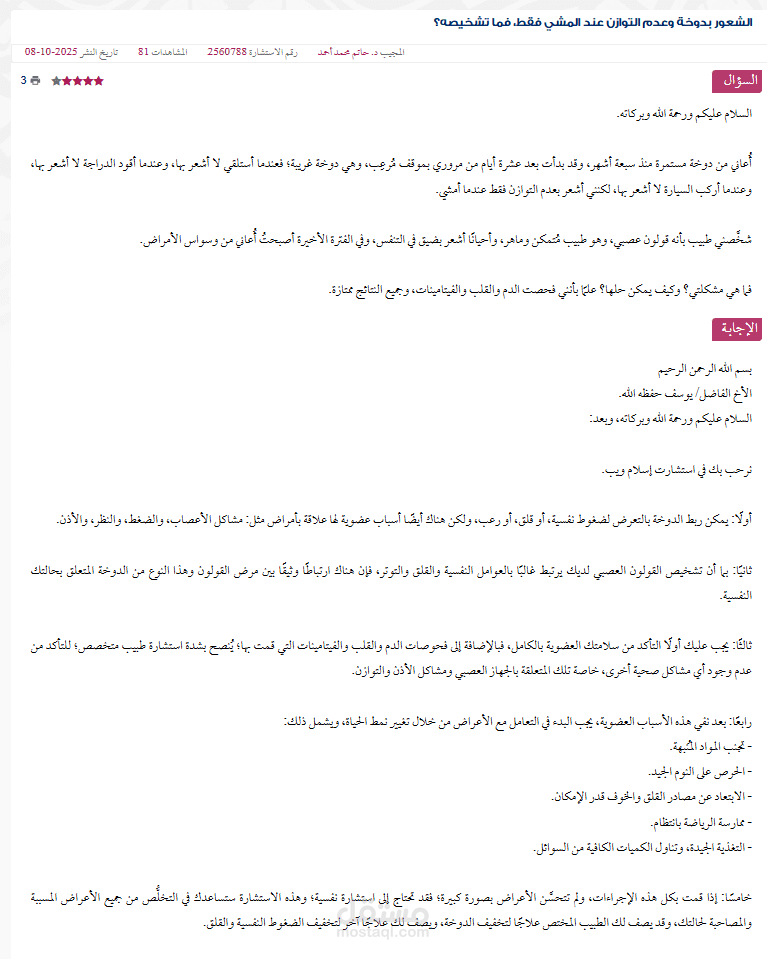
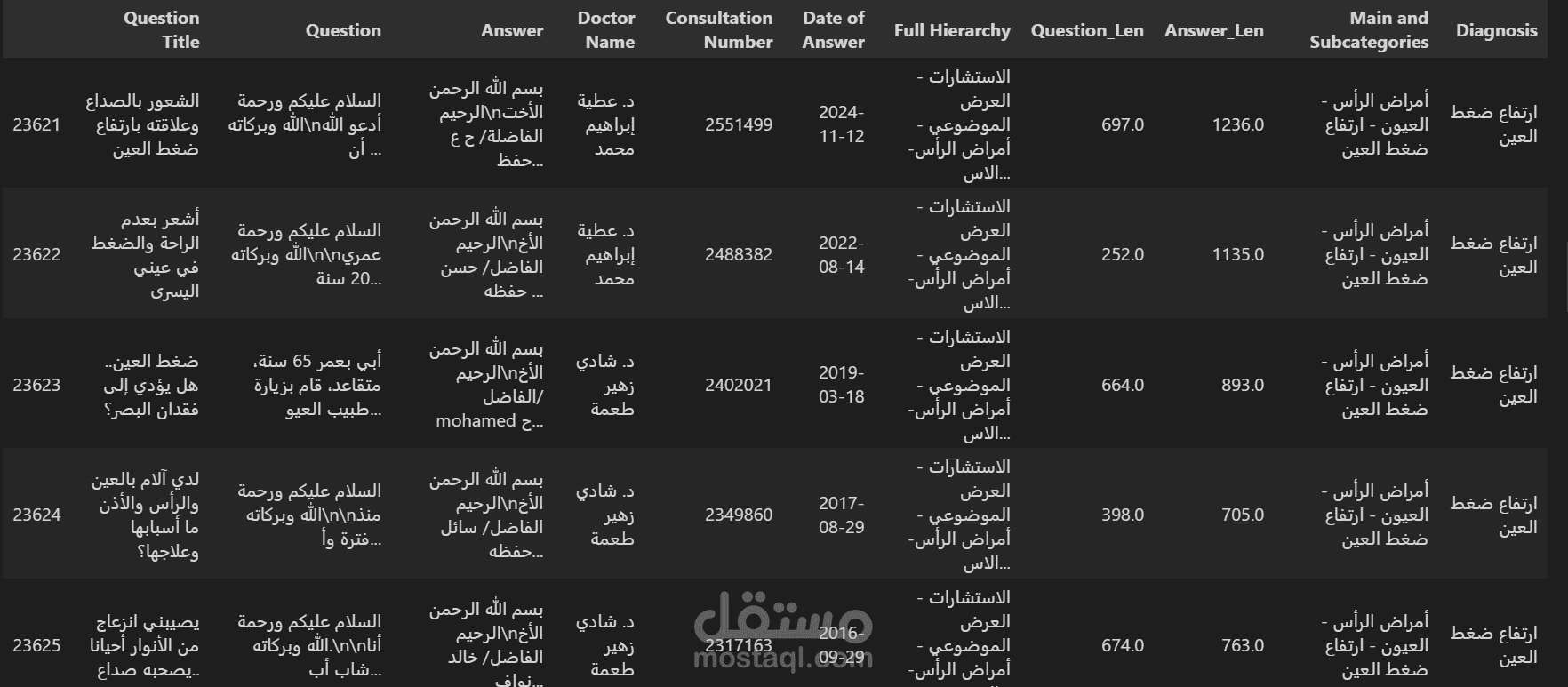
نفذت مشروع Web Scraping وتحليل بيانات طبية عربية من موقع إسلام ويب، بهدف إنشاء قاعدة بيانات غنية يمكن استخدامها في تطبيقات الذكاء الاصطناعي الطبي، مثل أنظمة الإجابة الذكية (Medical Chatbots) أو النماذج التعليمية الطبية.
تفاصيل العمل:
تم تطوير سكربت كامل بلغة Python باستخدام مكتبات:
Selenium لاستخراج النصوص الطبية من صفحات الموقع.
Pandas لمعالجة وتنظيف البيانات وحفظها بصيغ منظمة (CSV / JSON).
تم استخراج ما يقرب من 113000 استشارة طبية حقيقية من التخصصات المختلفة (الجسدية والنفسية بأقسامهما) بموقع إسلام ويب.
لكل استشارة تم جمع:
عنوان السؤال الطبي
نص الاستشارة (السؤال التفصيلي)
رد الطبيب كاملاً
اسم الطبيب
رقم الاستشارة وتاريخ الرد
التخصص أو المسار الطبي الكامل (Full Hierarchy)
تم تنفيذ عمليات تنظيف للنصوص لإزالة الرموز والعلامات الزائدة وتنسيق الفقرات بشكل موحّد.
البيانات الناتجة أصبحت جاهزة للتحليل النصي، التدريب اللغوي، أو بناء أنظمة استرجاع المعرفة (RAG).
النتائج والمخرجات:
قاعدة بيانات طبية عربية مكونة من آلاف الاستشارات المصنّفة حسب التخصص.
بنية بيانات منظمة تدعم مشاريع تحليل النصوص الطبية أو التدريب اللغوي العربي.
كود Scraper مرن يمكن تعديله بسهولة لاستخراج بيانات من أقسام أخرى.
استخدمت البيانات لاحقًا في مشروع تخرّج في الذكاء الاصطناعي الطبي لبناء نظام ذكي لفهم الأسئلة الطبية وتقديم إجابات دقيقة اعتمادًا على المعرفة المستخرجة.