تطوير نموذج تعلم آلي (Gradient Boosting) لتشخيص سرطان الثدي بدقة عالية (Accuracy)
تفاصيل العمل

هذا المشروع يمثّل رحلة متكاملة في Data Science، حيث قمتُ بتحويل البيانات الطبية المعقدة إلى أداة تنبؤية قوية تدعم الأطباء في تشخيص أورام الثدي. ركّز عملي على بناء نظام Machine Learning قادر على تصنيف الأورام بفعالية عالية جدًا.
كيف تم الإنجاز؟ (My Approach)
لضمان أعلى درجات الموثوقية، اتبعتُ منهجية منظمة بدءًا من تحليل البيانات وصولاً إلى النماذج المتقدمة:
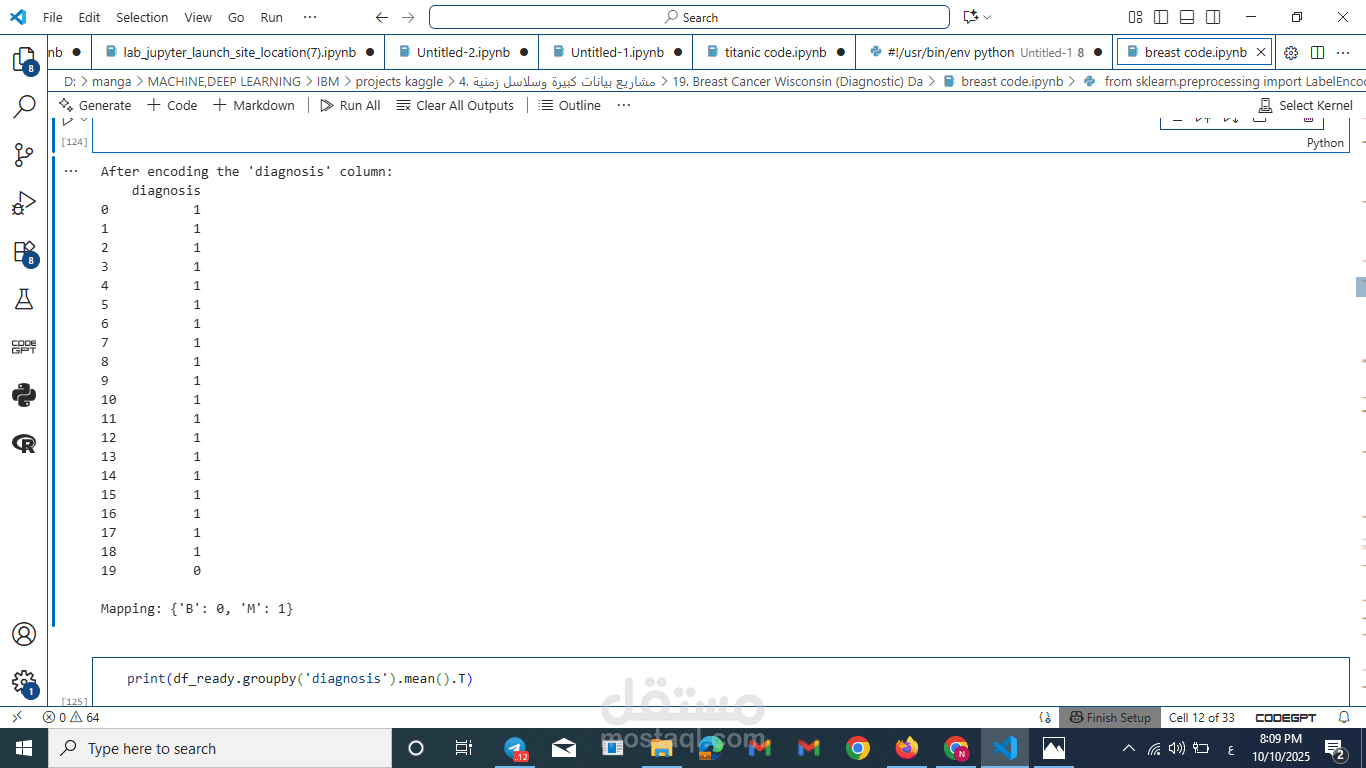
فهم عميق للبيانات (EDA): حللتُ بيانات الخزعات (569 عينة)، واكتشفتُ أن الخصائص المرتبطة بحجم وشكل الخلية، مثل radius_mean و perimeter_mean، هي الميزات التنبؤية الأقوى (Key Predictive Features).
تجهيز البيانات باحترافية: قمتُ بتطبيق RobustScaler لمعايرة الميزات (Feature Scaling)، وهي خطوة حاسمة لتهيئة البيانات بشكل يضمن سرعة ودقة النماذج، مع تحييد أثر أي قيم متطرفة (Outliers).
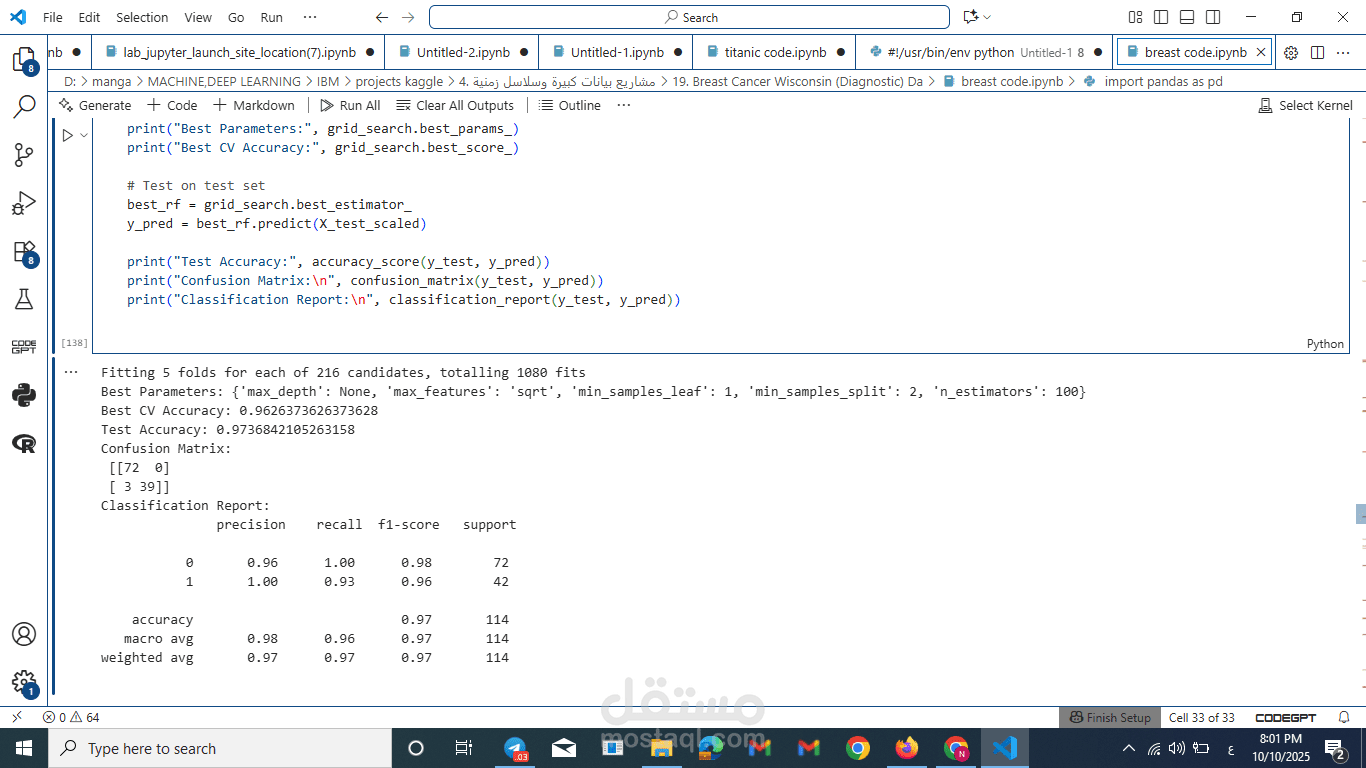
بناء النماذج المتقدمة: لم أكتفِ بالنماذج البسيطة؛ بل اختبرتُ نماذج متقدمة مثل Gradient Boosting، الذي يعد جزءاً من Ensemble Methods. هذا النموذج هو الأفضل لأنه يستطيع التقاط العلاقات الخفية والمعقدة في البيانات الطبية بدقة فائقة.
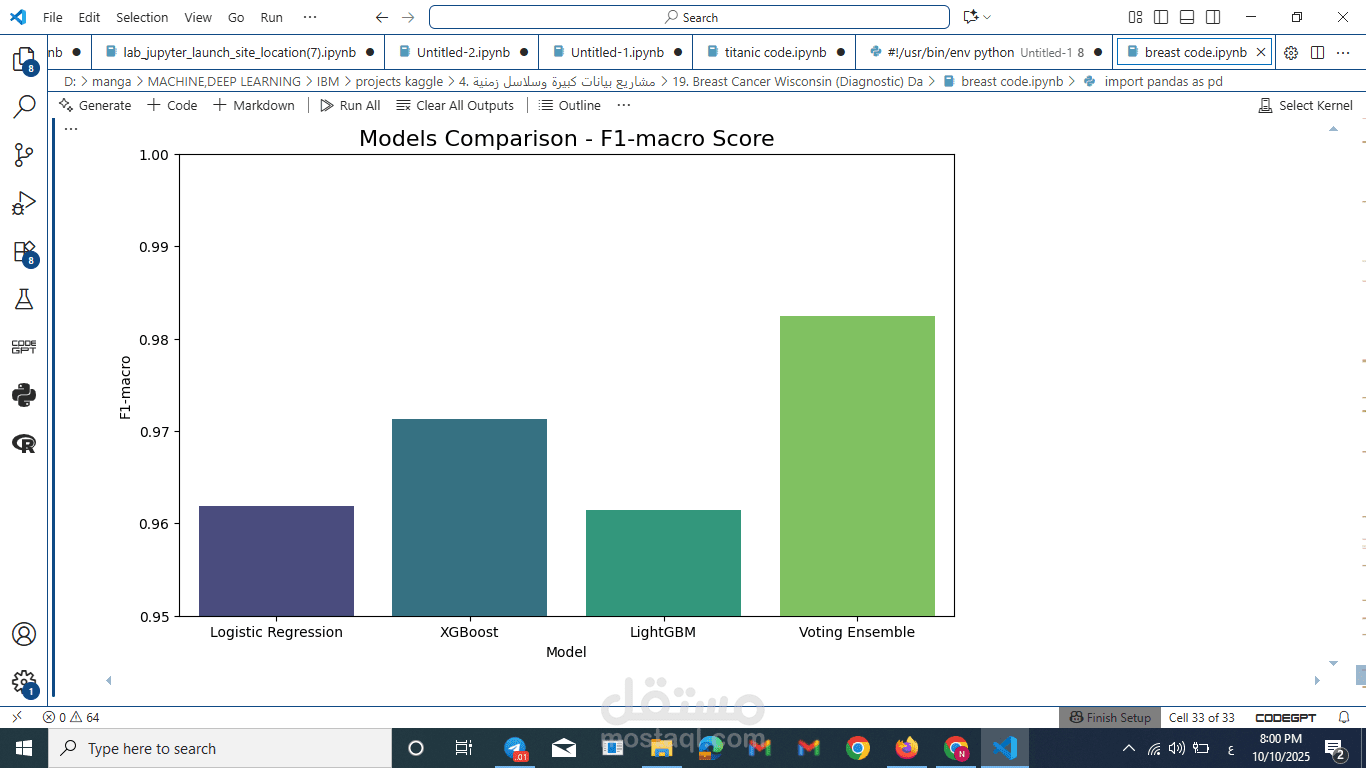
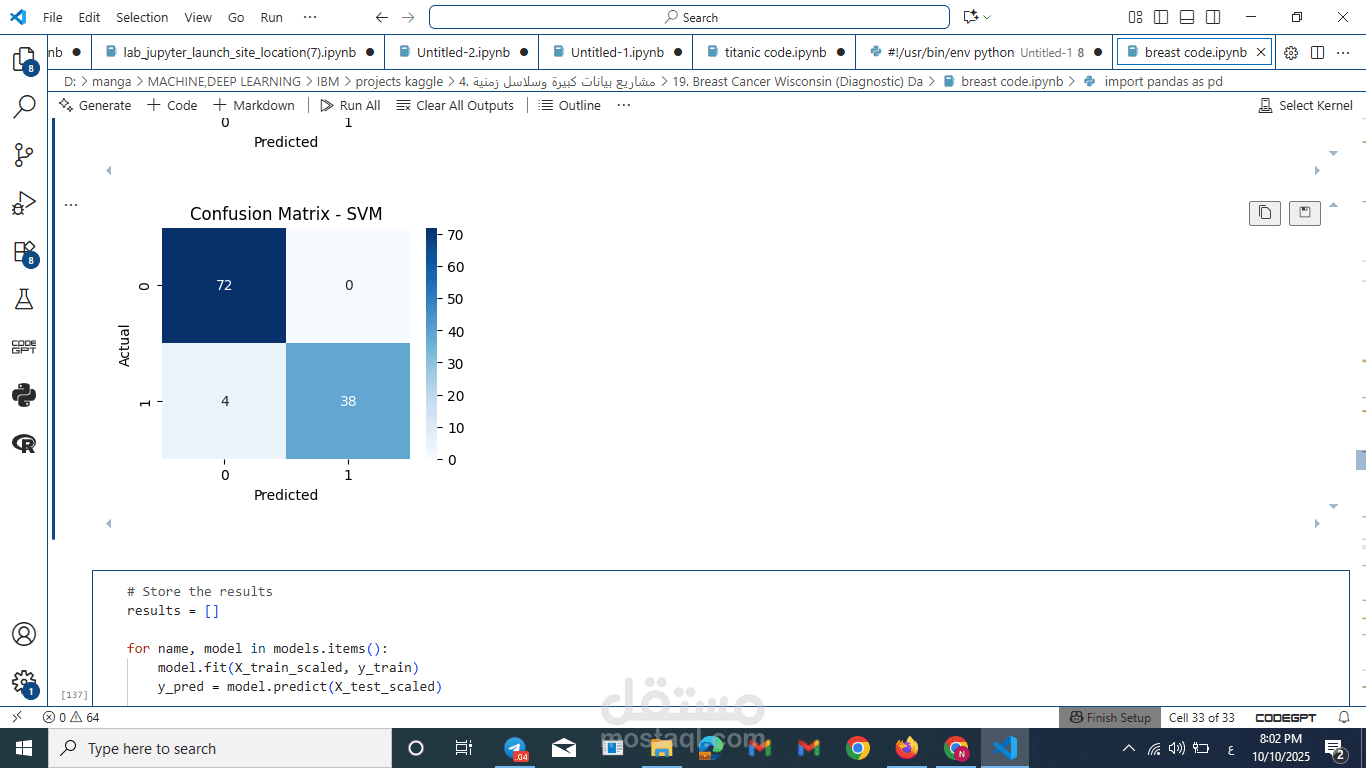
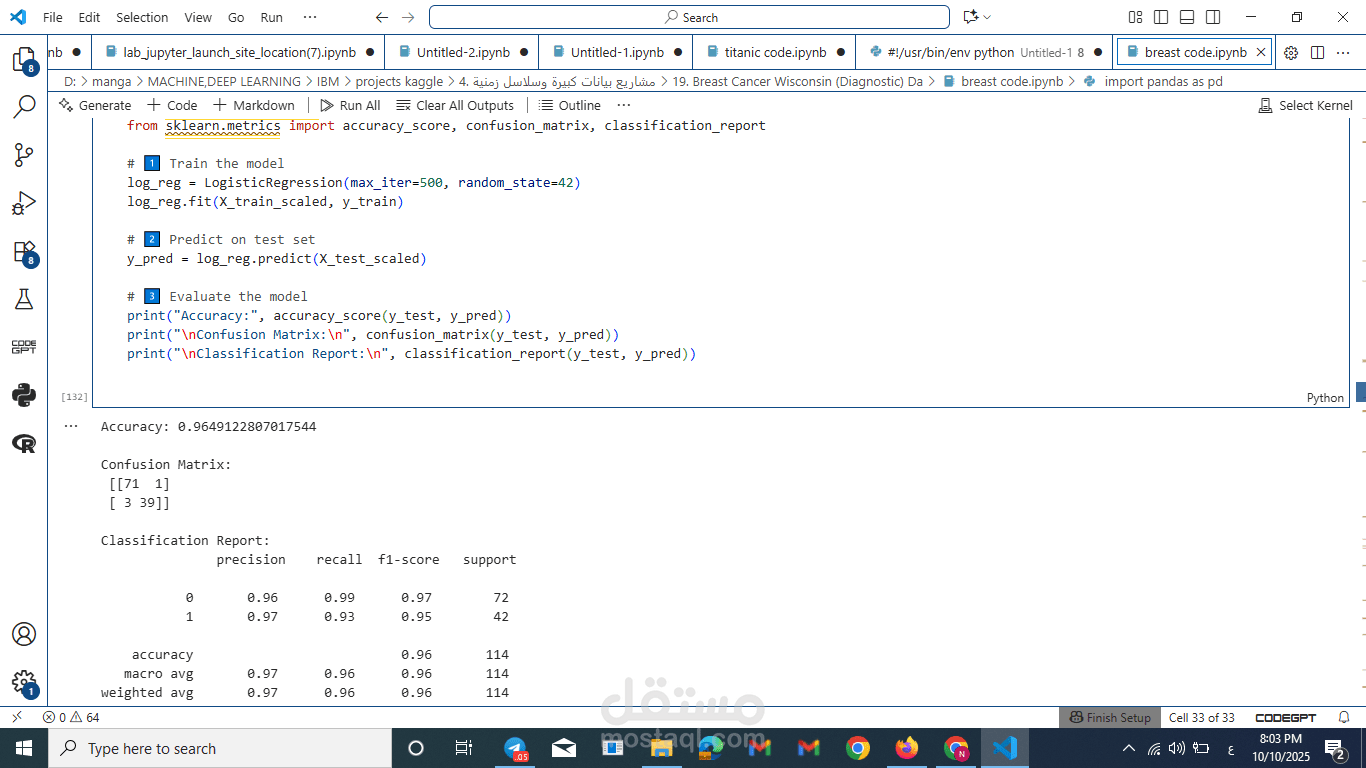
تقييم الأداء بدقة طبية: بدلاً من الاعتماد على الـ Accuracy وحدها، استخدمتُ مقياس F1-Macro Score. هذا المقياس يضمن توازناً مثالياً بين Precision و Recall، وهو أمر ضروري في الرعاية الصحية (Healthcare AI) لتقليل التشخيصات الخاطئة للحالات الخبيثة.
النتيجة والقيمة المضافة
نجحتُ في بناء Classification Model يُظهر أداءً استثنائياً وموثوقية عالية، مما يجعله أداة قوية للمساعدة في الكشف المبكر. هذا المشروع يعرض بوضوح مهاراتي في Feature Engineering وتطبيق الخوارزميات المتقدمة في سياق يخدم المجتمع.
رؤيتي للمستقبل: أهدف إلى دمج تقنيات Explainable AI (XAI) لزيادة شفافية النموذج وجعله أكثر قبولاً من قبل الأطباء.
الأدوات المستخدمة: Python, Scikit-learn, Pandas, Gradient Boosting.