استخلاص بيانات الأفلام من موقع Rotten Tomatoes
تفاصيل العمل


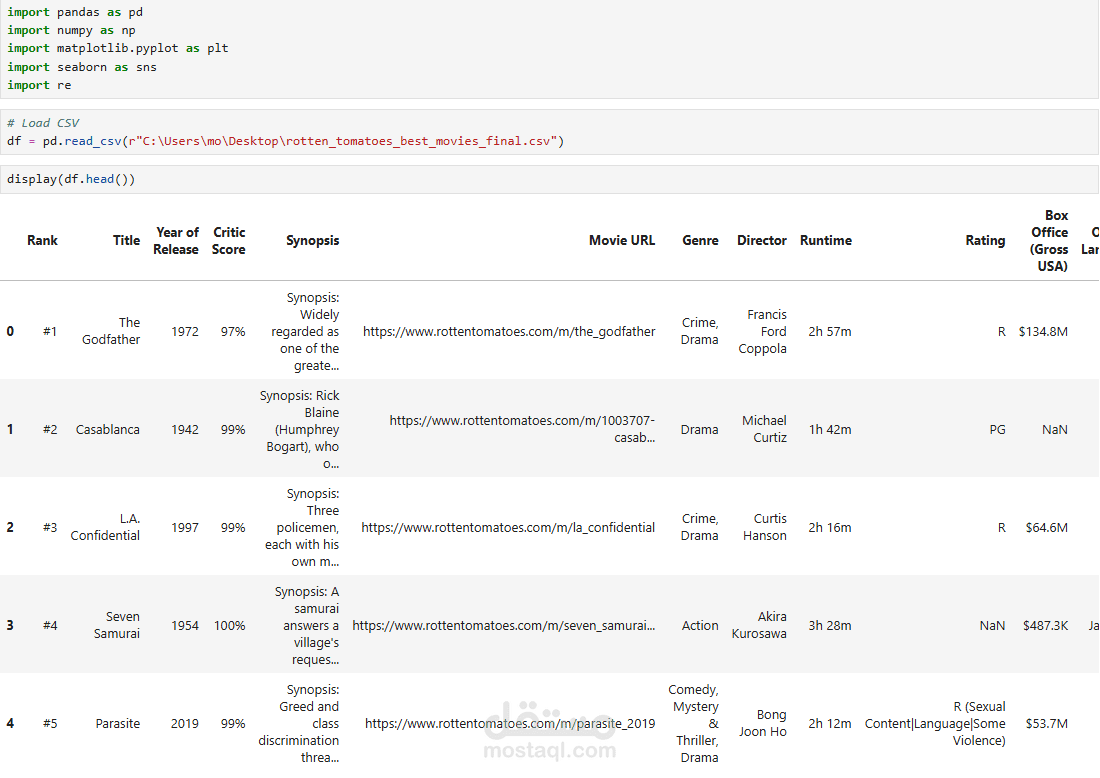
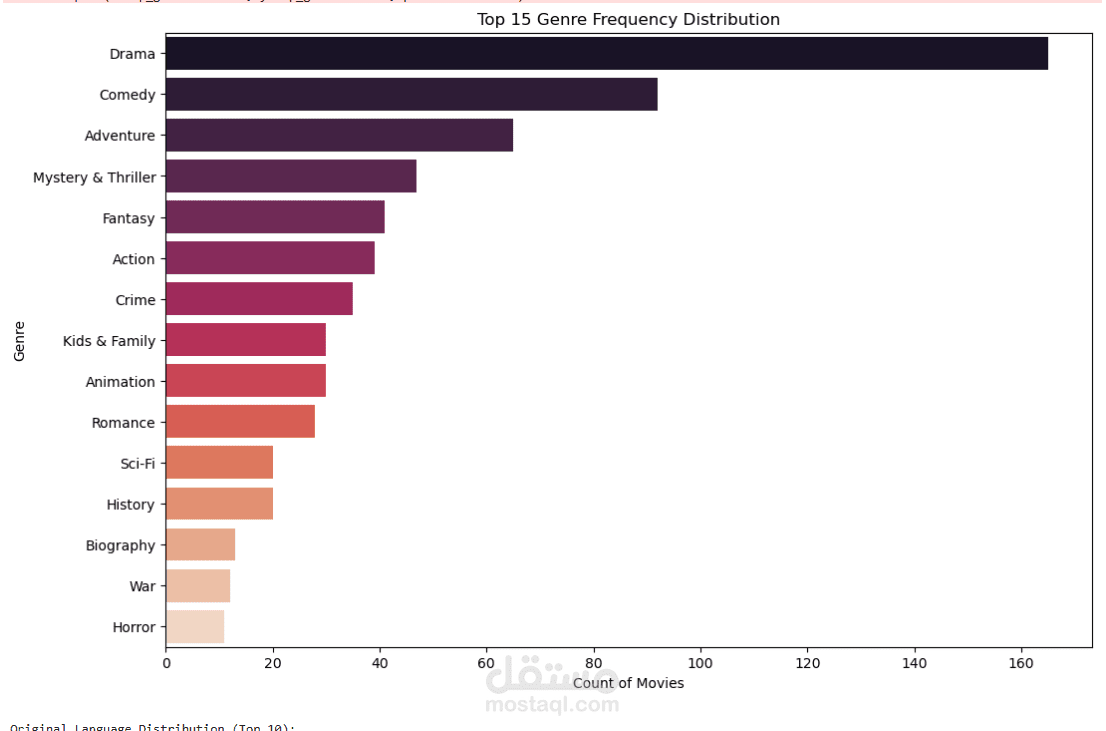
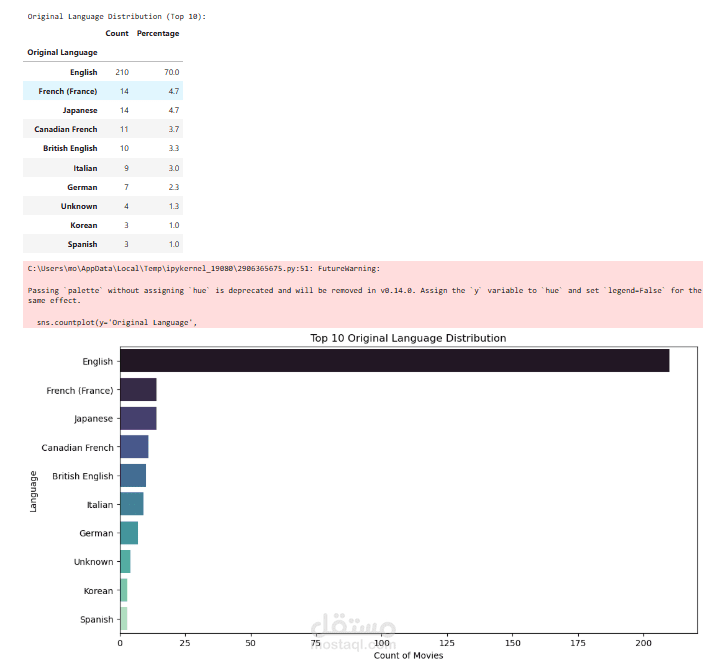
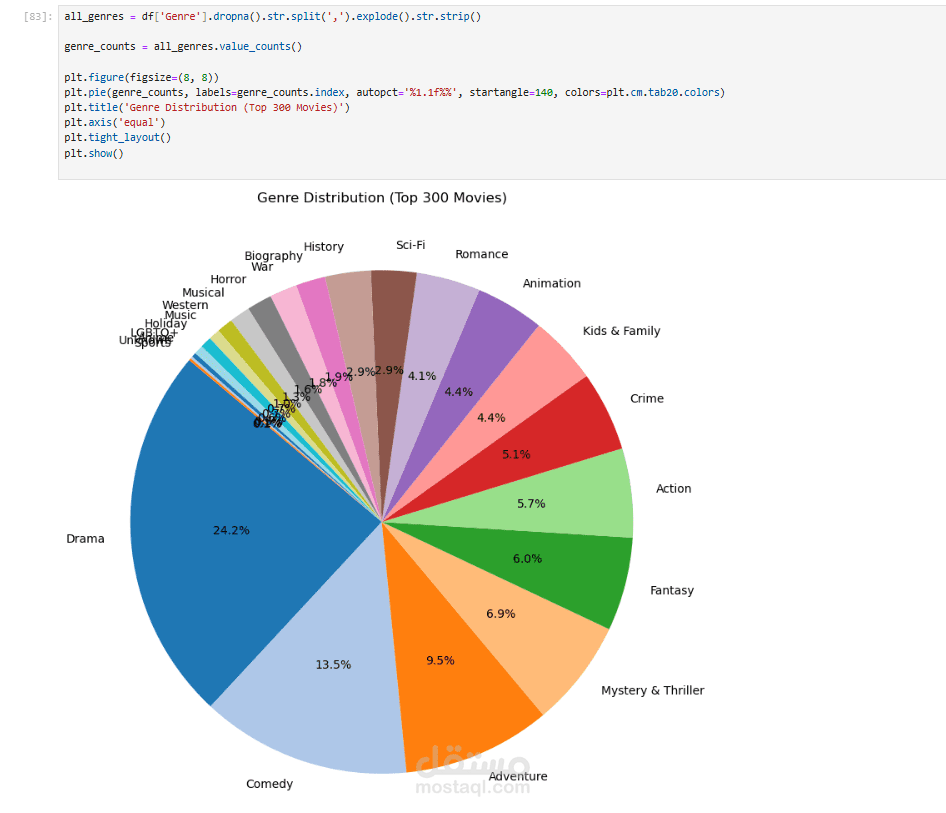
يهدف هذا المشروع إلى جمع وتحليل بيانات الأفلام من موقع Rotten Tomatoes بشكل تلقائي باستخدام لغة Python وتقنيات Web Scraping.
تم الاعتماد على مكتبات مثل:
BeautifulSoup لاستخلاص البيانات من صفحات HTML
Requests للوصول إلى صفحات الموقع
Pandas لتنظيم البيانات وتخزينها في ملفات CSV
خلال المشروع، تم تنفيذ الخطوات التالية:
تحديد الصفحات المستهدفة:
استخراج روابط الأفلام أو صفحات التقييم من Rotten Tomatoes.
جمع البيانات (Scraping):
الحصول على معلومات مثل:
اسم الفيلم
سنة الإصدار
التقييم (Tomatometer & Audience Score)
النوع (Genre)
المدة (Runtime)
المخرج والممثلين
تنظيف البيانات (Data Cleaning):
إزالة القيم الناقصة أو المكررة وتوحيد الصيغ.
تحليل البيانات (Data Analysis):
تحليل الاتجاهات مثل العلاقة بين النوع والتقييم أو تطور التقييمات عبر السنين.
تخزين البيانات:
حفظ النتائج في ملف CSV لاستخدامها لاحقًا في التحليل أو النمذجة.