Amazon Reviews Sentiment Analysis
تفاصيل العمل
نموذج تعلم عميق (LSTM) لتحليل المشاعر بدقة %94 باستخدام بيانات أمازون، مع إمكانية تخصيصه لأي نصوص أو مراجعات أخرى مثل (تويتر – فيسبوك – تعليقات العملاء).
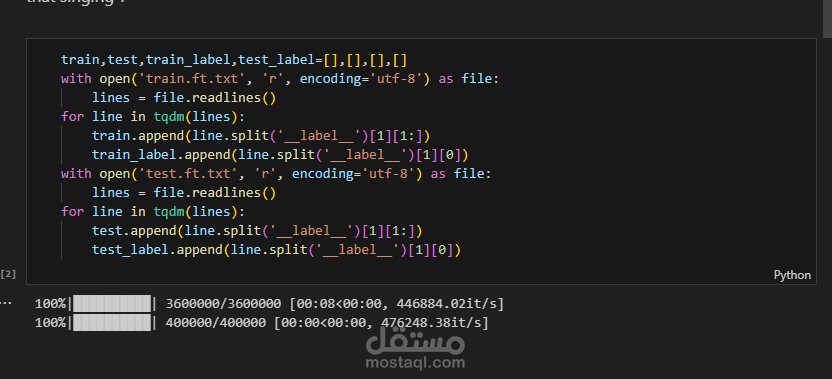
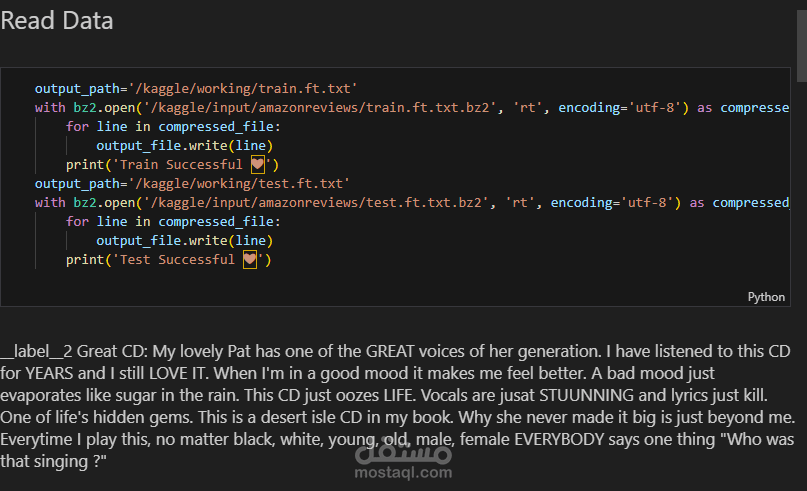
البيانات: Dataset ضخم من Amazon Reviews (بصيغة bz2).
المعالجة المسبقة:
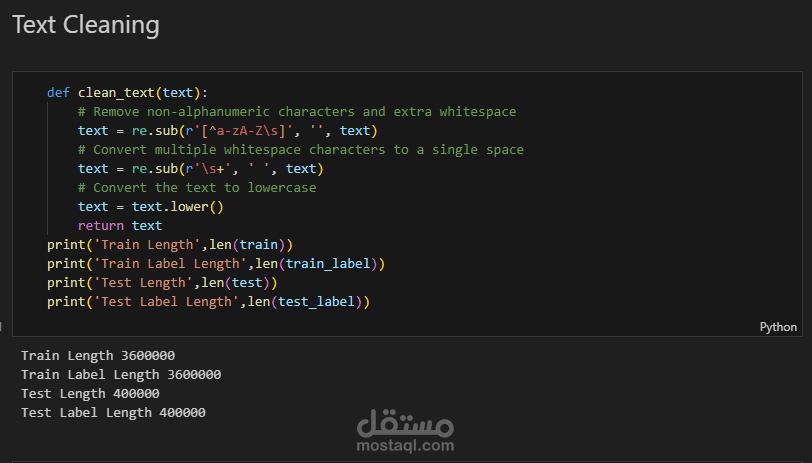
تنظيف النصوص (إزالة الرموز الخاصة، تحويل لحروف صغيرة، إلخ).
تمثيل الكلمات بـ Tokenizer + Padding.
توزيع البيانات Train/Test.
الـ Visualization:
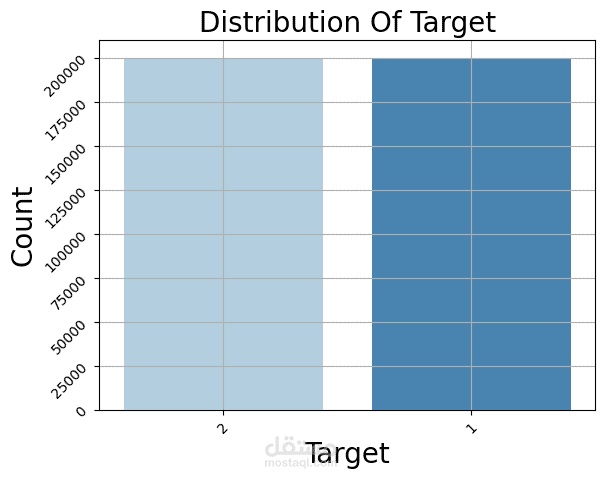
Countplot لتوزيع المشاعر (إيجابي / سلبي).
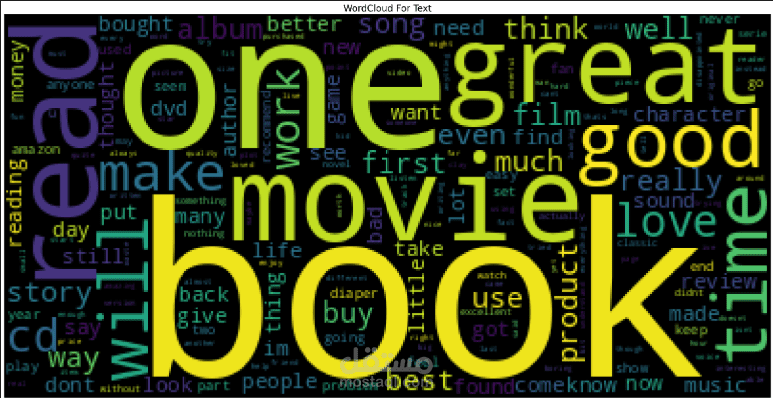
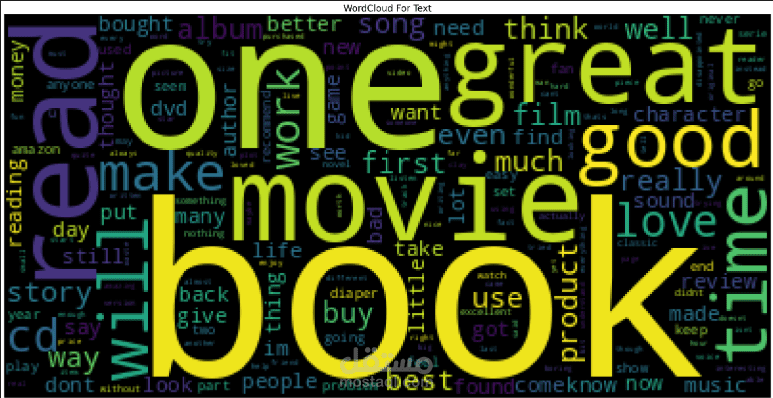
WordCloud للكلمات الأكثر شيوعًا.
النموذج:
Embedding Layer.
طبقتين LSTM مع SpatialDropout.
Dense Layer بالـ softmax لتصنيف ثنائي (إيجابي / سلبي).
التدريب:
Optimizer = Adam.
Loss = SparseCategoricalCrossentropy.
ModelCheckpoint لحفظ أفضل نسخة من الموديل.
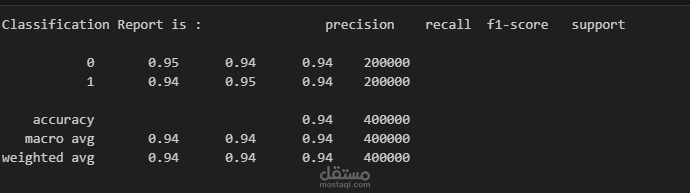
حقق 94% accuracy في تصنيف المراجعات إلى (إيجابي / سلبي).
تم اختبار الموديل على بيانات جديدة (Test Set) وأثبت كفاءة ممتازة.
التقارير المخرجة:
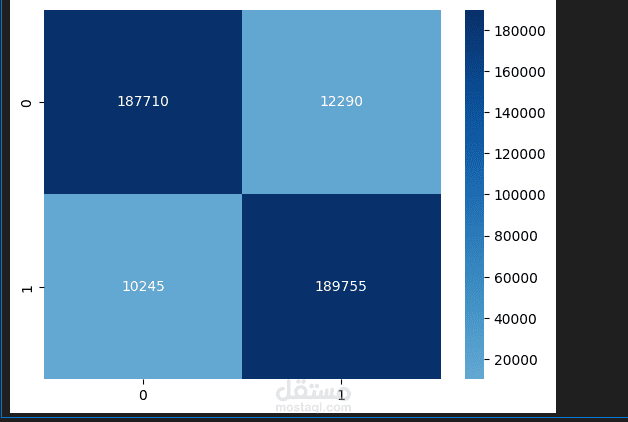
Confusion Matrix لقياس أخطاء التصنيف.
Classification Report (Precision, Recall, F1-score).
WordCloud لتوضيح الكلمات الأكثر شيوعًا في المراجعات.