Arabic_Sentimant_analysis
تفاصيل العمل

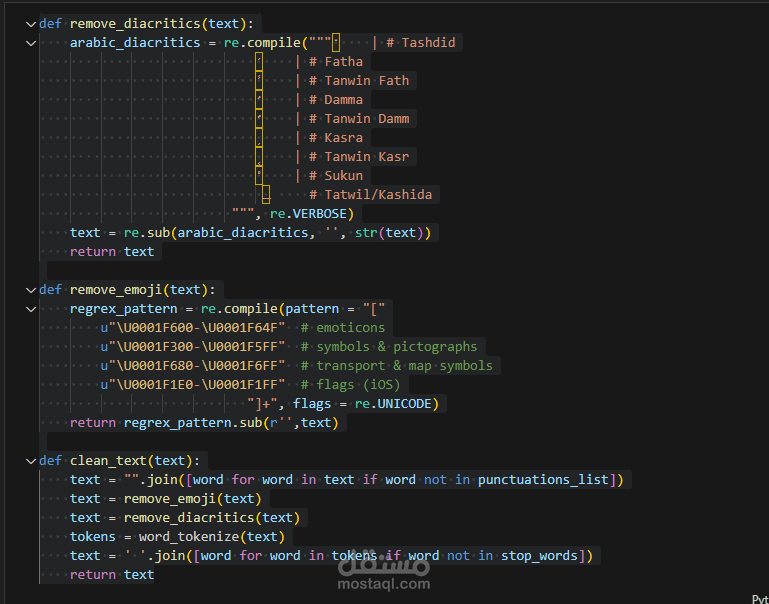
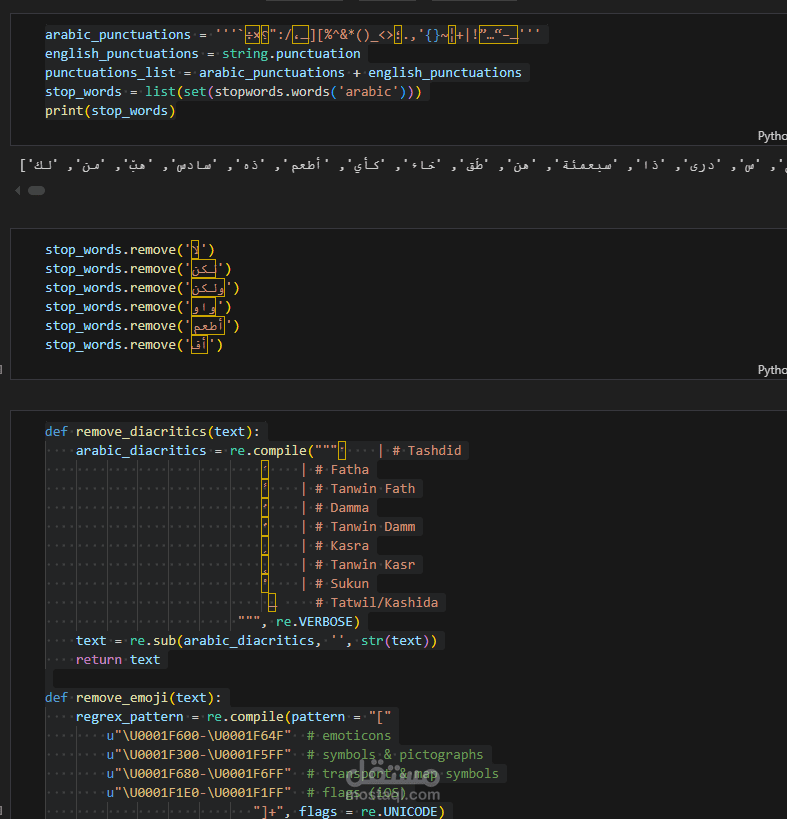
قمت بتنفيذ مشروع عملي لتحليل وتصنيف مراجعات أمازون المكتوبة باللغة العربية باستخدام تقنيات معالجة اللغة الطبيعية (NLP) وخوارزميات تعلم الآلة والذكاء الاصطناعي.
كما أضفت تطبيقًا متقدمًا باستخدام Stacking Classifier لتجميع أكثر من نموذج معًا وتحسين الأداء.
خطوات التنفيذ:
تجهيز البيانات (40 ألف مراجعة):
تنظيف النصوص من الرموز، الإيموجي، التشكيل والكلمات الشائعة.
تجزئة الكلمات (Tokenization) واستخدام Lemmatization للوصول إلى الجذر.
النماذج المجرّبة:
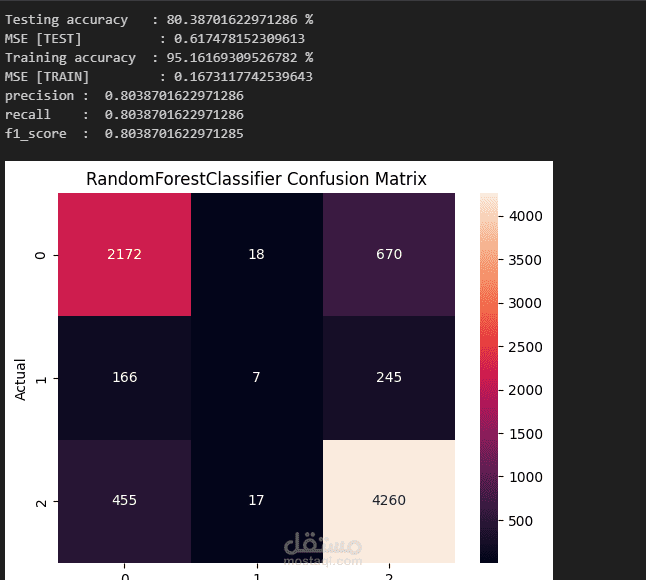
Random Forest Classifier
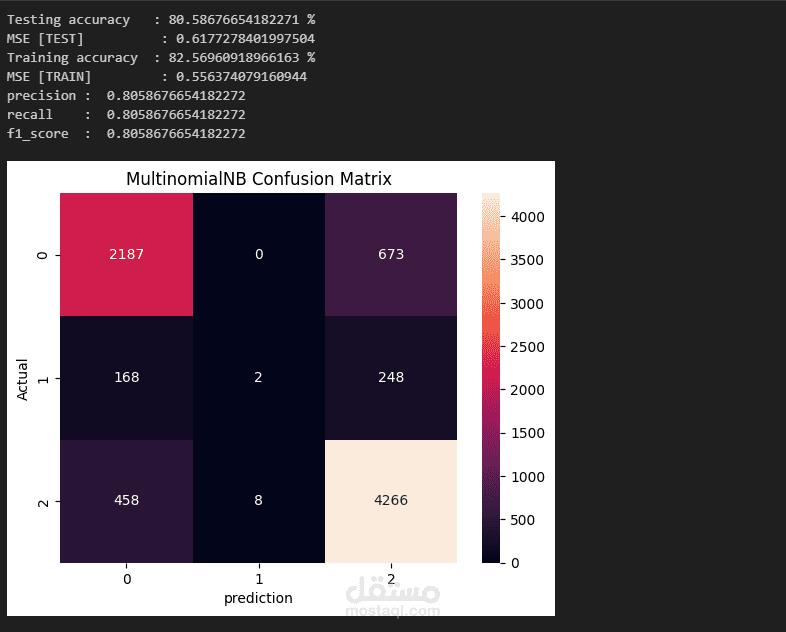
Multinomial Naive Bayes
Linear SVC
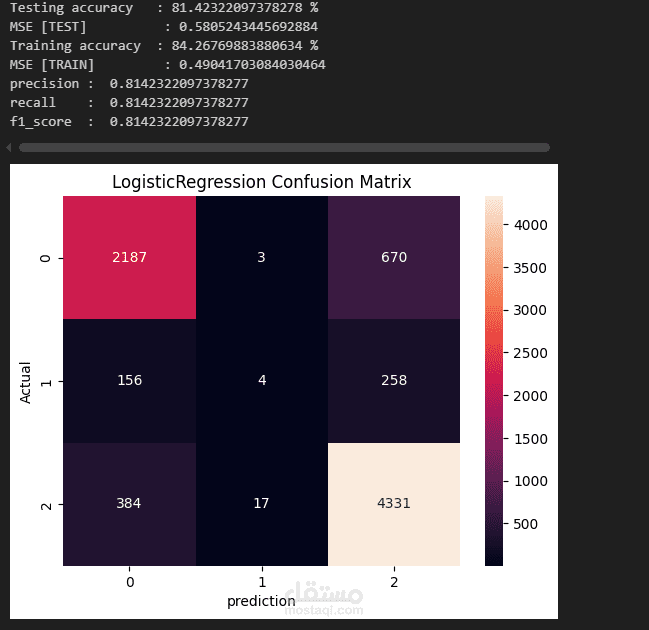
Logistic Regression
تجميع النماذج (Ensemble Learning):
تطبيق Stacking Classifier باستخدام (Linear SVC + Random Forest + Logistic Regression) كنماذج أساسية.
استخدام Logistic Regression كـ Blender لدمج التنبؤات وتحقيق أفضل أداء ممكن.
تقييم النماذج:
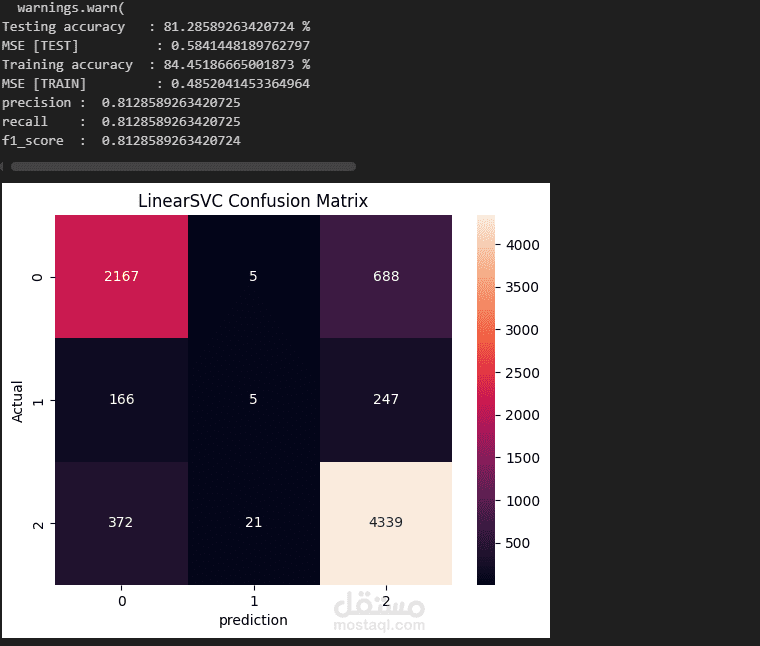
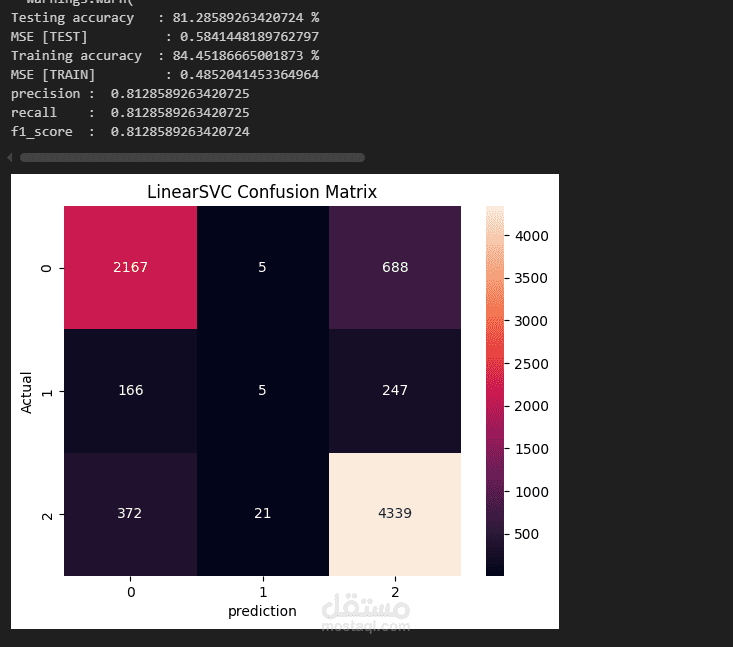
Accuracy, Precision, Recall, F1-score.
Confusion Matrix لعرض النتائج بصريًا.
النتائج:
Linear SVC حقق أفضل أداء فردي بدقة ≈ 81%.
Naive Bayes قريب بنسبة ≈ 80.6%.
Random Forest ظهر عليه Overfitting (95% تدريب، 80% اختبار).
Stacking Classifier حقق دقة إجمالية ≈ 80% مع أداء متوازن.