Big Mart Sales Prediction
تفاصيل العمل
يهدف هذا المشروع إلى تطوير نموذج تعلم آلي (Machine Learning) قادر على توقع المبيعات المستقبلية لكل منتج في كل متجر من متاجر سلسلة "بيج مارت". تم بناء النموذج باستخدام بيانات مبيعات تاريخية، مع الأخذ في الاعتبار خصائص المنتج والمتجر. يعتبر هذا النوع من التوقعات حيوياً لشركات التجزئة لتحسين إدارة المخزون، وتخطيط استراتيجيات التسويق، واتخاذ قرارات عمل مستنيرة.
أهداف المشروع
التحليل الاستكشافي للبيانات (EDA): فهم العوامل الرئيسية التي تؤثر على مبيعات المنتجات.
هندسة الميزات (Feature Engineering): إنشاء ميزات جديدة من البيانات المتاحة لزيادة دقة النموذج.
بناء وتقييم النماذج: تدريب عدة نماذج تعلم آلي مختلفة، ومقارنة أدائها لاختيار النموذج الأفضل.
تقديم رؤى قابلة للتنفيذ: استخلاص نتائج وتوصيات عملية يمكن لإدارة "بيج مارت" استخدامها لتعزيز المبيعات.
الأدوات والتقنيات المستخدمة
لغة البرمجة: Python 3.x
بيئة العمل: Jupyter Notebook
مكتبات تحليل البيانات ومعالجتها:
Pandas: لهيكلة البيانات، وتنظيفها، ومعالجتها.
NumPy: لإجراء العمليات الحسابية بكفاءة.
مكتبات تصوير البيانات (Data Visualization):
Matplotlib و Seaborn: لإنشاء رسوم بيانية ثنائية الأبعاد لفهم توزيعات البيانات والعلاقات بين المتغيرات.
مكتبات تعلم الآلة (Machine Learning):
Scikit-learn: لتنفيذ خطوات مثل تقسيم البيانات، وتجهيزها، وبناء نماذج الانحدار (Regression Models)، وتقييمها.
XGBoost: مكتبة متقدمة لتنفيذ نموذج التعزيز المتدرج (Gradient Boosting)، والذي يُعرف بأدائه العالي في المسابقات والمشاريع العملية.
خطوات ومنهجية التنفيذ
المرحلة الأولى: فهم البيانات والتحليل الاستكشافي
المواصفات: تحميل مجموعة البيانات وفهم كل متغير (عمود) فيها، مثل معرف المنتج، وزنه، محتواه من الدهون، نوعه، سعره، معرف المتجر، سنة تأسيس المتجر، حجمه، موقعه، ونوع المتجر.
طريقة التنفيذ:
تحميل البيانات: تم تحميل بيانات التدريب والاختبار باستخدام مكتبة Pandas.
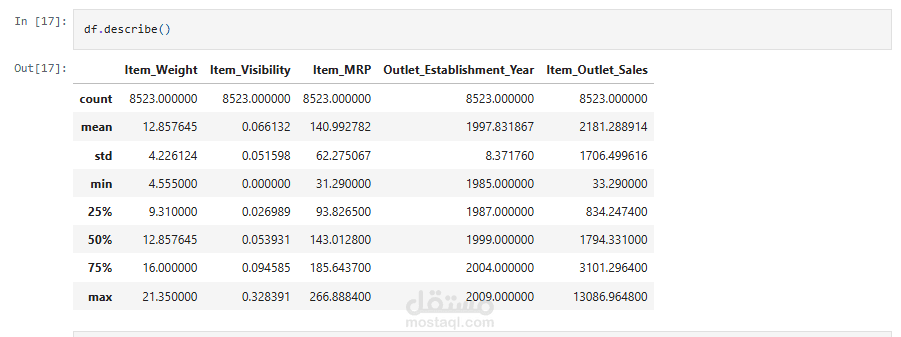
استكشاف أولي: تم استخدام دوال مثل .info(), .describe(), و .shape للحصول على نظرة عامة على البيانات (عدد الصفوف والأعمدة، أنواع البيانات، الإحصائيات الوصفية).
تحليل المتغيرات: تم استخدام الرسوم البيانية لفهم تأثير كل متغير على المبيعات. على سبيل المثال، تم إنشاء رسوم بيانية صندوقية (Box Plots) لمقارنة المبيعات عبر أنواع المتاجر المختلفة، ومخططات التشتت (Scatter Plots) لرؤية العلاقة بين سعر المنتج ومبيعاته.
المرحلة الثانية: تنظيف البيانات وهندسة الميزات
المواصفات: معالجة المشاكل في البيانات مثل القيم المفقودة والمتغيرات الفئوية (Categorical Variables)، وإنشاء ميزات جديدة قد تكون مفيدة للنموذج.
طريقة التنفيذ:
معالجة القيم المفقودة: تم ملاحظة وجود قيم فارغة في عمود "وزن المنتج" وعمود "حجم المتجر". تم ملء القيم المفقودة في الوزن بمتوسط وزن المنتج، والقيم المفقودة في الحجم بالنمط الأكثر تكراراً (mode) لنوع المتجر.
تصحيح البيانات: تم توحيد القيم غير المتناسقة في المتغيرات الفئوية (مثل "Low Fat" و "low fat" و "LF" إلى فئة واحدة).
إنشاء ميزات جديدة: تم إنشاء ميزات إضافية من الميزات الموجودة. على سبيل المثال:
عمر المتجر: تم حسابه بطرح سنة تأسيس المتجر من السنة الحالية.
فئة المنتج: تم استخلاص فئة أوسع للمنتج من أول حرفين في "معرف المنتج".
تحويل المتغيرات الفئوية: بما أن نماذج تعلم الآلة تتطلب مدخلات رقمية، تم تحويل المتغيرات النصية (مثل موقع المتجر ونوعه) إلى أرقام باستخدام تقنية One-Hot Encoding.
المرحلة الثالثة: بناء النماذج وتدريبها
المواصفات: بناء وتقييم عدة نماذج انحدار لتوقع المبيعات.
طريقة التنفيذ:
تقسيم البيانات: تم تقسيم مجموعة البيانات إلى مجموعة تدريب (Training Set) ومجموعة اختبار (Testing Set) للتحقق من أداء النموذج على بيانات لم يرها من قبل.
بناء نموذج أساسي (Baseline Model): تم البدء بنموذج بسيط مثل الانحدار الخطي (Linear Regression) لتحديد خط أساس يمكن مقارنة النماذج الأكثر تعقيدًا به.
تجربة نماذج متقدمة: تم تدريب نماذج أكثر قوة مثل الغابات العشوائية (Random Forest) و XGBoost Regressor. تتميز هذه النماذج بقدرتها على التقاط العلاقات المعقدة وغير الخطية في البيانات.
المرحلة الرابعة: تقييم النموذج واختيار الأفضل
المواصفات: قياس أداء النماذج المختلفة باستخدام مقاييس تقييم مناسبة لمشاكل الانحدار.
طريقة التنفيذ:
مقاييس التقييم: تم استخدام مقياس الجذر التربيعي لمتوسط الخطأ (Root Mean Squared Error - RMSE) كمقياس رئيسي لتقييم النماذج. كلما انخفضت قيمة RMSE، كان أداء النموذج أفضل في توقع قيم قريبة من المبيعات الفعلية.
مقارنة الأداء: تم إنشاء جدول لمقارنة قيم RMSE لكل نموذج على مجموعة الاختبار.
اختيار النموذج النهائي: أظهر نموذج XGBoost أفضل أداء (أقل قيمة RMSE) بفضل قدرته على التعامل مع البيانات المعقدة بكفاءة عالية.
النتائج والتوصيات
النموذج النهائي: تم اعتماد نموذج XGBoost كنموذج نهائي لتوقع المبيعات بدقة عالية.
أهم العوامل المؤثرة: أظهر التحليل أن سعر المنتج (MRP)، نوع المتجر (Outlet_Type)، وحجم المتجر (Outlet_Size) هي من أهم العوامل التي تؤثر بشكل مباشر على حجم المبيعات.
توصيات عملية: بناءً على النتائج، يمكن لـ "بيج مارت" التركيز على تحسين المخزون في المتاجر الكبيرة (Supermarket Type1)، ووضع استراتيجيات تسعير مرنة للاستفادة من تأثير السعر المرتفع على زيادة إجمالي المبيعات.
هذا المشروع يبرز القدرة على تنفيذ دورة حياة مشروع علم البيانات بالكامل، بدءاً من معالجة البيانات الأولية وصولاً إلى بناء نموذج تعلم آلي متقدم وتقديم توصيات تجارية قيمة.