Spotify-Data-Analysis
تفاصيل العمل
هذا المشروع عبارة عن دراسة تحليلية شاملة لمجموعة بيانات مستخرجة من منصة سبوتيفاي، بهدف الكشف عن الأنماط الخفية في الخصائص الصوتية للأغاني، وفهم توجهات الفنانين، وتحليل مدى شعبية الأغاني وارتباطها بخصائصها الموسيقية. تم تنفيذ المشروع بالكامل باستخدام لغة البرمجة بايثون (Python) ومجموعة من المكتبات المتخصصة في التعامل مع البيانات وتحليلها وتصويرها.
أهداف المشروع
تحليل الخصائص الصوتية: دراسة وتوزيع المقاييس الصوتية التي توفرها سبوتيفاي (مثل الراقصية danceability، الطاقة energy، الإيجابية valence، والكلامية speechiness) وفهم كيفية تأثيرها على أنواع الأغاني المختلفة.
استكشاف توجهات الفنانين: تحليل الخصائص الموسيقية لأعمال فنانين محددين ومقارنتها ببعضها البعض لاكتشاف البصمة الفنية لكل منهم.
ربط الشعبية بالخصائص: التحقيق في العلاقة بين مدى شعبية الأغنية (popularity) وخصائصها الصوتية. هل هناك تركيبة معينة من الخصائص تجعل الأغنية أكثر نجاحاً؟
تصوير البيانات: إنشاء رسوم بيانية وتصورات تفاعلية لعرض النتائج والاستنتاجات بشكل واضح وجذاب.
الأدوات والتقنيات المستخدمة
لغة البرمجة: Python 3.x
بيئة العمل: Jupyter Notebook
مكتبات تحليل البيانات:
Pandas: لتنظيم البيانات ومعالجتها وتنظيفها في هياكل بيانات مرنة (DataFrames).
NumPy: لإجراء العمليات الحسابية المتقدمة على المصفوفات.
مكتبات تصوير البيانات (Data Visualization):
Matplotlib: لإنشاء الرسوم البيانية الأساسية والثابتة.
Seaborn: مبنية على Matplotlib وتستخدم لإنشاء تصورات إحصائية أكثر تعقيداً وجاذبية.
Plotly: لإنشاء رسوم بيانية تفاعلية وديناميكية.
واجهة برمجة التطبيقات (API):
Spotipy: مكتبة بايثون للوصول إلى واجهة برمجة تطبيقات سبوتيفاي (Spotify Web API) لجلب البيانات بشكل برمجي وموثوق.
خطوات ومنهجية التنفيذ
المرحلة الأولى: جمع البيانات (Data Acquisition)
المواصفات: استخراج بيانات شاملة لمجموعة من الأغاني، بما في ذلك أسماء الأغاني، الفنانين، الألبومات، تاريخ الإصدار، درجة الشعبية، بالإضافة إلى مجموعة كاملة من الخصائص الصوتية (audio features).
طريقة التنفيذ:
إعداد الوصول لواجهة برمجة التطبيقات: تم إنشاء حساب مطور على منصة سبوتيفاي للحصول على مفاتيح الوصول (Client ID و Client Secret).
استخدام مكتبة Spotipy: تم تهيئة المكتبة باستخدام مفاتيح الوصول.
جلب البيانات: تم استدعاء واجهة برمجة التطبيقات (API) لسحب بيانات قوائم تشغيل (Playlists) شهيرة ومتنوعة لضمان الحصول على عينة بيانات غنية. لكل أغنية في القائمة، تم سحب بياناتها الأساسية وخصائصها الصوتية التفصيلية.
التخزين: تم تجميع كل البيانات المستخرجة وتنظيمها في هيكل بيانات DataFrame باستخدام مكتبة Pandas، تمهيداً للمرحلة التالية.
المرحلة الثانية: تنظيف وإعداد البيانات (Data Cleaning and Preparation)
المواصفات: التأكد من أن البيانات نظيفة، متناسقة، وجاهزة للتحليل. هذه الخطوة حاسمة لضمان دقة النتائج.
طريقة التنفيذ:
فحص القيم المفقودة (Missing Values): تم استخدام دالة isnull().sum() من Pandas للتحقق من وجود أي خلايا فارغة في مجموعة البيانات ومعالجتها.
إزالة البيانات المكررة (Duplicates): تم التحقق من وجود أي أغانٍ مكررة في مجموعة البيانات وإزالتها للحفاظ على سلامة التحليل الإحصائي.
تنسيق البيانات: تم تحويل بعض الأعمدة إلى التنسيق المناسب، على سبيل المثال، تحويل عمود تاريخ الإصدار (release_date) إلى كائن تاريخ ووقت (datetime) لتسهيل التحليلات الزمنية.
المرحلة الثالثة: التحليل الاستكشافي للبيانات (Exploratory Data Analysis - EDA)
المواصفات: الغوص في أعماق البيانات لفهم توزيعاتها، واكتشاف العلاقات بين المتغيرات المختلفة، واستخلاص رؤى أولية.
طريقة التنفيذ:
تحليل إحصائي وصفي: تم استخدام دالة describe() من Pandas للحصول على ملخص إحصائي سريع للخصائص الصوتية (مثل المتوسط، الانحراف المعياري، والربيعيات).
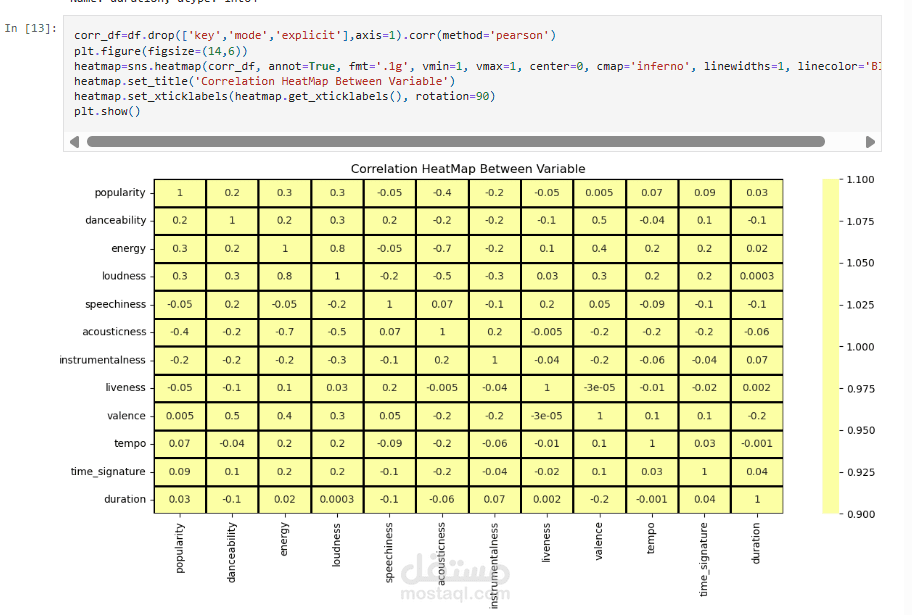
تحليل الارتباط (Correlation Analysis): تم إنشاء مصفوفة ارتباط (Correlation Matrix) باستخدام مكتبة Seaborn لتصوير العلاقة بين جميع الخصائص الصوتية ودرجة الشعبية. على سبيل المثال، تم اكتشاف وجود ارتباط إيجابي قوي بين energy و loudness (الصخب)، وارتباط سلبي بين energy و acousticness (الصوتية).
تحليل توزيع الخصائص: تم استخدام المدرجات التكرارية (Histograms) والرسوم البيانية للكثافة (Density Plots) لفهم كيفية توزيع قيم الخصائص الصوتية المختلفة عبر جميع الأغاني.
المرحلة الرابعة: تصوير البيانات واستخلاص النتائج (Data Visualization and Insights)
المواصفات: تحويل الأرقام والتحليلات إلى تصورات مرئية سهلة الفهم وقادرة على سرد قصة واضحة.
طريقة التنفيذ:
مقارنة خصائص الفنانين: تم استخدام الرسوم البيانية الشريطية (Bar Charts) لمقارنة متوسط قيم الخصائص الصوتية (مثل الطاقة والإيجابية) بين فنانين مختلفين، مما أبرز التباين في أسلوبهم الموسيقي.
العلاقة بين الخصائص: تم استخدام مخططات التشتت (Scatter Plots) لاستكشاف العلاقة بين خاصيتين، مثل العلاقة بين "الراقصية" و "الإيجابية"، مع تلوين النقاط بناءً على درجة الشعبية.
تطور الموسيقى عبر الزمن: تم تجميع الأغاني حسب سنة الإصدار وحساب متوسط الخصائص الصوتية لكل سنة، ثم تم استخدام الرسوم البيانية الخطية (Line Charts) لتوضيح كيف تطورت خصائص الموسيقى الشعبية على مر العقود.
النتائج الرئيسية
تم تحديد السمات الصوتية الأكثر شيوعاً في الأغاني التي تحقق شعبية عالية، حيث لوحظ ميل الأغاني الناجحة لأن تكون ذات طاقة وراقصية أعلى.
تم الكشف عن بصمات موسيقية مميزة لبعض الفنانين من خلال تحليل خصائص أغانيهم.
أظهر التحليل الزمني تغيراً ملحوظاً في "صوت" الموسيقى الشعبية، حيث أصبحت الأغاني الحديثة أكثر صخباً وأقل صوتية مقارنة بالأغاني القديمة.
هذا المشروع لا يعرض فقط القدرة على التعامل مع البيانات من الألف إلى الياء، بل يوضح أيضاً الشغف بتحويل البيانات الأولية إلى رؤى قيمة وقصة متكاملة.