speech-to-text
تفاصيل العمل
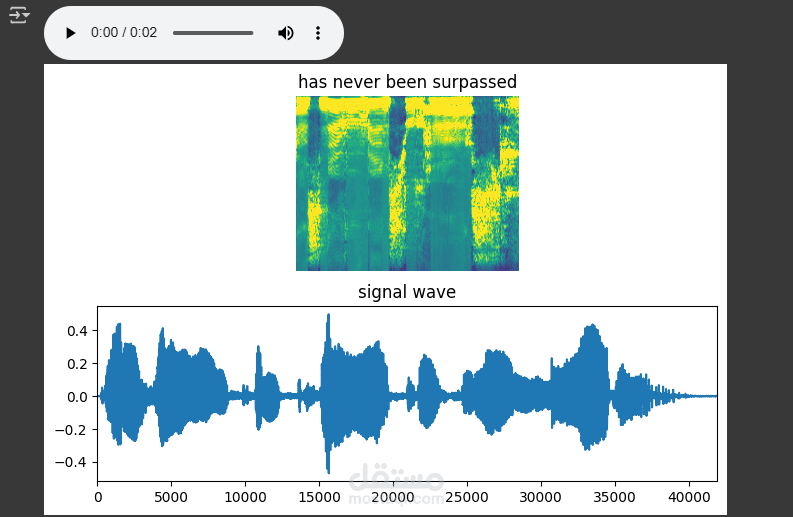
ينفث ها المشروع ننظم التدرف التدلقي علي الكلام (ASR) في بايثون باستددام TensorFlow/Keras. يقوم بتدريب نمودج يشبه DeepSpeech2 علي مجموعة بيانات LJSpeech لتحويل سوت الكلام الى نسج ناصية.
الميزات:
المعالجة المسبقة: تطبيع الصوت، وتوليد الطيف (STFT).
الترميز على مستوى الأحرف باستخدام StringLookup.
وظيفة فقدان CTC مخصصة للتدريب من تسلسل إلى تسلسل.
هندسة مستوحاة من DeepSpeech2:
الطبقات التلافيفية
وحدات GRU ثنائية الاتجاه
مخرج سوفت ماكس متصل بالكامل
تقييم النموذج باستخدام معدل خطأ الكلمات (WER).
تصور المخططات الطيفية والإشارات الصوتية.