extroverts or introverts
تفاصيل العمل
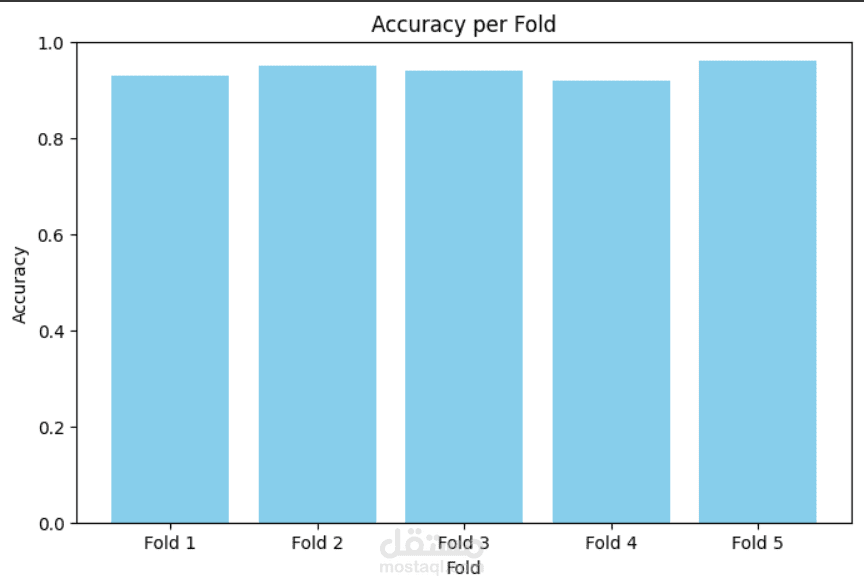
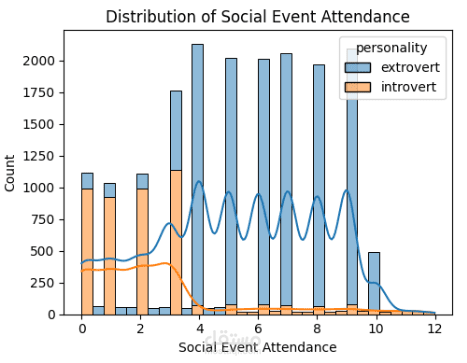
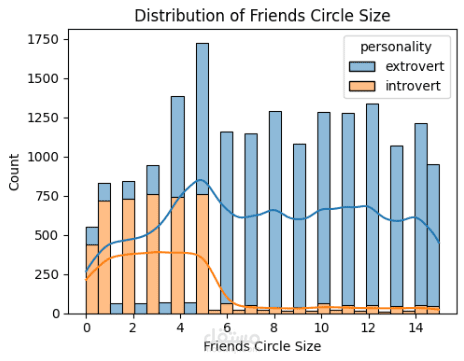
هذا المشروع كان بمثابة غوص عميق في التعامل مع تحديات التعلم الآلي في العالم الحقيقي، وخاصة مشكلة عدم توازن البيانات (Class Imbalance)، تقييم النماذج، وهندسة الخصائص (Feature Engineering).
النقاط التقنية البارزة:
بناء نموذج تصنيف باستخدام Random Forest Classifier من مكتبة scikit-learn.
معالجة مشكلة عدم توازن البيانات باستخدام SMOTE (Synthetic Minority Over-sampling Technique) لتحسين قدرة النموذج على التعميم.
استخدام class_weight='balanced' لجعل النموذج أكثر حساسية للفئة الأقل تمثيلًا.
ضبط عتبة التنبؤ (Prediction Threshold) لزيادة معدل الاستدعاء (Recall) لفئة العملاء المهددين بترك الخدمة (Churn Class)، والتي كانت محور الاهتمام التجاري.
تقييم أداء النموذج باستخدام مصفوفة الالتباس (Confusion Matrix)، تقرير التصنيف (Classification Report)، ورسوم بيانية مثل ROC Curve و Precision-Recall Curve.
النتائج:
الدقة (Accuracy): 79%
معدل الاستدعاء (Recall) لفئة العملاء المهددين بترك الخدمة (Churn = 1): 70%
تحسين قدرة النموذج على اكتشاف العملاء المهددين بترك الخدمة دون التضحية بالكثير من الدقة (Precision).