information retervial
تفاصيل العمل
Project Title: Information Retrieval System
Summary:
This project focuses on designing and developing an Information Retrieval (IR) system capable of efficiently searching and retrieving relevant documents based on user queries. The goal is to simulate how modern search engines work by applying fundamental IR techniques such as indexing, tokenization, term weighting (TF-IDF), and ranking algorithms like cosine similarity.
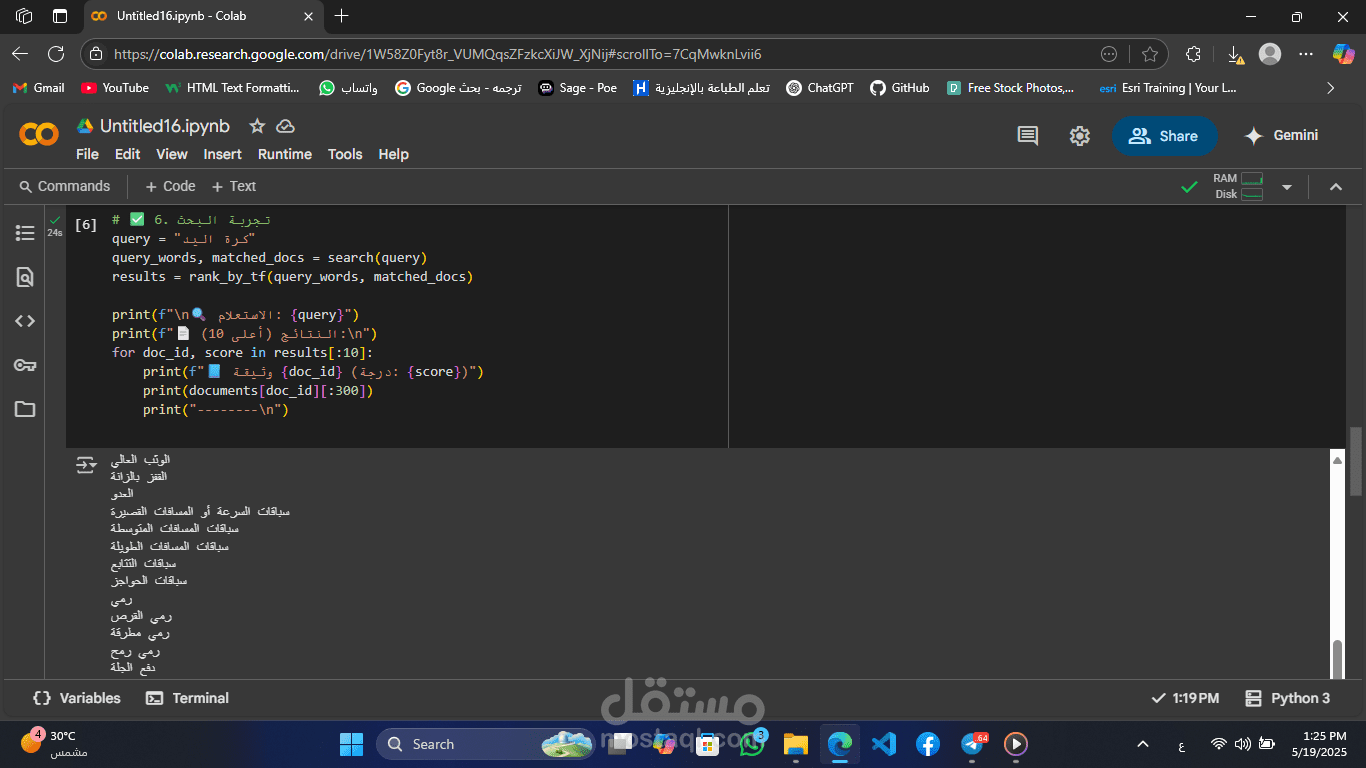
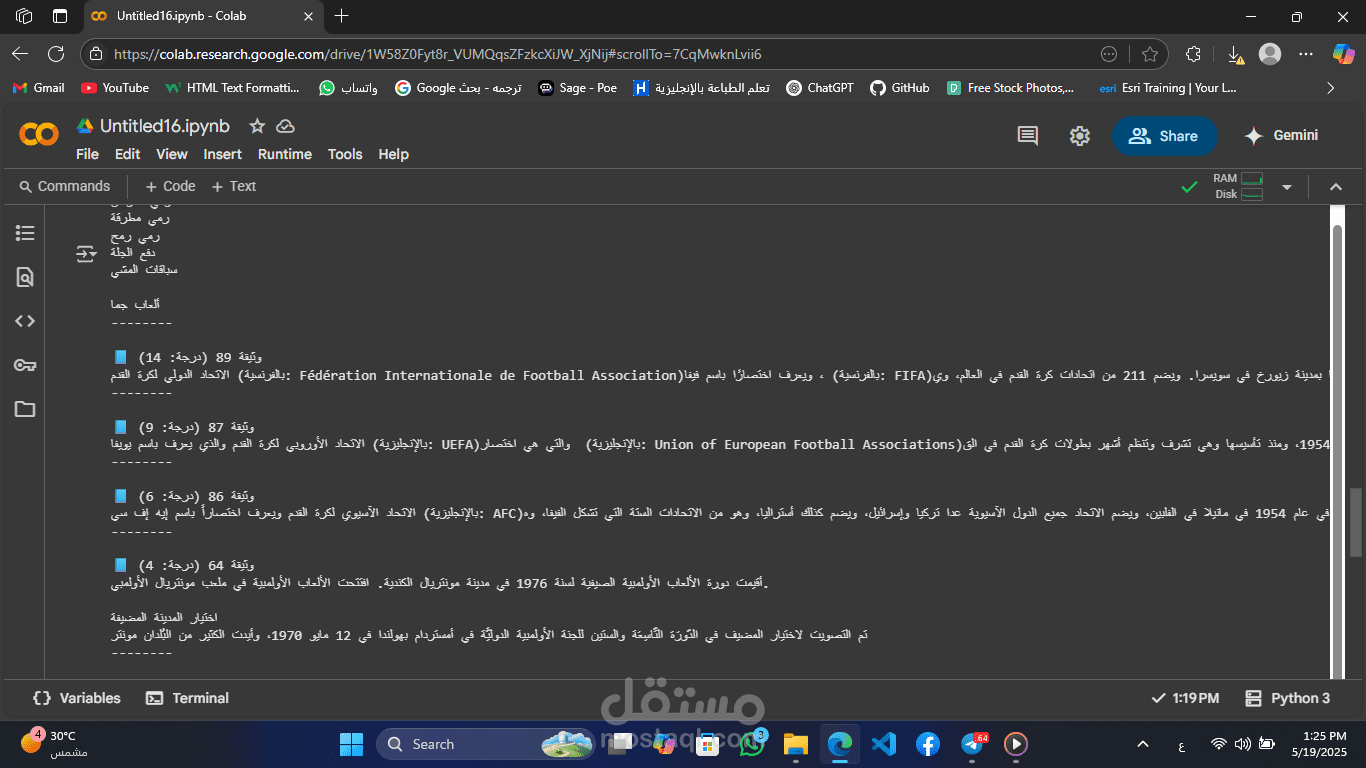
The system allows users to enter a search query and returns a ranked list of the most relevant documents from a predefined dataset. It supports basic preprocessing steps including stop-word removal, stemming, and case normalization to improve retrieval performance.
Technologies and Tools Used:
Programming Language: Python
Libraries: NLTK, Scikit-learn, NumPy, Pandas
Techniques: Vector Space Model, TF-IDF, Cosine Similarity
Dataset: Custom or publicly available text documents
Outcome:
The project demonstrates how IR models can be implemented from scratch and how query-document relevance is computed. It also provides insights into improving search relevance and performance, laying the groundwork for more advanced systems like web search engines.