Image Caption Generator
تفاصيل العمل
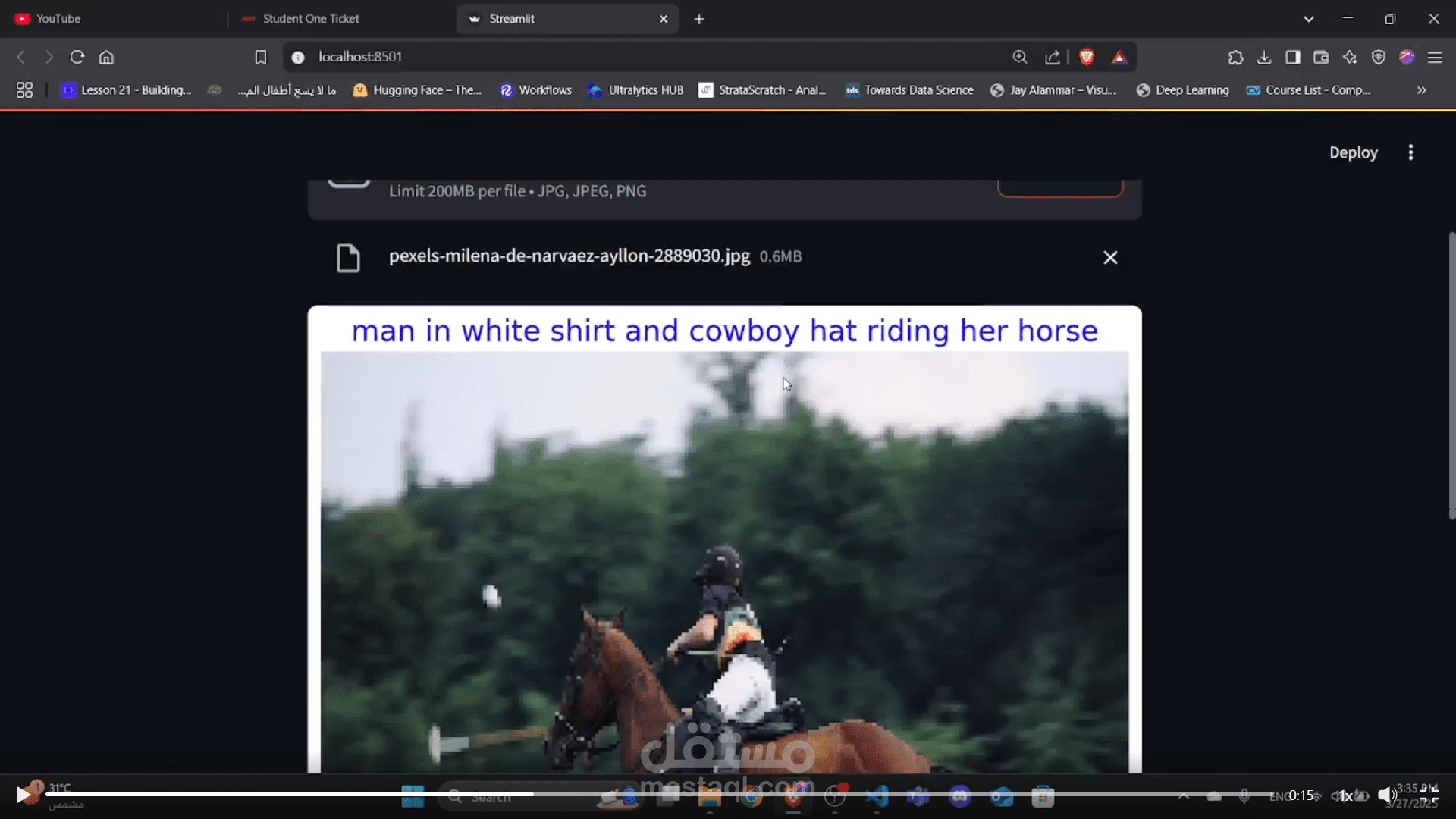
داة تعتمد على التعلم العميق لإنشاء وصف نصي للصور، باستخدام مزيج من الشبكات العصبية الالتفافية (CNNs) والشبكات العصبية التكرارية (RNNs).
تم تطويرها بلغة Python، بالاعتماد على TensorFlow، ونموذج VGG16 لاستخراج الميزات البصرية، وLSTM لإنشاء النصوص، مع نشرها عبر Streamlit لتوفير واجهة تفاعلية. تم تدريب النموذج على مجموعة بيانات Flickr8k.
الميزات:
- استخراج ميزات الصور: يستخدم نموذج VGG16 المدرب مسبقًا لاستخراج الميزات البصرية من الصور.
- توليد أوصاف نصية: يعتمد على نموذج LSTM لإنشاء أوصاف طبيعية بلغة بشرية.
- واجهة ويب تفاعلية: يتيح للمستخدمين رفع الصور وعرض الأوصاف التي يتم إنشاؤها عبر Streamlit.
- التصور المرئي: يعرض الصور المرفوعة إلى جانب الأوصاف التي أنشأها الذكاء الاصطناعي.