Recommendation System ( for Movies)
تفاصيل العمل

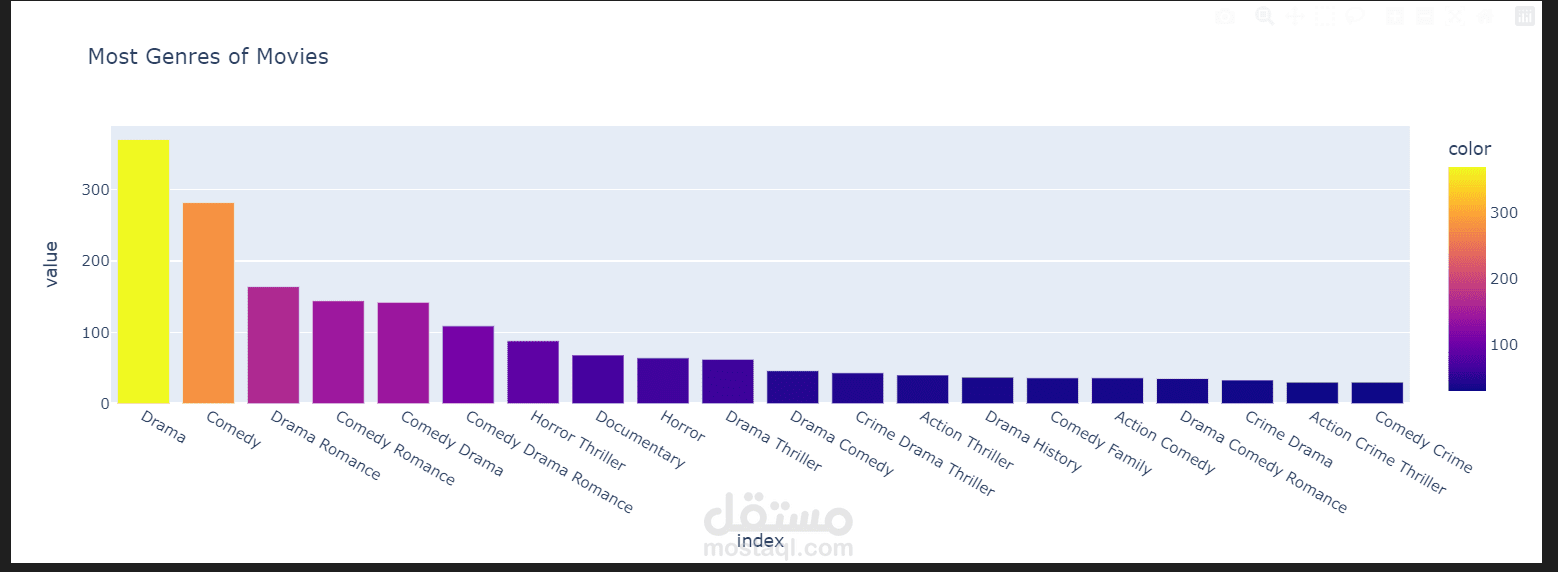

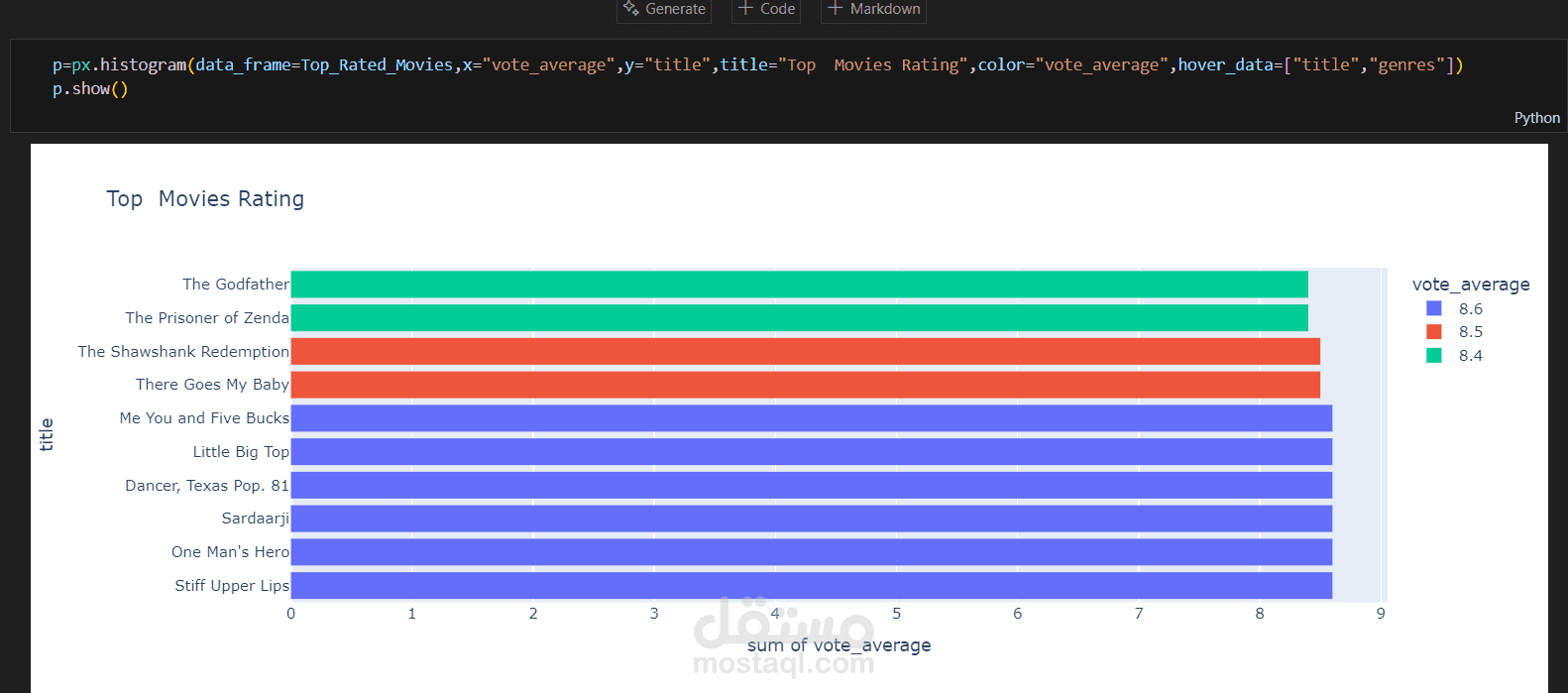
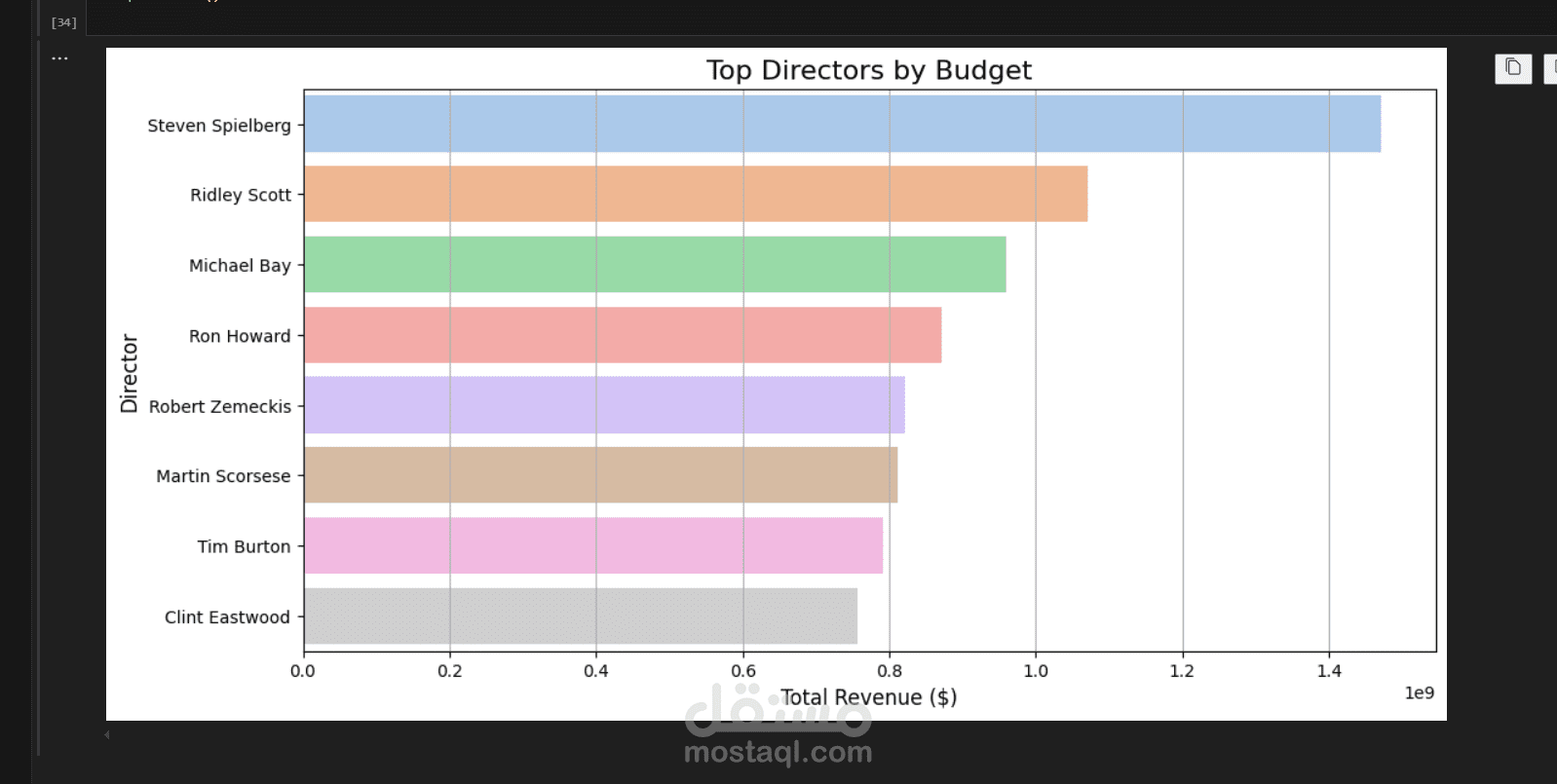
هذا المشروع يقدم نظام توصية أفلام متقدم يعتمد على تقنيات الذكاء الاصطناعي والتعلم الآلي، حيث يجمع بين النهج التعاوني (Collaborative Filtering) والنماذج المُدرَّبة مسبقًا (Pretrained Models) لتقديم توصيات دقيقة وشخصية للمستخدمين.
المكونات الرئيسية للنظام
1. تحليل البيانات واستكشافها
تحميل مجموعة بيانات الأفلام وتنظيفها
معالجة القيم المفقودة وإزالة التكرارات
تحليل التوزيعات الإحصائية للميزات الرقمية
تصور البيانات لفهم العلاقات بين المتغيرات
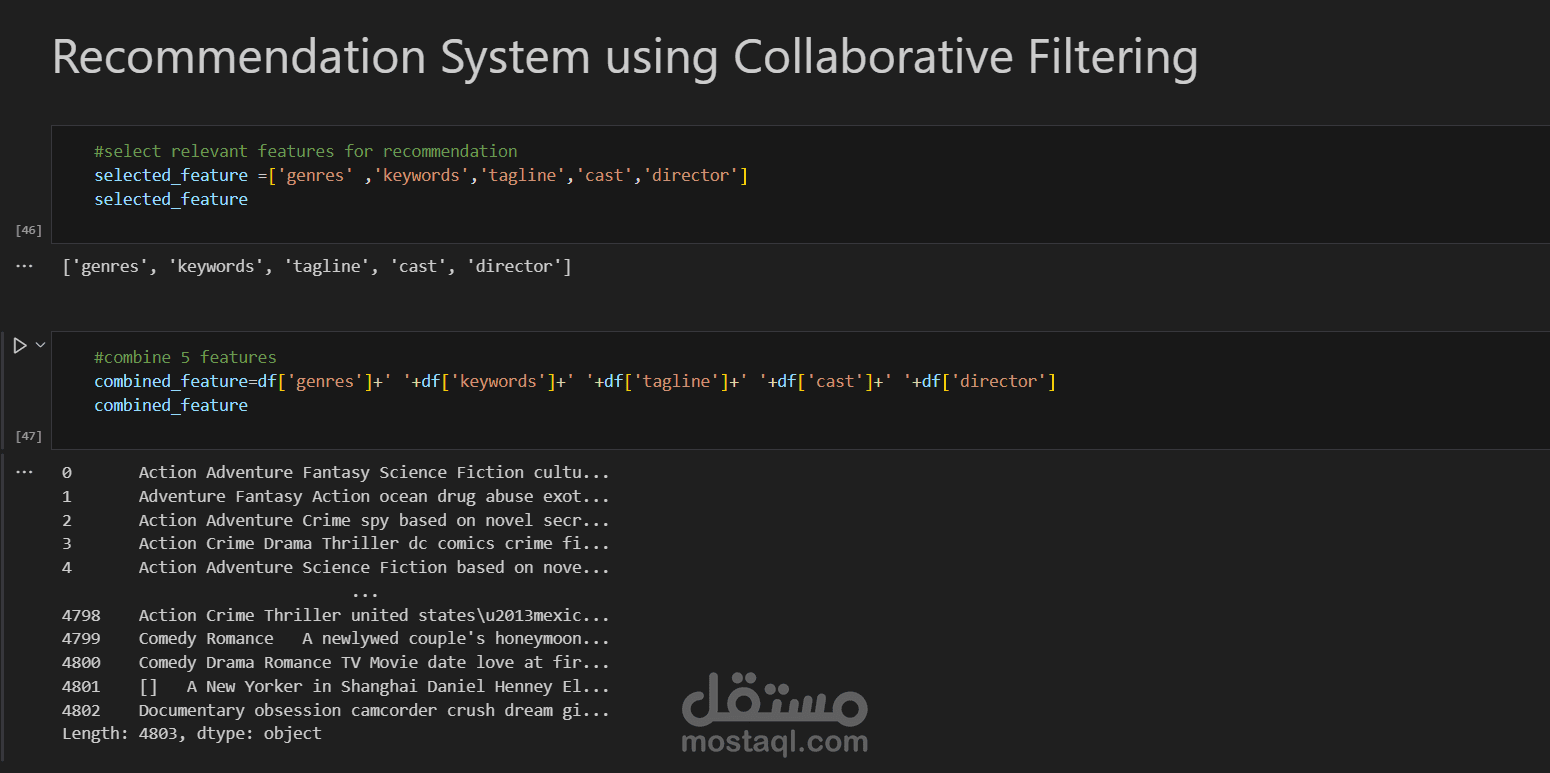
2. معالجة الميزات (Feature Engineering)
تحويل النصوص إلى تمثيلات عددية باستخدام TF-IDF
ترميز الفئات (Label Encoding)
تطبيع البيانات (MinMax Scaling)
معالجة الأعمدة متعددة التسميات (Multi-label Binarization)
3. نماذج التوصية المستخدمة
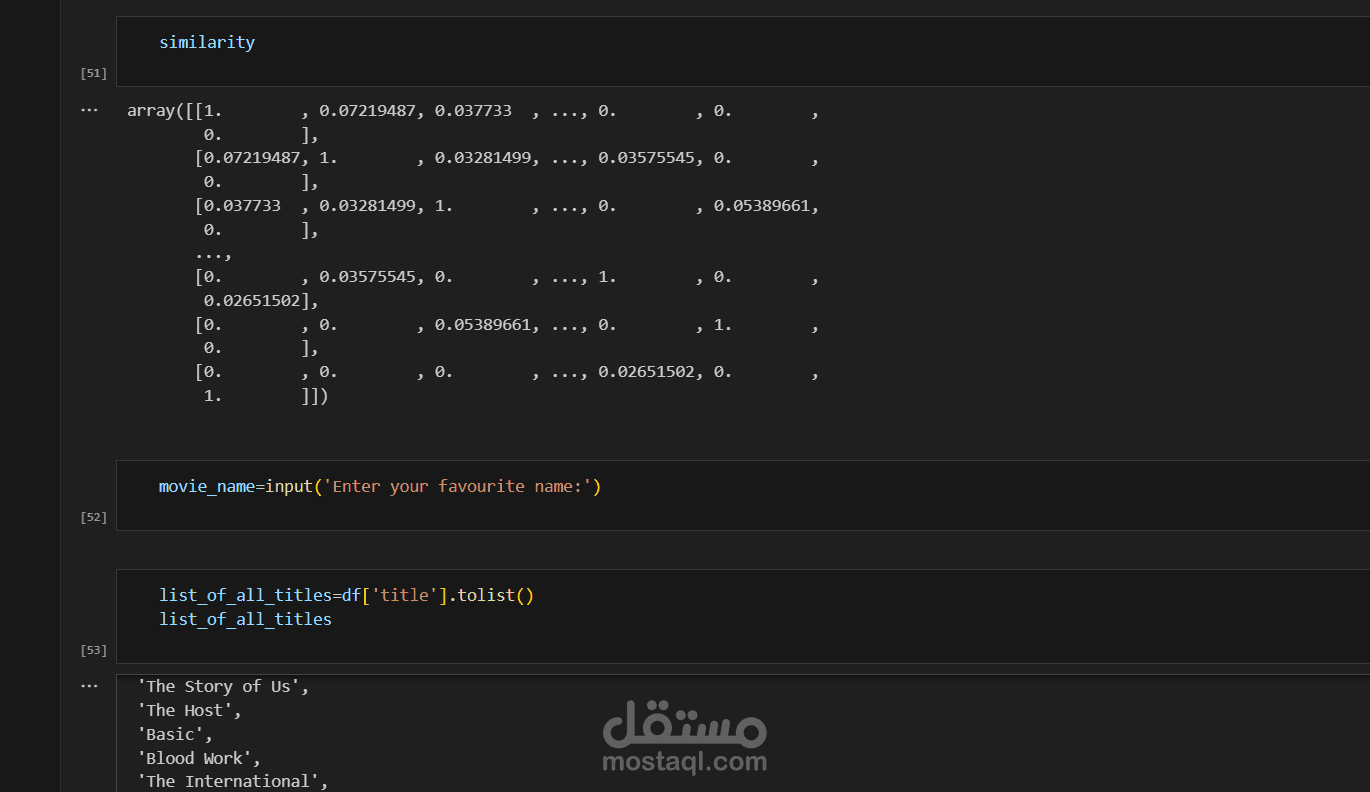
النموذج التعاوني (Collaborative Filtering)
يعتمد على تقييمات المستخدمين للأفلام
يستخدم تشابه جيب التمام (Cosine Similarity) لإيجاد أفلام متشابهة
يأخذ في الاعتبار تفضيلات المستخدمين المتشابهين
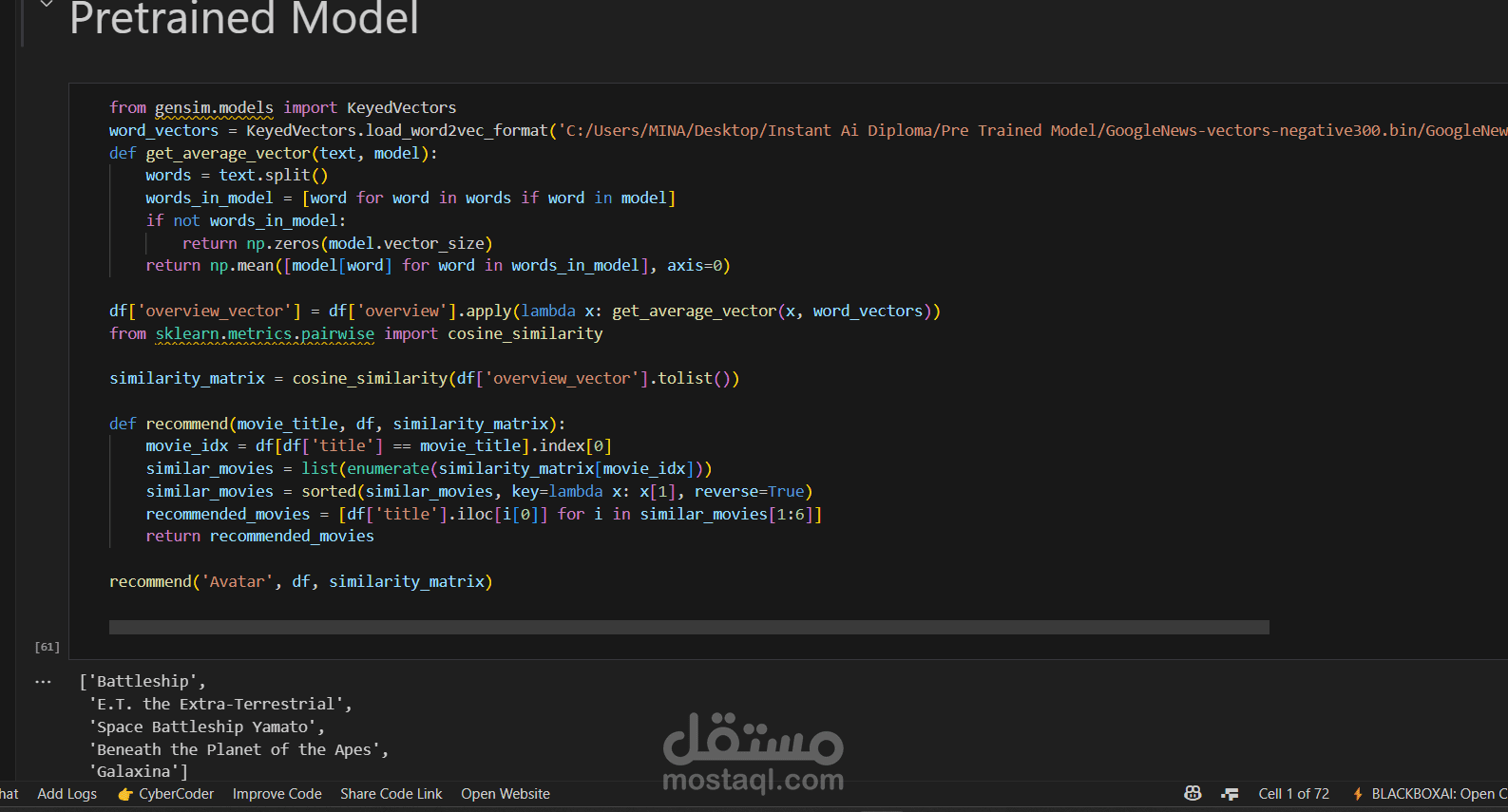
النماذج المُدرَّبة مسبقًا
نموذج الغابة العشوائية (Random Forest Regressor)
نموذج K-means للتجميع
نماذج Word2Vec المُدرَّبة مسبقًا لتمثيل النصوص
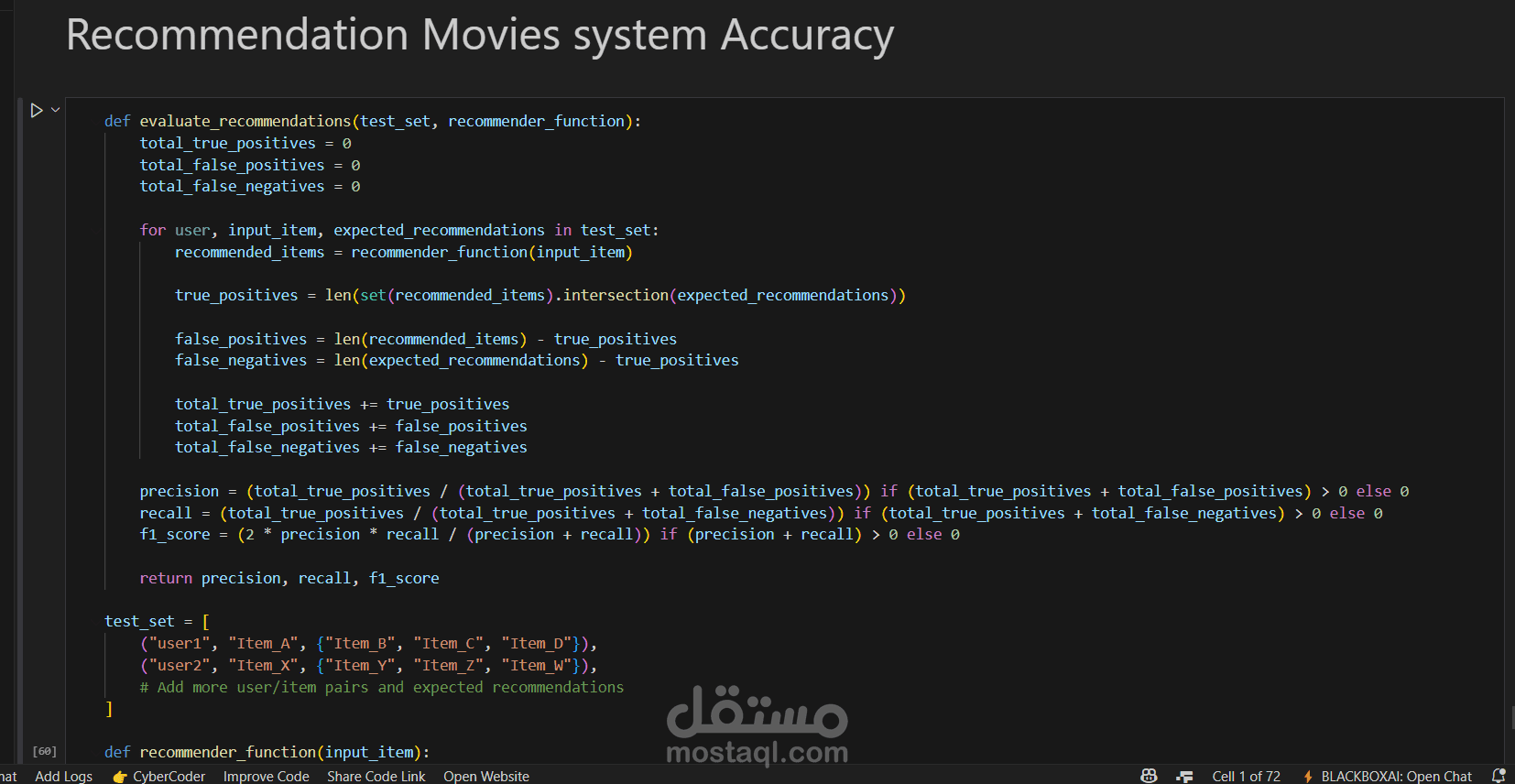
4. تقييم النماذج
استخدام مقاييس مثل:
متوسط الخطأ المطلق (MAE)
متوسط الخطأ التربيعي (MSE)
دقة التصنيف (Accuracy)
معامل التحديد (R2 Score)
ميزات النظام الفريدة
توصيات متعددة الأبعاد: يجمع بين محتوى الأفلام وتقييمات المستخدمين
معالجة متقدمة للنصوص: لتحليل أوصاف الأفلام والعناصر الأخرى
تحسين المعايير: استخدام GridSearchCV لضبط معايير النماذج
تصور البيانات: لوحات معلومات تفاعلية لفهم الأنماط في البيانات
كيفية استخدام النظام
يقوم المستخدم بإدخال فيلم مفضل
يحسب النظام التشابه بين الأفلام بناءً على:
المحتوى (النوع، الكلمات المفتاحية، الطاقم)
التقييمات (متوسط التقييم، عدد التقييمات)
يعرض قائمة بالأفلام الأكثر تشابهًا مع تفضيلات المستخدم
التقنيات المستخدمة
لغة البرمجة: Python
المكتبات الرئيسية:
Pandas, NumPy للتعامل مع البيانات
Scikit-learn للتعلم الآلي
Matplotlib, Seaborn للتصورات
Plotly للوحات التفاعلية
Gensim لنماذج تمثيل الكلمات
الفائدة المتوقعة
يقدم هذا النظام تجربة شخصية للمستخدمين، حيث يساعدهم في اكتشاف أفلام جديدة تناسب أذواقهم بناءً على تاريخ مشاهداتهم وتقييماتهم، مما يحسن تجربة المستخدم ويزيد من مشاركته في المنصة.