Customer Behaviour Segmentation
تفاصيل العمل
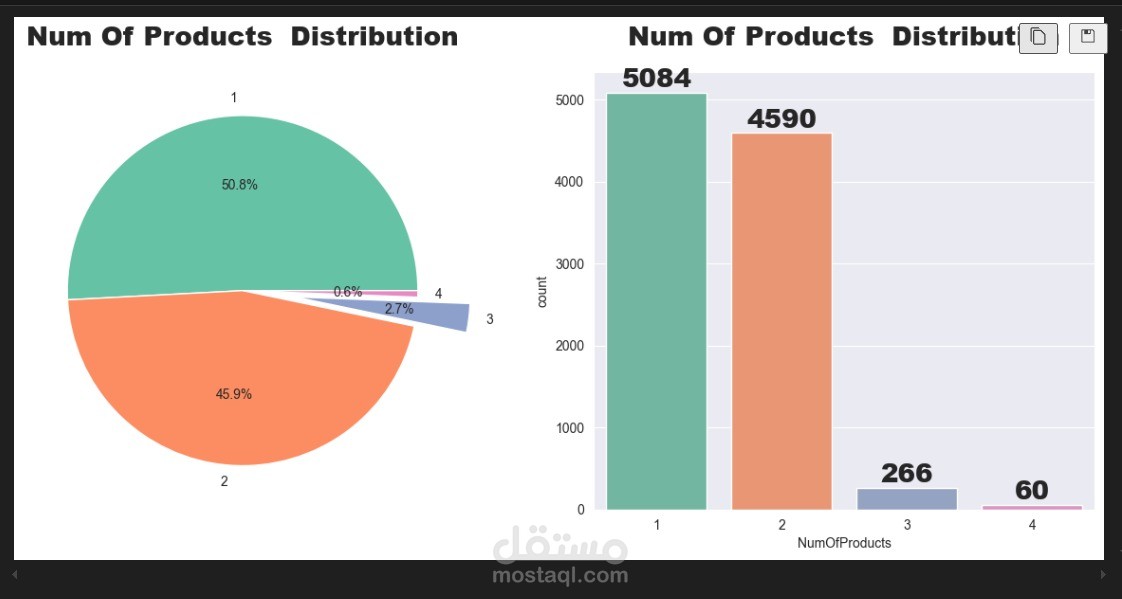
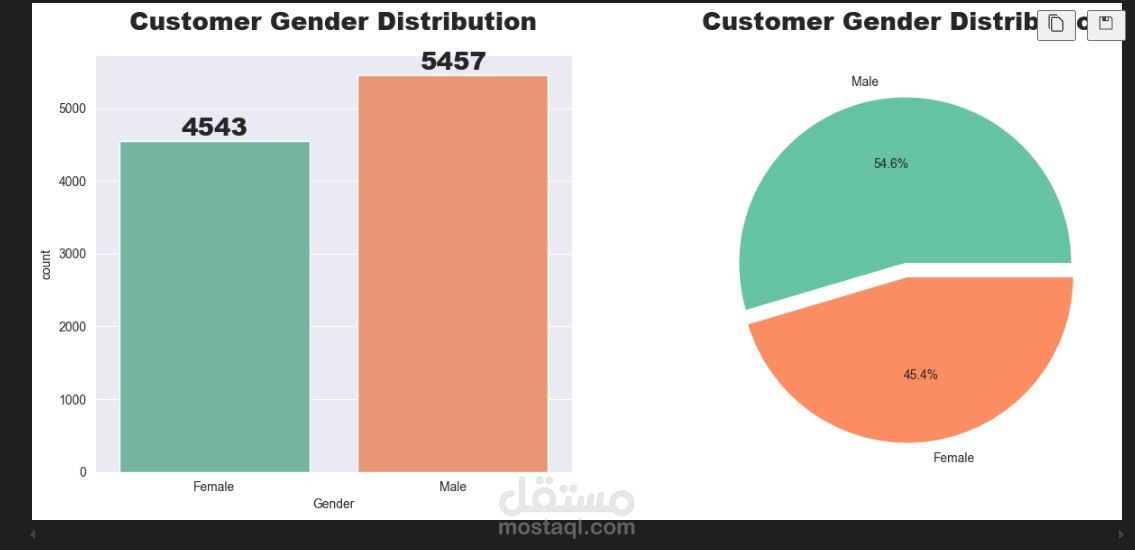
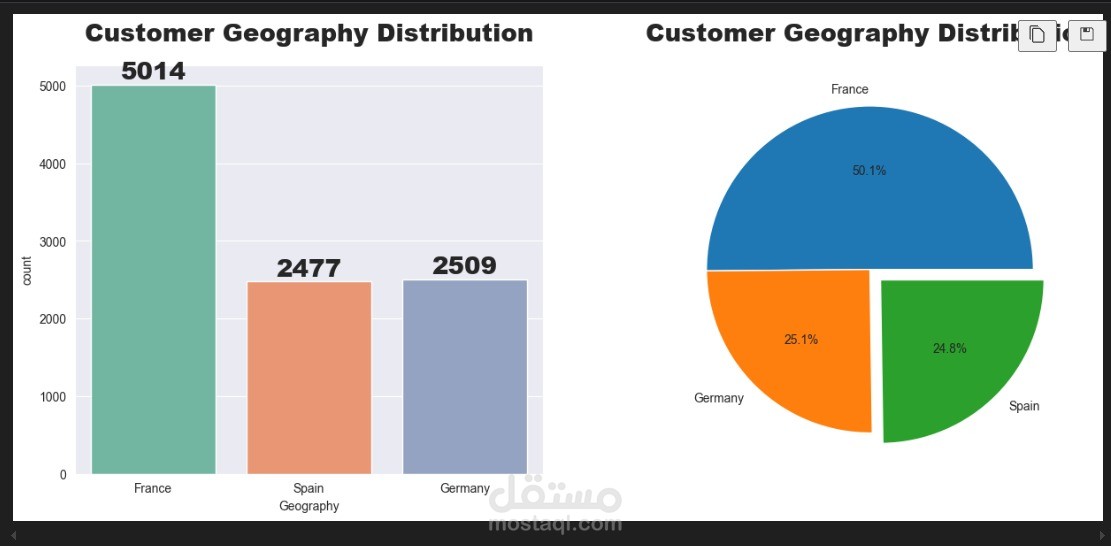
يهدف هذا المشروع إلى تحليل بيانات مغادرة العملاء (Churn) والتنبؤ باحتمالية مغادرة العميل للبنك. تم تنفيذ هذا المشروع باستخدام لغة البرمجة بايثون ومكتبات علم البيانات الشائعة مثل Pandas، Seaborn، Scikit-learn، بالإضافة إلى تطبيق العديد من نماذج التصنيف المتقدمة.
خطوات تنفيذ المشروع:
استيراد المكتبات:
استخدام مكتبات مثل: Pandas، NumPy، Matplotlib، Seaborn، وScikit-learn لتحليل البيانات وبناء النماذج.
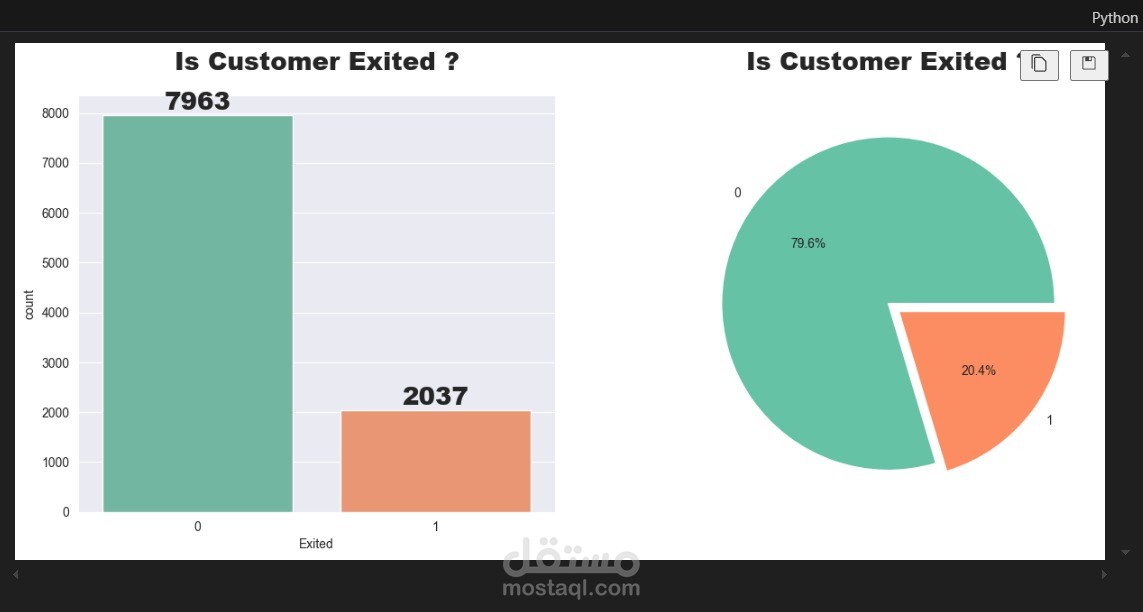
استكشاف البيانات (EDA):
تحميل مجموعة البيانات (Churn_Modelling.csv).
معاينة البيانات ومعرفة أنواع الأعمدة وعدد القيم المفقودة والمكررة.
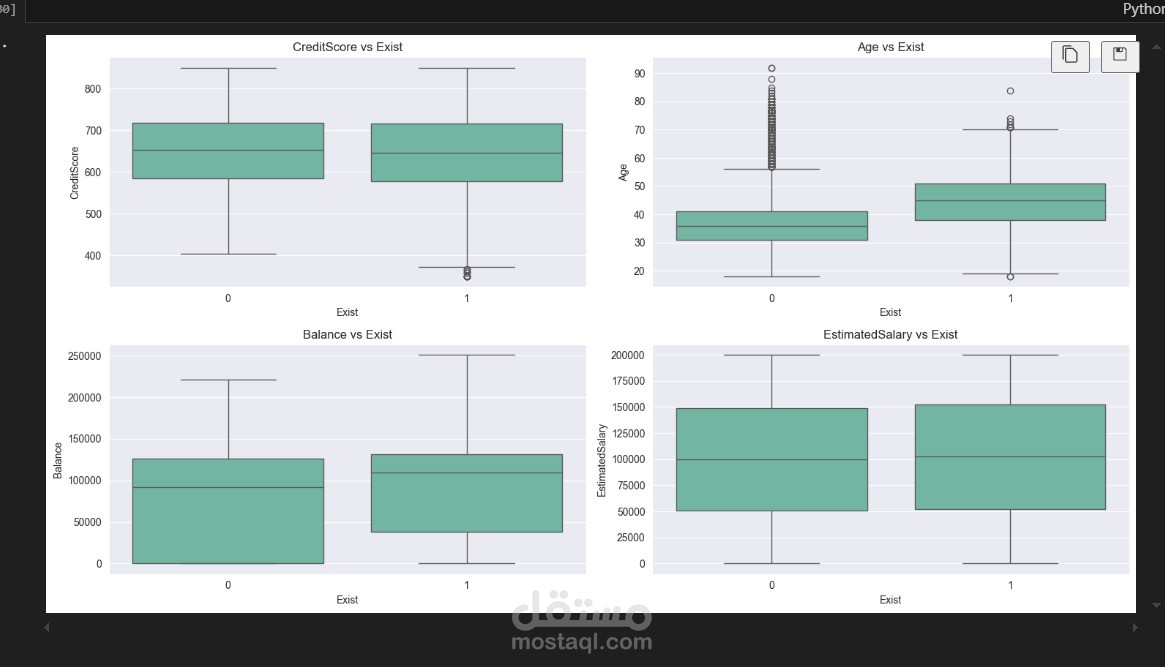
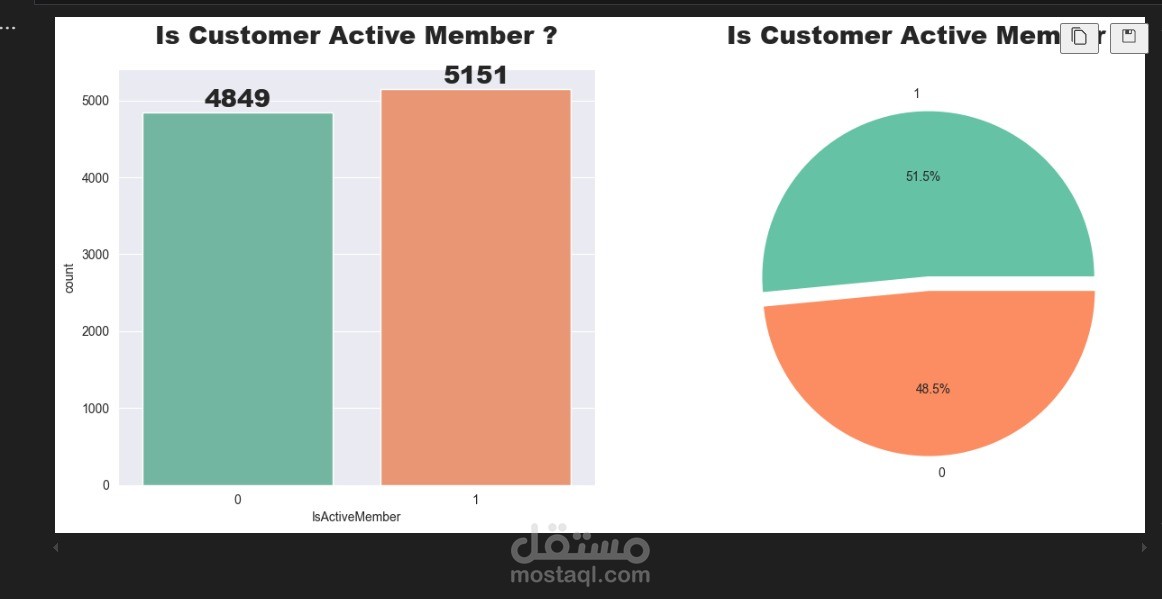
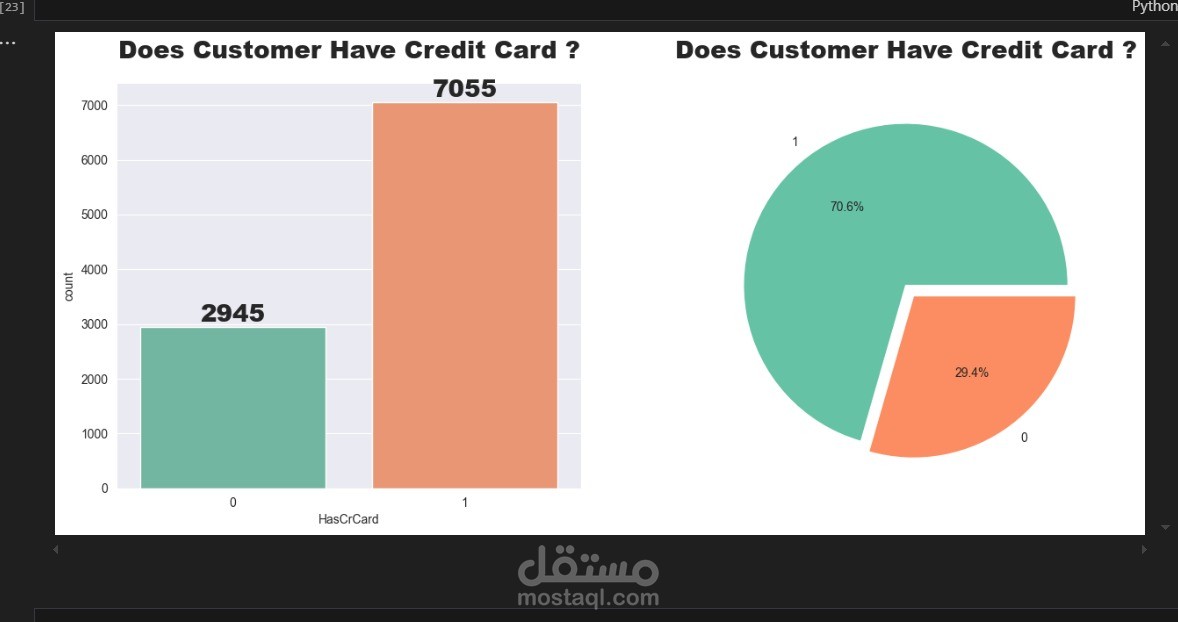
دراسة الإحصائيات الوصفية لمتغيرات مثل الرصيد (Balance)، العمر (Age)، الدخل التقديري (Estimated Salary)، وغيرها.
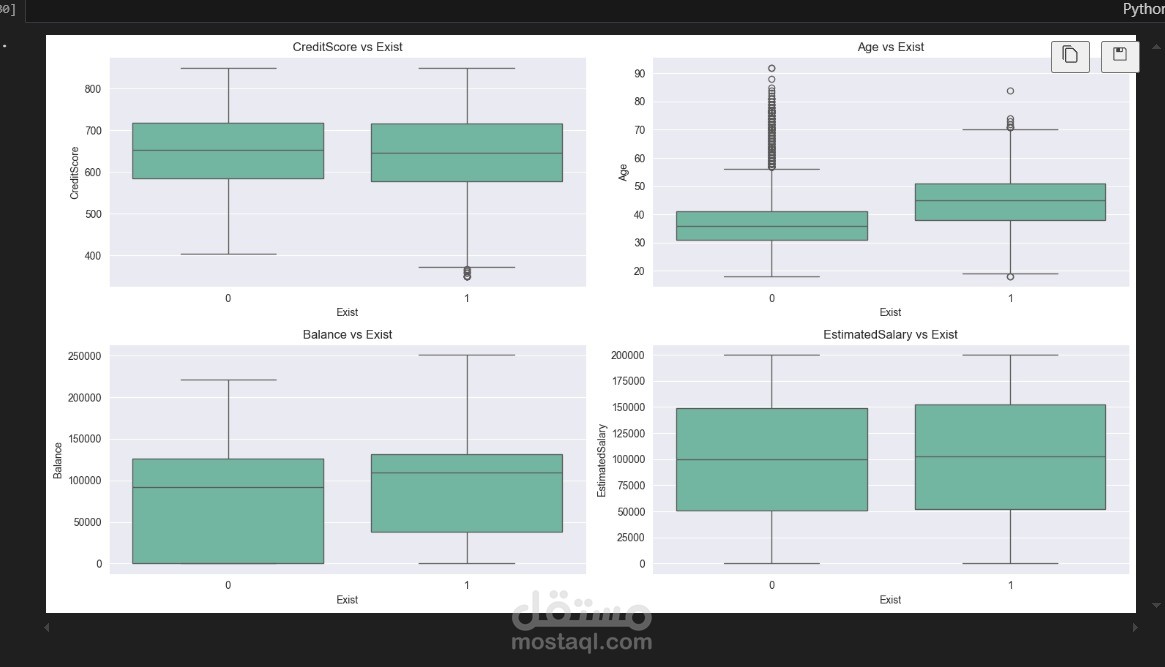
اكتشاف القيم المتطرفة باستخدام الرسوم البيانية (Boxplots).
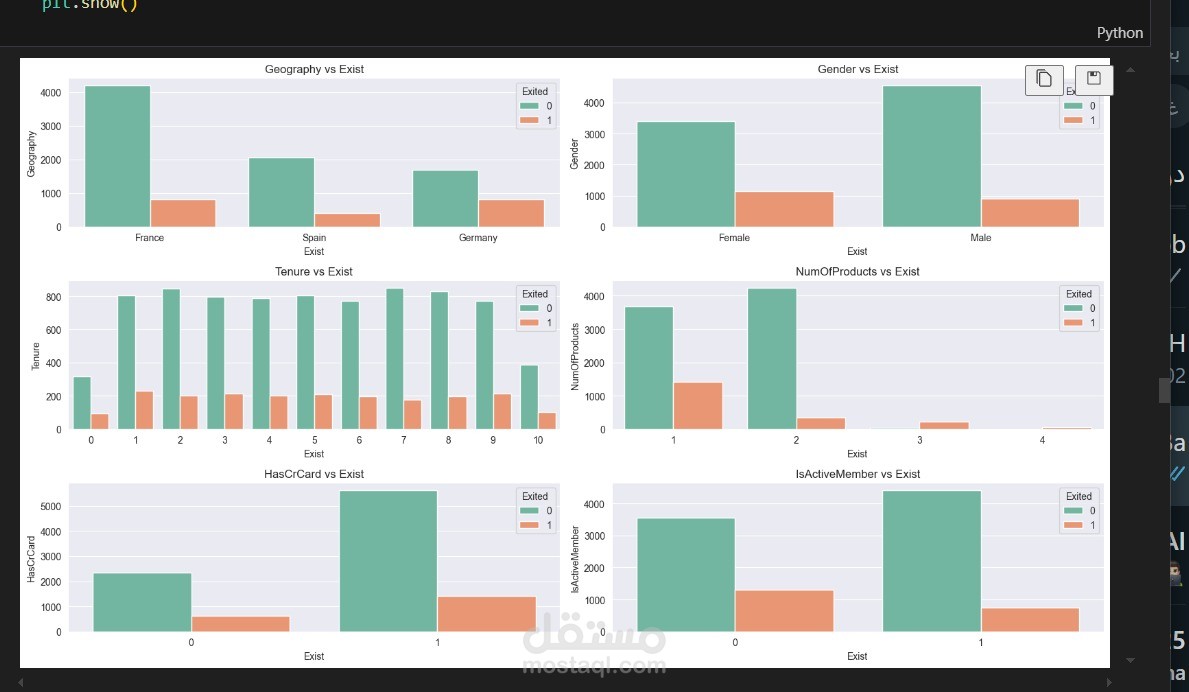
تحليل البيانات (Data Analysis):
تنفيذ التحليل الأحادي المتغير (Univariate Analysis) لدراسة خصائص كل متغير بمفرده.
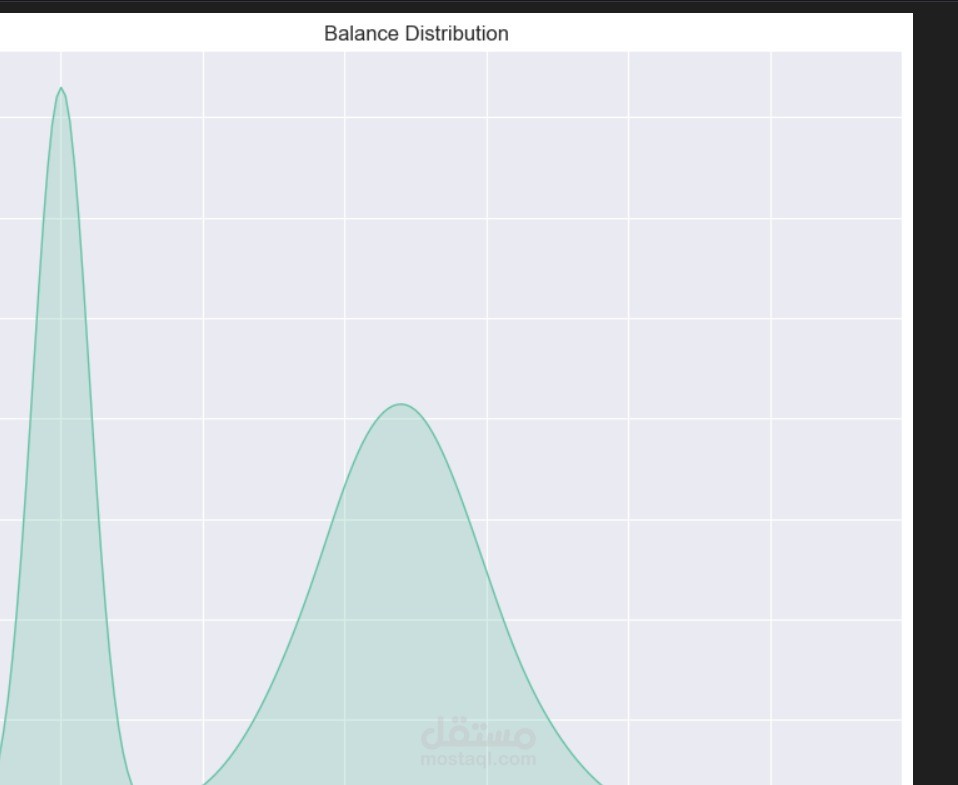
استخدام الرسوم البيانية مثل توزيعات الكثافة (KDE plots) لفهم سلوك السمات المختلفة.
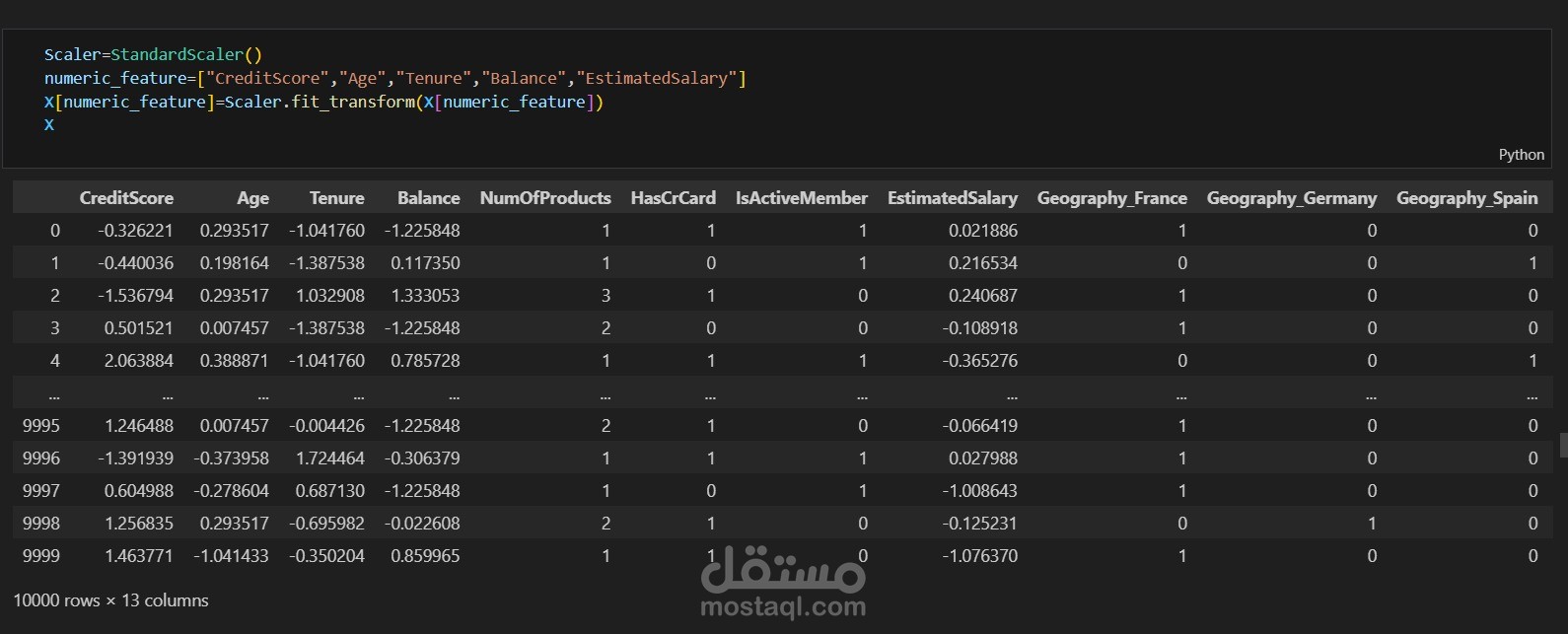
تحضير البيانات (Data Preprocessing):
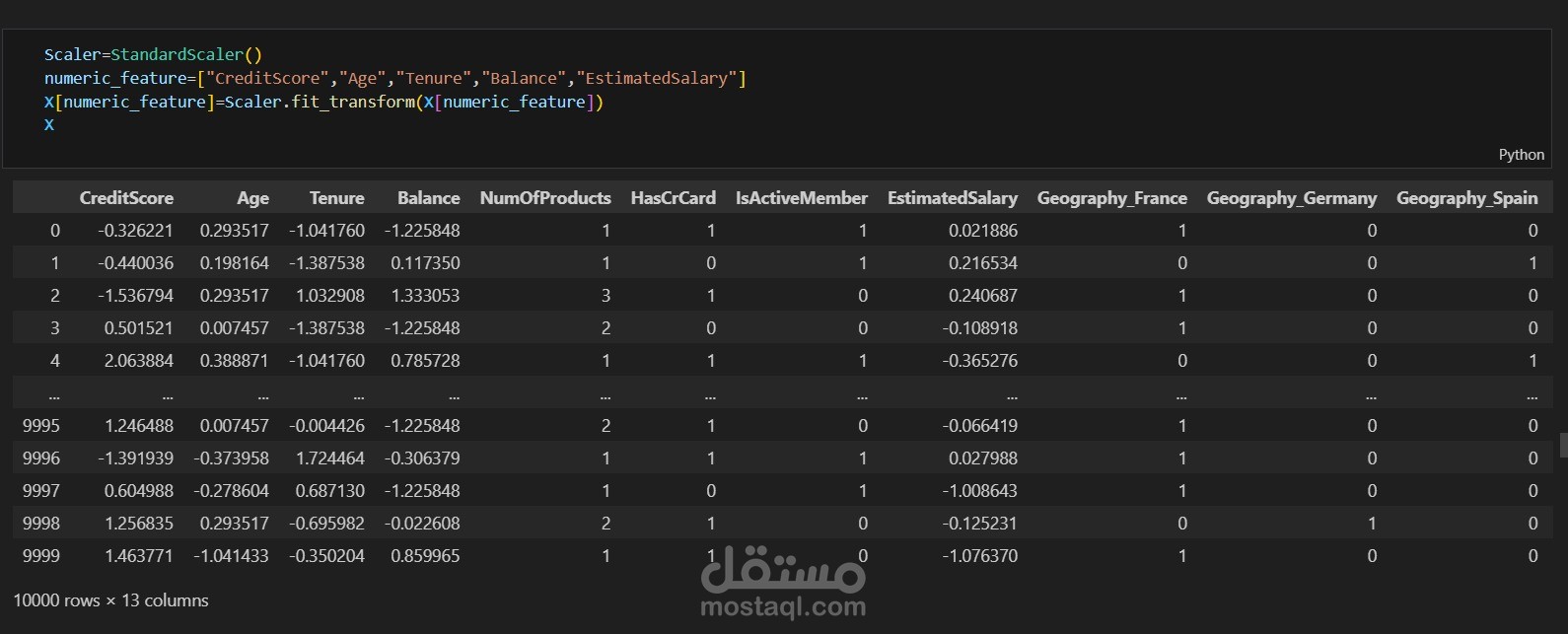
تطبيق مقياس قياسي (Standard Scaler) لتحجيم البيانات.
تقسيم البيانات إلى مجموعة تدريب واختبار باستخدام train_test_split.
بناء النماذج (Model Building):
تجربة مجموعة متنوعة من خوارزميات التصنيف منها:
الانحدار اللوجستي (Logistic Regression)
شجرة القرار (Decision Tree)
دعم النواقل (SVM)
الجيران الأقربون (KNN)
الغابات العشوائية (Random Forest)
النماذج المجمعة (Bagging, AdaBoost, Gradient Boosting, Extra Trees)
خوارزميات متقدمة مثل: XGBoost, CatBoost, LightGBM
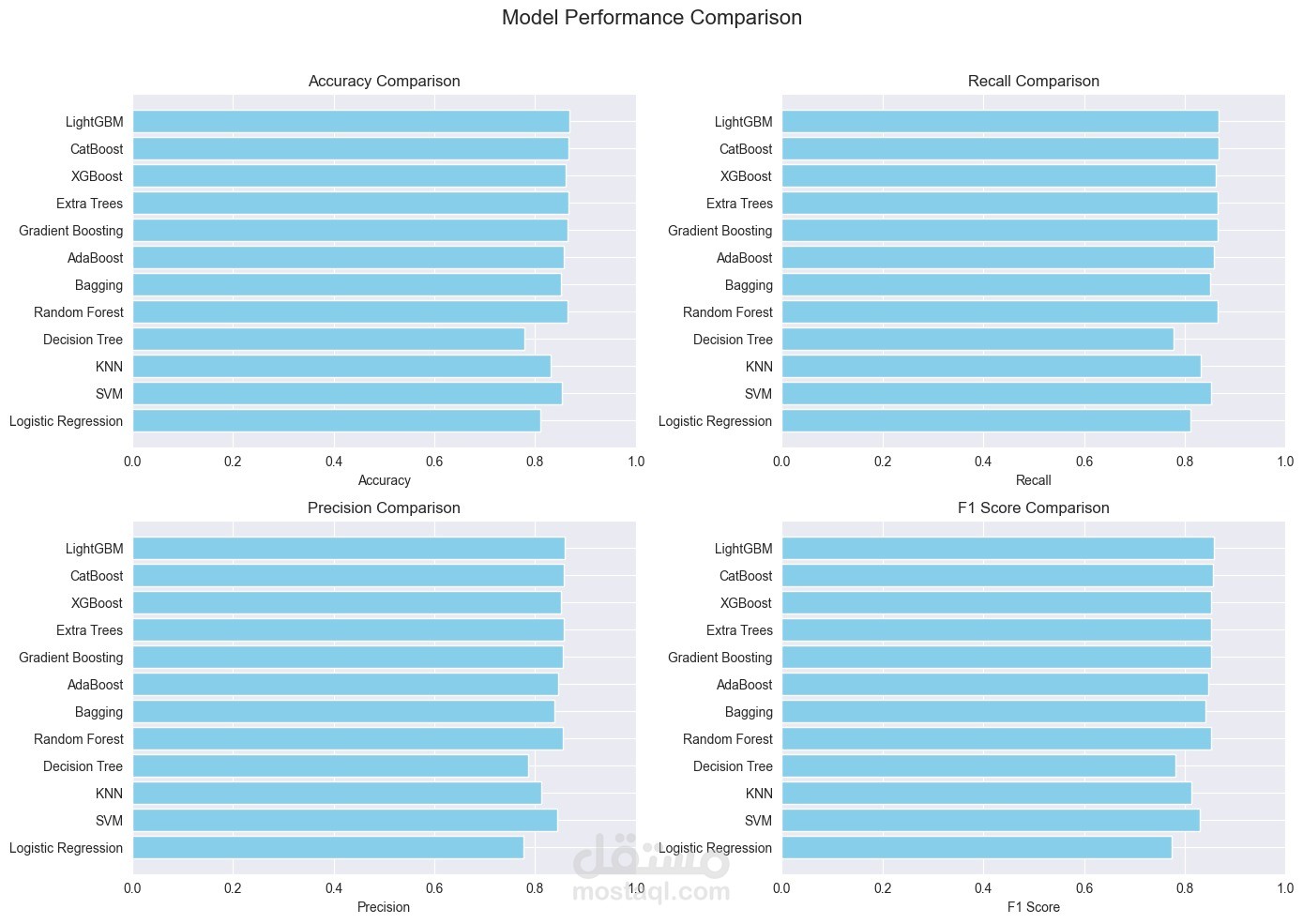
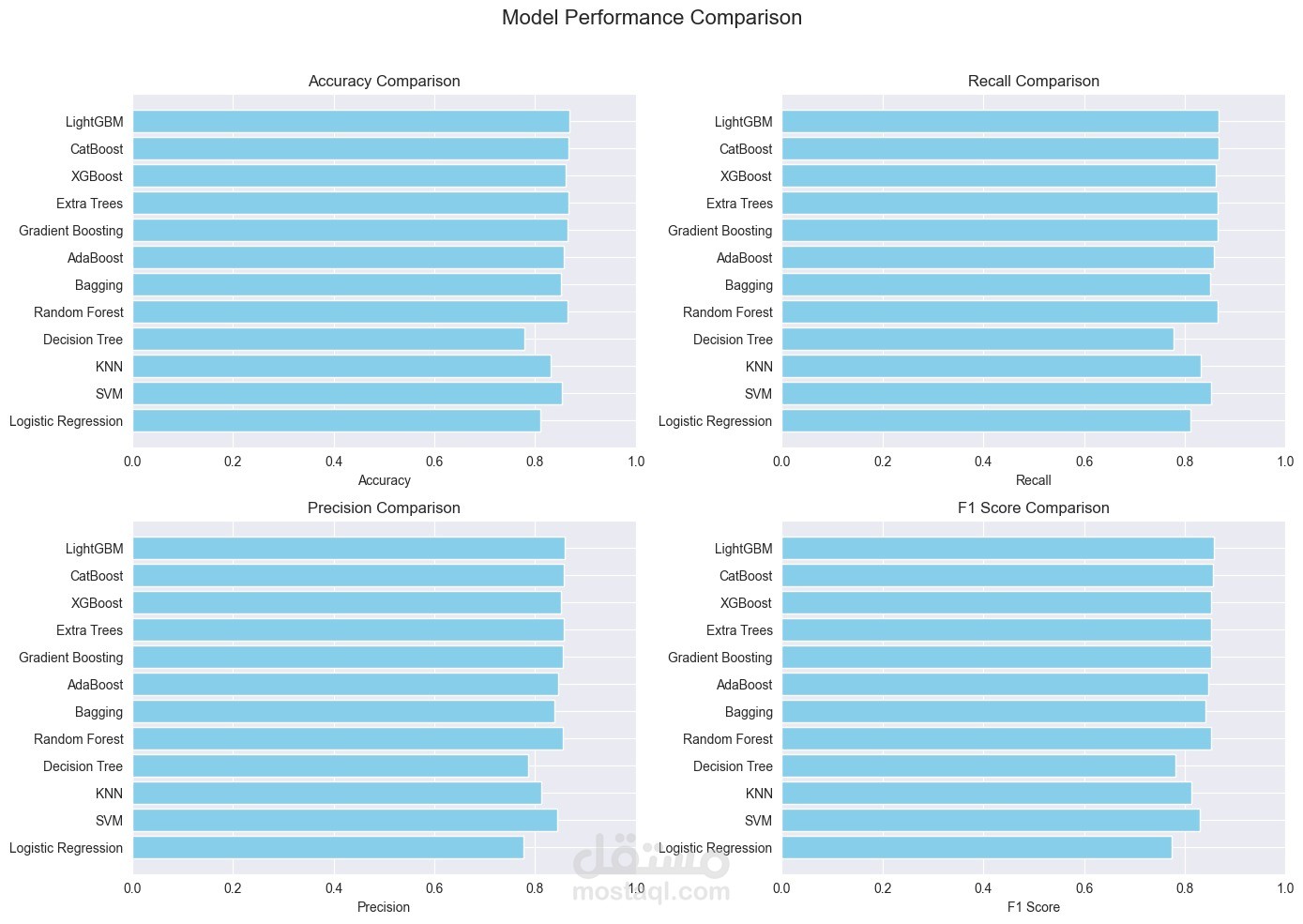
تقييم الأداء (Model Evaluation):
استخدام مقاييس التقييم المختلفة مثل:
الدقة (Accuracy)
الاستدعاء (Recall)
الدقة الإيجابية (Precision)
مقياس F1 (F1 Score)
رسم مصفوفة الالتباس (Confusion Matrix) لتقييم أداء النماذج.