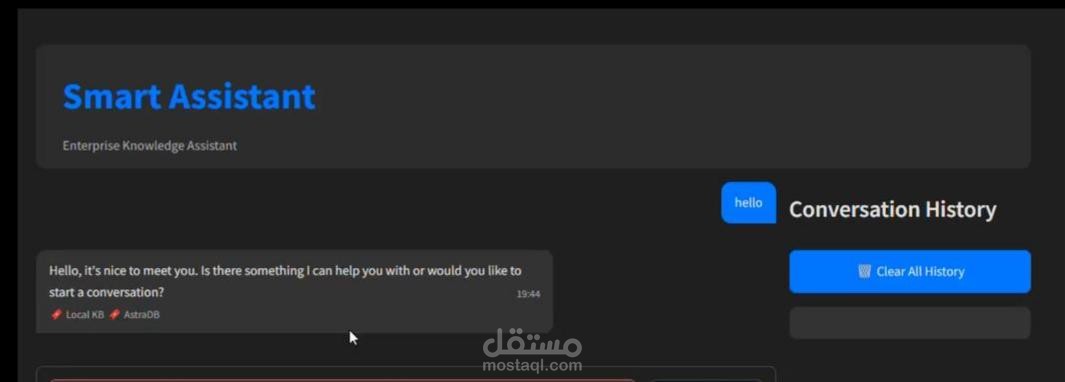
This project upgrades a previous PDF reader by integrating Retrieval-Augmented Generation (RAG) with LangGraph orchestration for smarter, faster, and context-aware responses.
Workflow:
1.Initial Synthesis – Uses local data for first-pass answers.
2.Tool & Retrieval Check – If needed, invokes external tools (Wikipedia, Arxiv) or searches vector DBs.
3.Final Synthesis – Consolidates all sources into a coherent answer.
Key Features:
•RAG:
•Local: Chroma stores embedded PDF chunks (Ollama’s mxbai-embed-large:latest).
•External: AstraDB + FAISS via a HybridRetriever (ID + semantic search).
•LLM: Powered by ChatGroq (llama-3.3-70b-versatile) for ultra-fast inference.
•Tooling: Wikipedia & Arxiv invoked only when needed.
•Orchestration: LangGraph/StateGraph enables modular, scalable pipelines.
Stack:
•LLM: ChatGroq
•Embeddings: Ollama
•Vector DB: Chroma + AstraDB + FAISS
•Tools: Wikipedia, Arxiv
•Orchestration: LangGraph
This system delivers real-time, highly relevant responses by blending local vector search, external knowledge sources, and state-driven orchestration.
| اسم المستقل | Omar S. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 3 |
| تاريخ الإضافة |