التنبؤ بالمبيعات والطلب
تفاصيل العمل
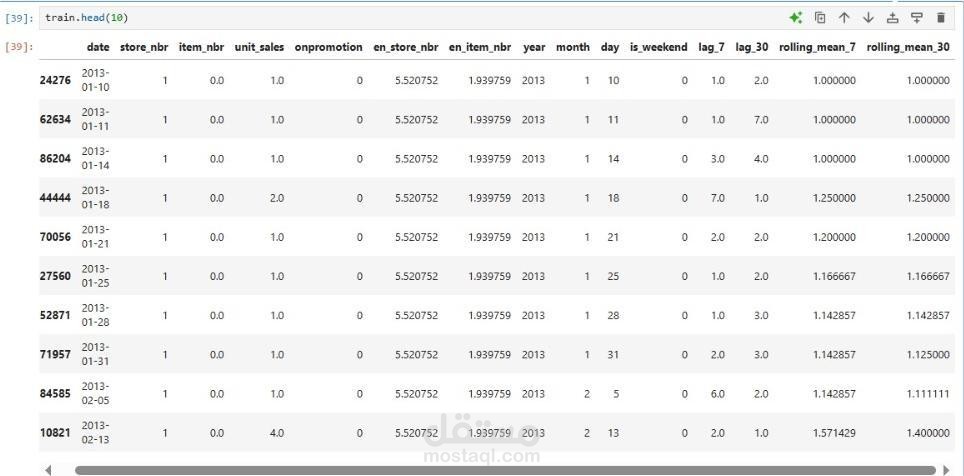
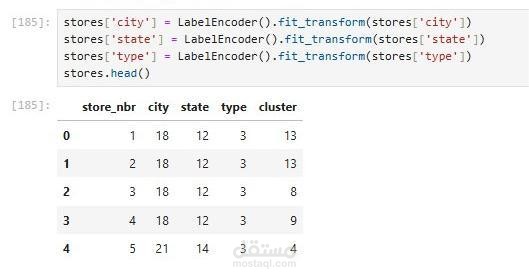
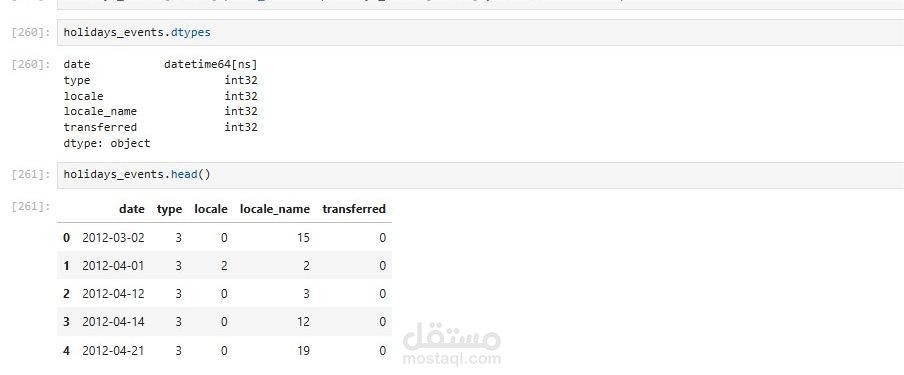
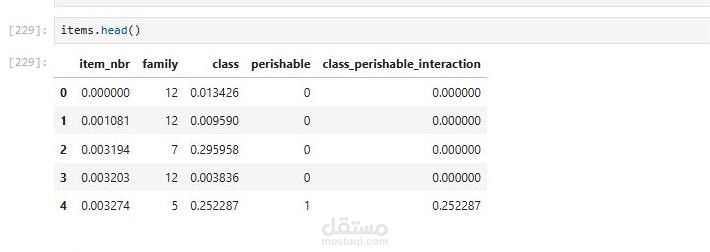
يهدف هذا المشروع إلى إعداد ومعالجة البيانات كخطوة أساسية لبناء نماذج تنبؤية دقيقة لتوقع المبيعات والطلب. يتضمن المشروع:
تنظيف البيانات (Data Cleaning): التعامل مع القيم المفقودة، إزالة التكرارات، وضمان جودة البيانات لاستخراج نتائج موثوقة.
ترميز البيانات (Label Encoding): تحويل المتغيرات النصية إلى صيغ رقمية باستخدام مكتبة sklearn، مما يسهل على النماذج التنبؤية فهم الأنماط.
استيراد البيانات: تحميل ومعالجة مجموعتي بيانات — train.csv و test.csv، مما يمهد لبناء نموذج قوي لتوقع المبيعات.
الأدوات والتقنيات المستخدمة:
تحليل البيانات: Pandas، NumPy
معالجة البيانات: Scikit-learn (LabelEncoder)
البرمجة: Python
هذا المشروع يعكس مهاراتي في تحليل البيانات ومعالجتها، وهي خطوة حاسمة لضمان دقة النماذج التنبؤية، مما يدعم اتخاذ القرارات الذكية في مجال الأعمال