Emotion Classifier
تفاصيل العمل
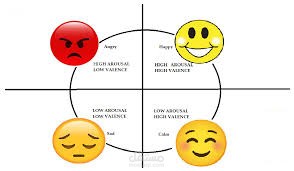
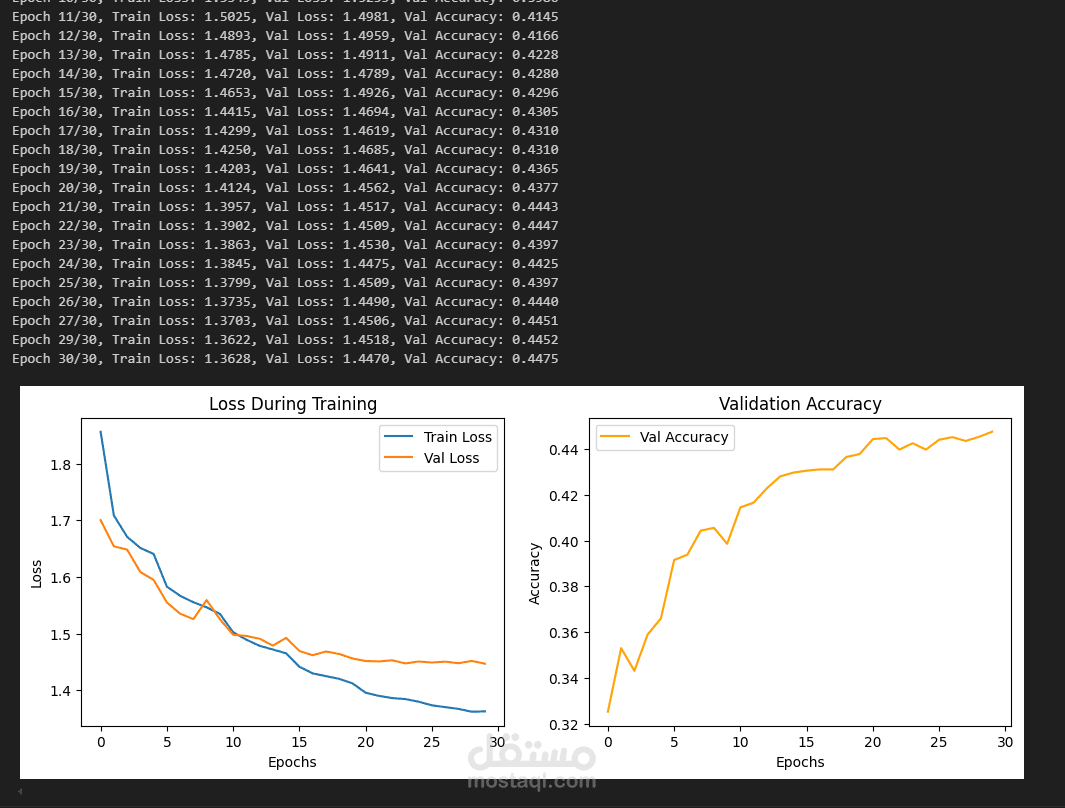
نموذج تصنيف المشاعر يعتمد على تقنيات التعلم العميق (Deep Learning) ومعالجة اللغة الطبيعية (NLP) لتحليل النصوص وتصنيف المشاعر المرتبطة بها، مثل السعادة، الحزن، الغضب، الخوف، الدهشة، الحياد، وغيرها. يمكن استخدامه في تطبيقات مثل تحليل المشاعر في وسائل التواصل الاجتماعي، تحسين تجربة العملاء، وأنظمة الدردشة الذكية.
استخدام تحليل المشاعر (Sentiment Analysis) والتصنيف بناءً على المشاعر المختلفة
بناء نموذج ML أو DL باستخدام LSTMs، Transformers (مثل BERT)، أو CNNs
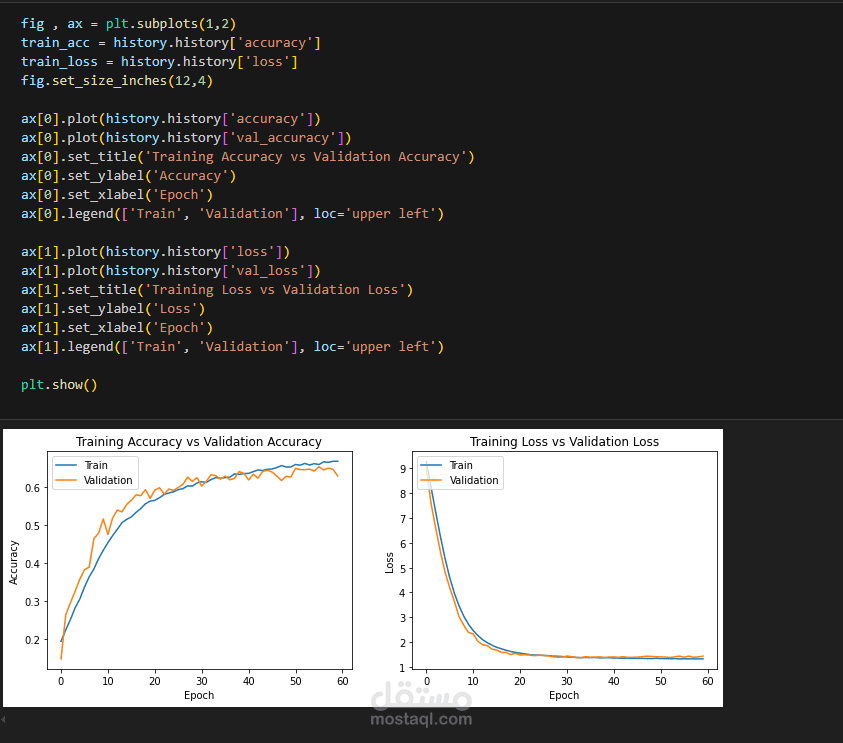
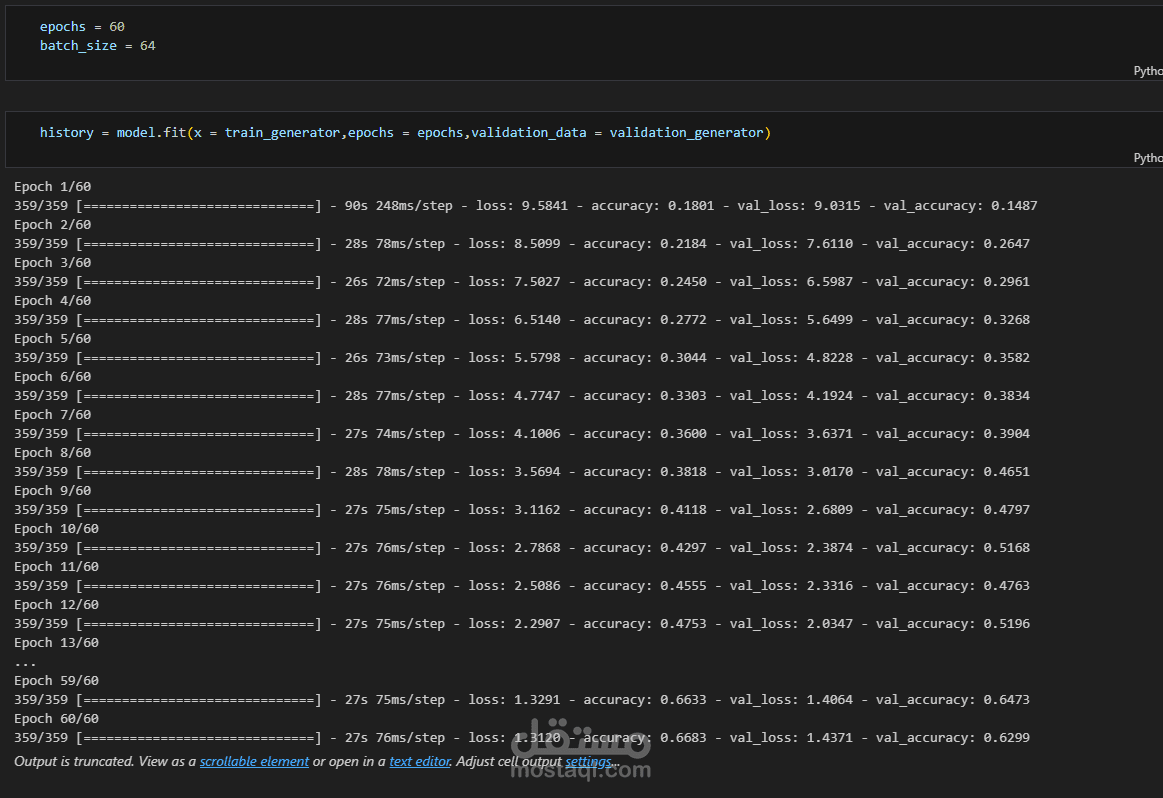
تدريب النموذج وتحسينه باستخدام التعلم العميق والتوليف الفائق (Hyperparameter Tuning)
تقييم أداء النموذج باستخدام مصفوفة الالتباس (Confusion Matrix) والمقاييس مثل الدقة (Accuracy) والاستدعاء (Recall)
نشر النموذج كـ واجهة API لاستخدامه في التطبيقات المختلفة
التقنيات والأدوات المستخدمة:
لغات البرمجة: Python
مكتبات التعلم العميق: TensorFlow، PyTorch
معالجة البيانات: Pandas، NumPy، NLTK، SpaCy
نماذج جاهزة: BERT، RoBERTa، GPT
تقييم الأداء: Scikit-learn، Matplotlib، Seaborn
النشر: Flask، FastAPI، أو Streamlit لتطوير واجهة المستخدم
الأهداف:
تحسين دقة التصنيف وتقليل الأخطاء في فهم المشاعر
تطوير نموذج قادر على التعرف على السياق وفهم اللغة العامية واللهجات المختلفة
نشره للاستخدام في تطبيقات تحليل البيانات ومراقبة التفاعل في الوقت الفعلي