تطوير نموذج تعلم لللآلة للكشف اذا كان الخبر صادق او كاذب
تفاصيل العمل
نظرة عامة على المشروع:
يركز هذا المشروع على اكتشاف الأخبار الزائفة باستخدام تقنيات معالجة اللغة الطبيعية (NLP). الهدف هو بناء مُصنّف للأخبار الزائفة بدقة عالية من خلال استغلال النماذج المختلفة للتعلم الآلي وتقييم أدائها باستخدام مقاييس مختلفة. سيتم نشر النموذج النهائي من خلال تطبيق ويب بواجهة مستخدم سهلة الاستخدام ليكون الوصول إليه سهلاً للمستخدمين.
مجموعة البيانات:
تم استخدام مجموعة بيانات WELFake من Kaggle لهذا المشروع. وهي مجموعة بيانات نصية تحتوي على ما يقرب من 70,000 صف من المقالات الإخبارية الحقيقية والزائفة، مما يجعلها مناسبة لتدريب وتقييم نماذج التصنيف.
تقنيات NLP المستخدمة:
لتجهيز البيانات واستخلاص معاني مفيدة من النص، تم تطبيق العديد من تقنيات معالجة اللغة الطبيعية:
تقسيم النص (Tokenization): تقسيم النص إلى كلمات أو أجزاء فرعية.
التجذير والتصريف (Lemmatization & Stemming): تقليص الكلمات إلى شكلها الأساسي أو جذرها.
النغمات (N-grams): التقاط تسلسلات الكلمات لفهم السياق.
TF-IDF (تكرار الكلمة معكوس التردد): تحويل النص إلى ميزات رقمية لتدريب النموذج.
تقييم النموذج:
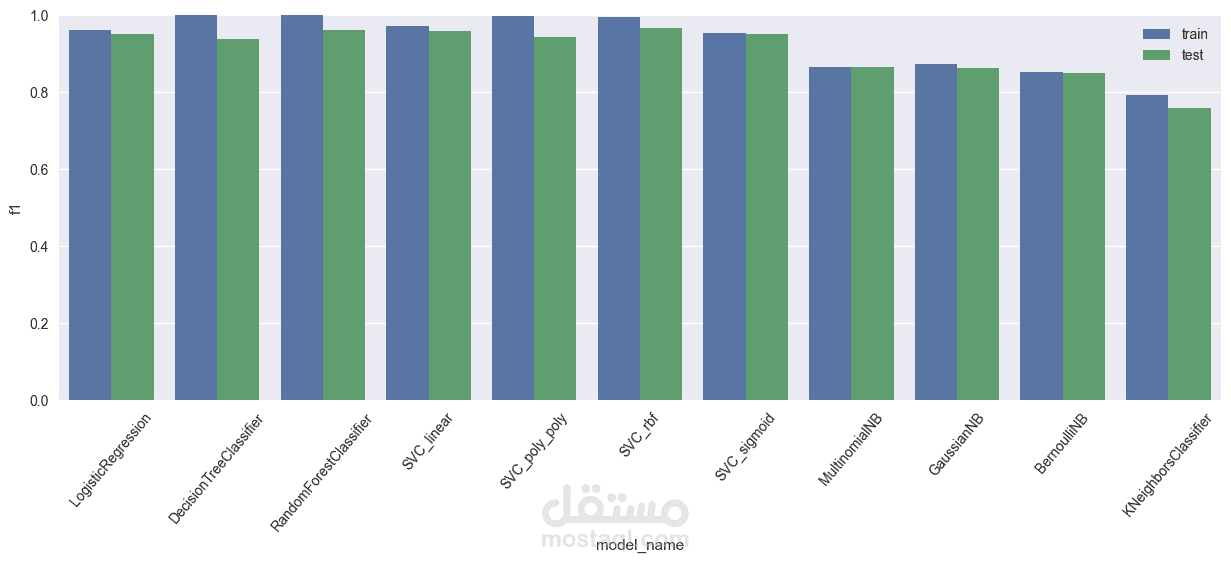
تم اختبار العديد من نماذج التعلم الآلي لتحديد أفضل مُصنّف. فيما يلي ملخص أدائهم بناءً على الدقة والاستدعاء والدقة وF1-score:
نموذج SVC مع نواة RBF قد أظهر أداءً ممتازًا، حيث حقق دقة بلغت 96.58%، مما يجعله النموذج المختار للنشر.
تطبيق الويب:
لتحسين سهولة الاستخدام، سيتم نشر النموذج الأفضل أداءً كتطبيق ويب مع الميزات التالية:
واجهة مستخدم سهلة الاستخدام للسماح للمستخدمين بإدخال المقالات الإخبارية والحصول على نتائج التصنيف.
التنبؤ في الوقت الحقيقي للحصول على تغذية راجعة فورية.
تصميم متجاوب ليتناسب مع أجهزة الكمبيوتر المكتبية والهواتف المحمولة.
هذا المشروع يجمع بين تقنيات معالجة اللغة الطبيعية ونماذج التعلم الآلي وتطوير الويب لإنشاء حل فعال وسهل الوصول لاكتشاف الأخبار الزائفة.