Twitter Sentiment Analysis
تفاصيل العمل
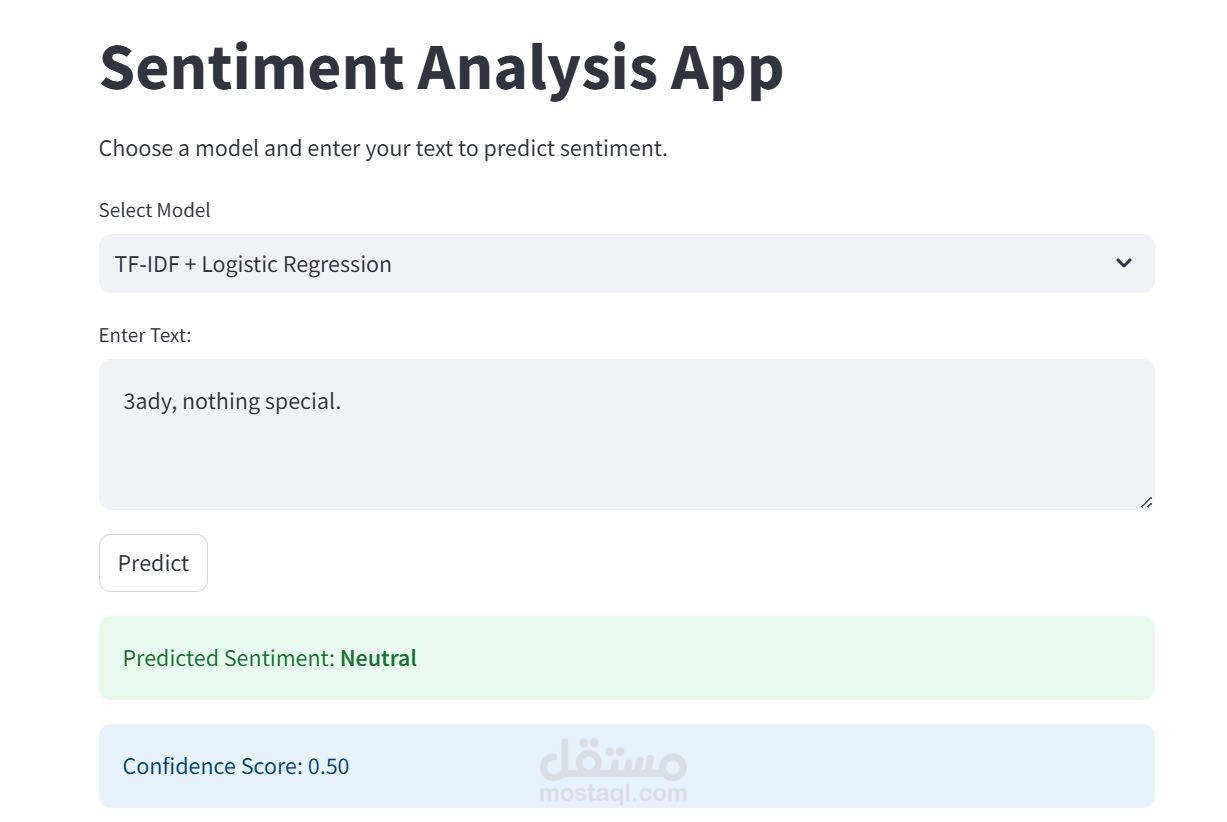
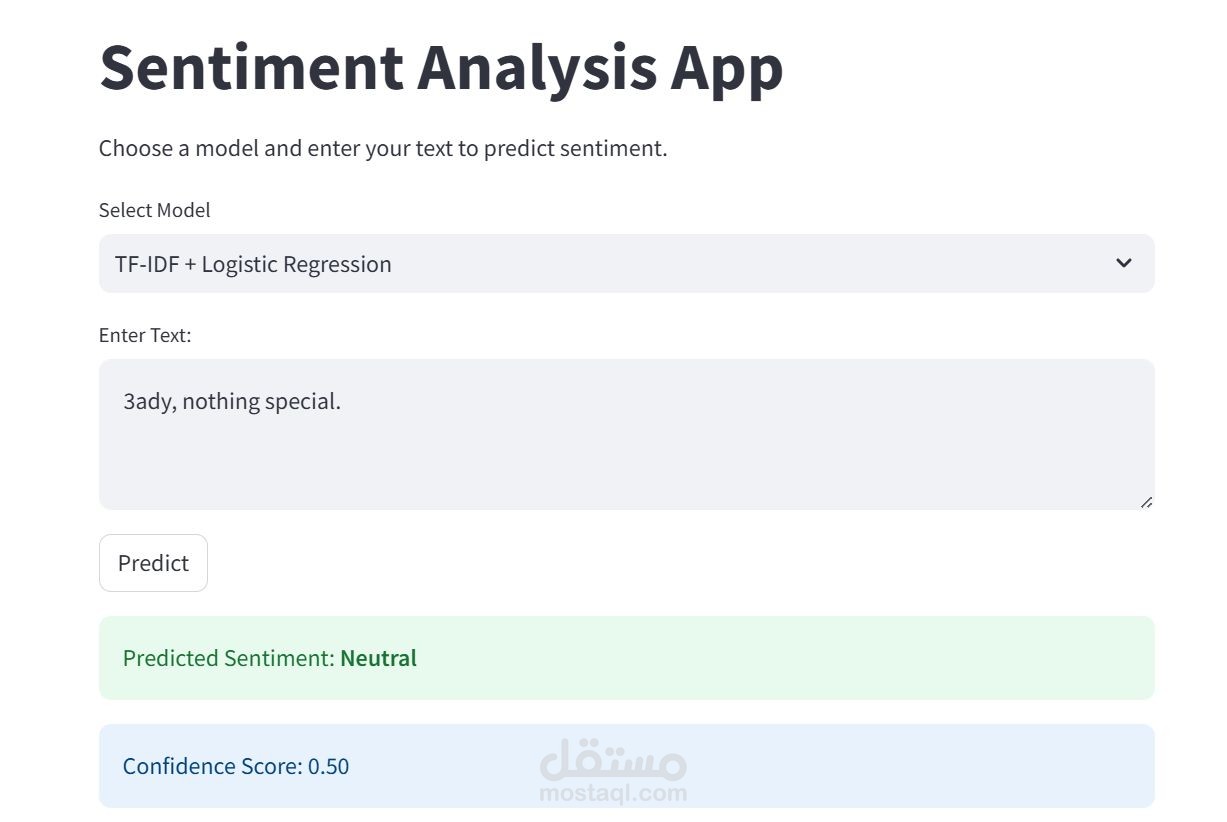
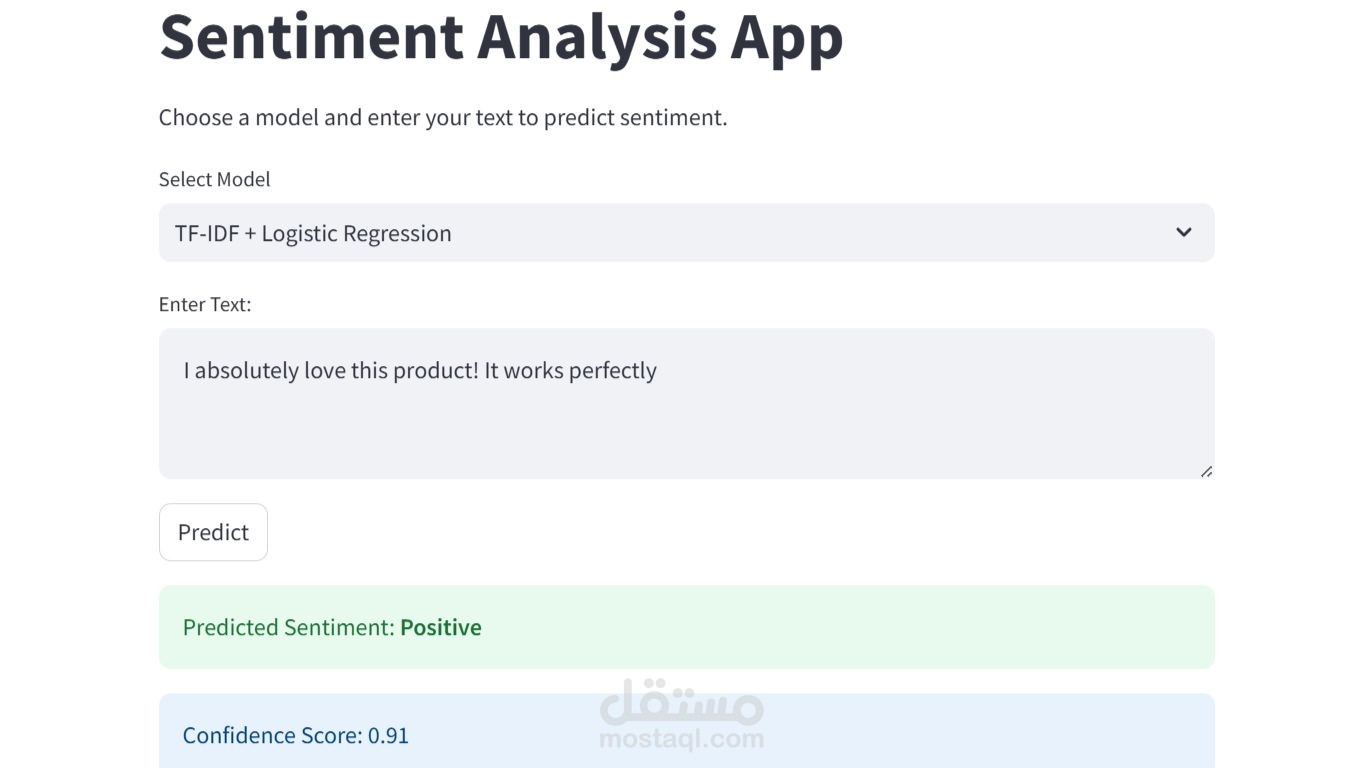
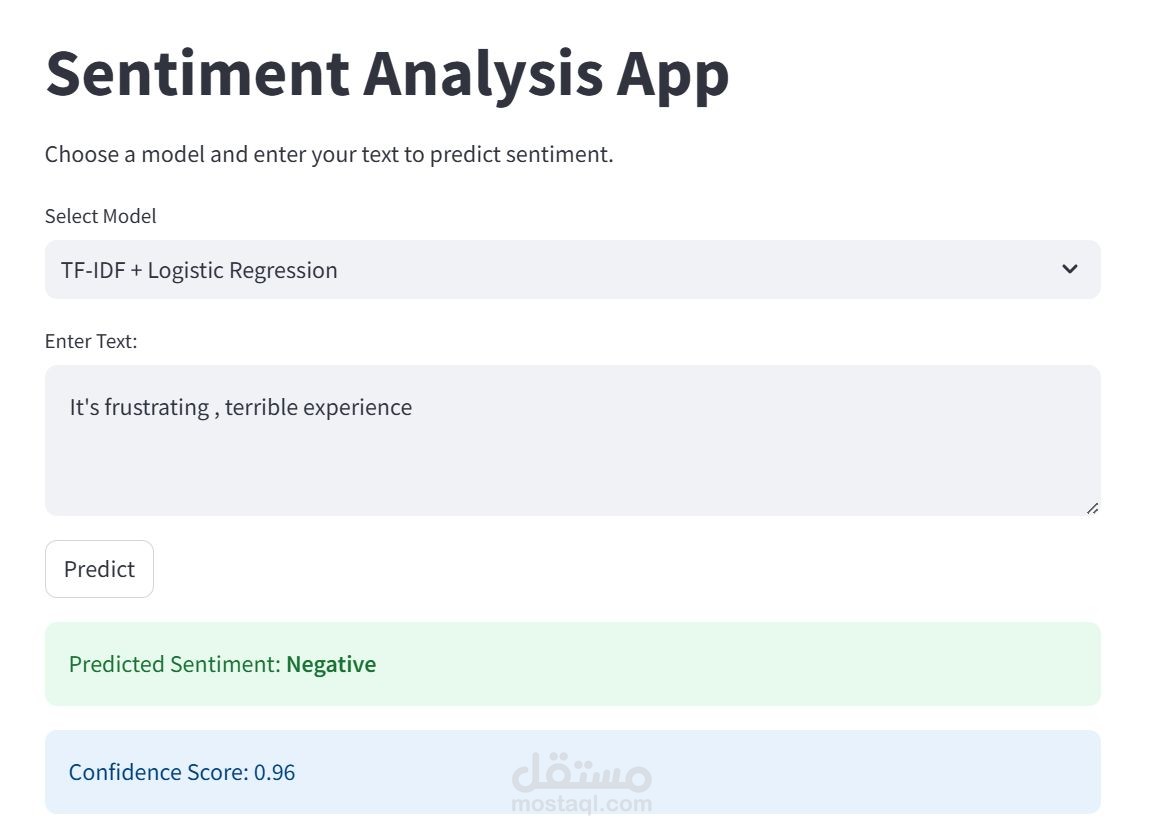

الهدف (Objective):
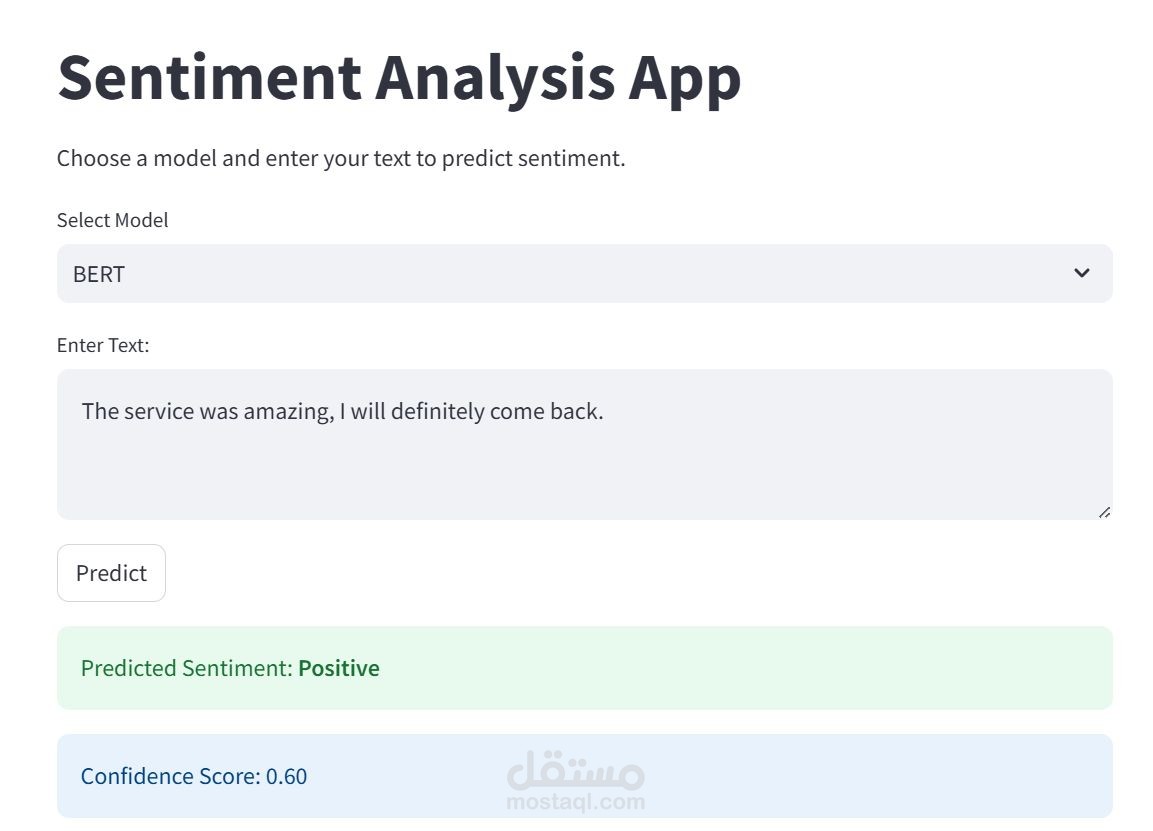
بناء نظام لتصنيف التغريدات إلى مشاعر إيجابية أو سلبية أو محايدة، وذلك باستخدام نهجين: الأول يعتمد على خوارزميات تعلم الآلة التقليدية، والثاني يعتمد على نماذج التعلم العميق القائمة على المحولات (Transformers).
التقنيات المستخدمة (Tech Stack):
لغة البرمجة: Python
معالجة البيانات: Pandas، NumPy
مكتبات تعلم الآلة والتعلم العميق: Scikit-learn، TensorFlow، Transformers (BERT)
الخوارزميات والتقنيات: TF-IDF، الانحدار اللوجستي (Logistic Regression)، ضبط نموذج BERT (Fine-tuning)
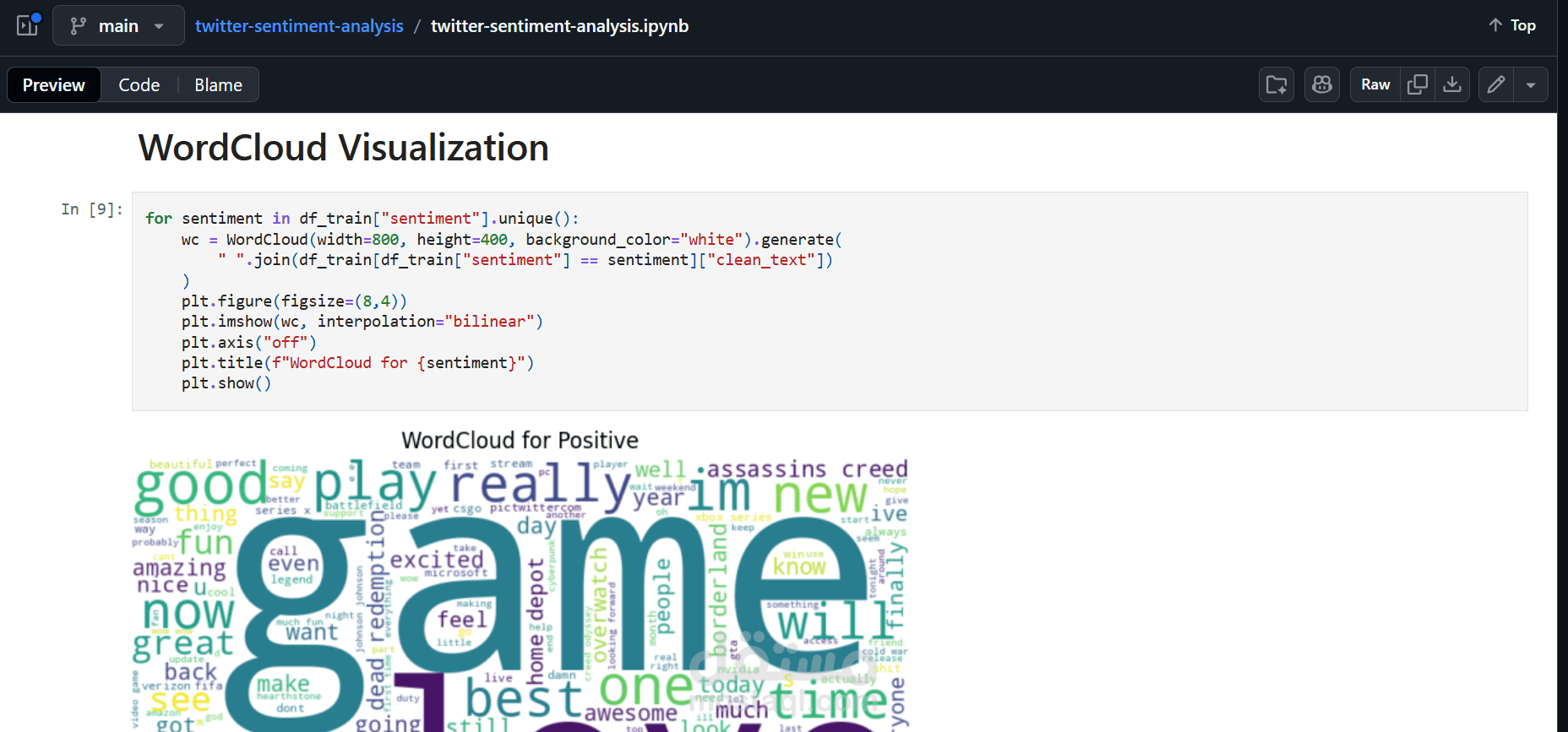
تصور البيانات: Matplotlib، Seaborn، WordCloud
مراحل العمل (Process Overview):
تنظيف البيانات ومعالجتها (Data Cleaning & Preprocessing): إزالة الضوضاء وتوحيد النصوص
التحليل الاستكشافي للبيانات (EDA): دراسة توزيع المشاعر وإنشاء سحب كلمات (Word Clouds)
النموذج الأول: استخدام TF-IDF مع الانحدار اللوجستي كنموذج أساسي (Baseline)
النموذج الثاني: ضبط نموذج BERT لتصنيف النصوص (Sequence Classification)
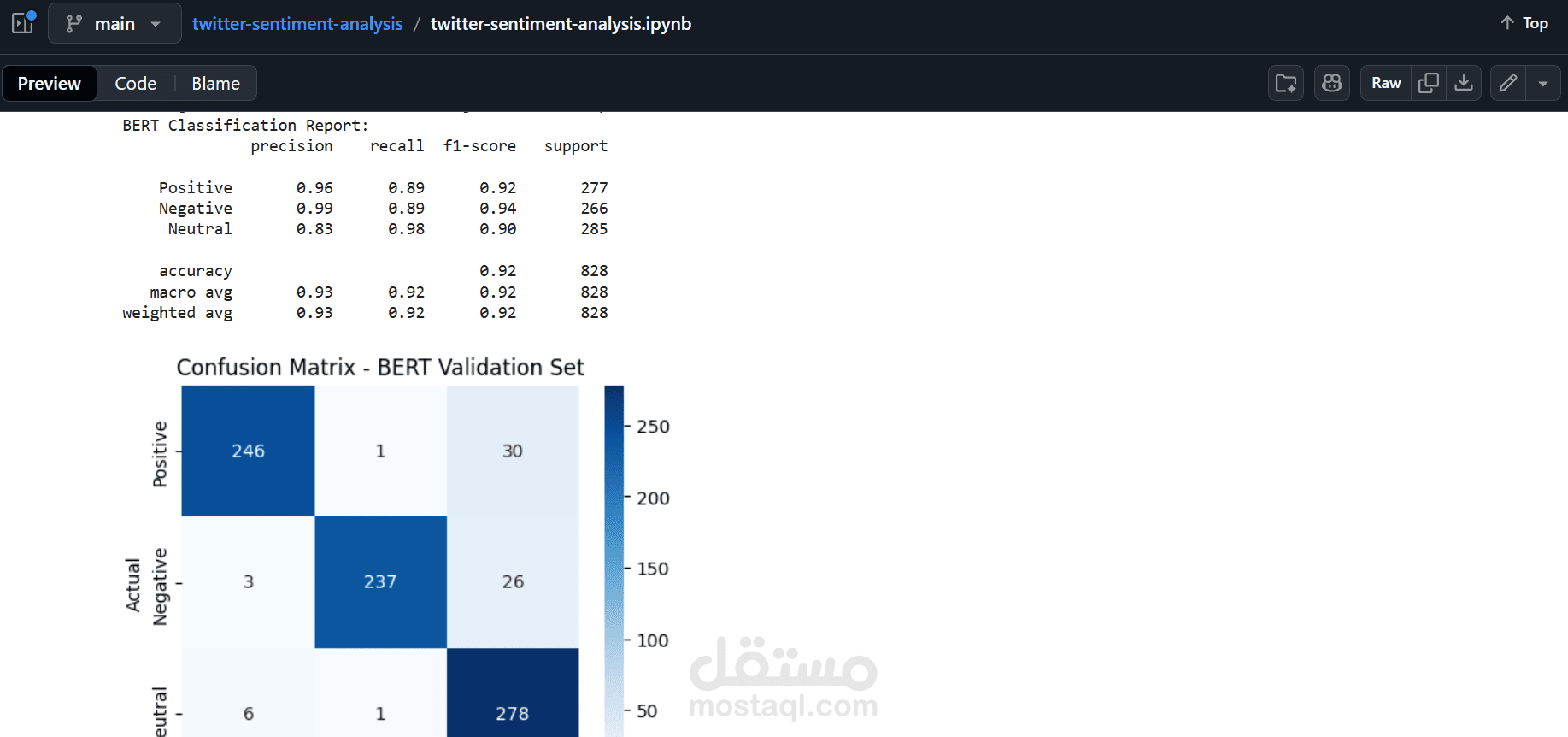
التقييم: باستخدام مقاييس مثل الدقة (Accuracy)، تقارير التصنيف (Classification Reports)، ومصفوفة الالتباس (Confusion Matrix)
حفظ النماذج: تجهيز وتخزين كلا النموذجين لاستخدامهما لاحقًا في النشر (Deployment)