استخراج بيانات من الويب Amazon Web Scraping
تفاصيل العمل
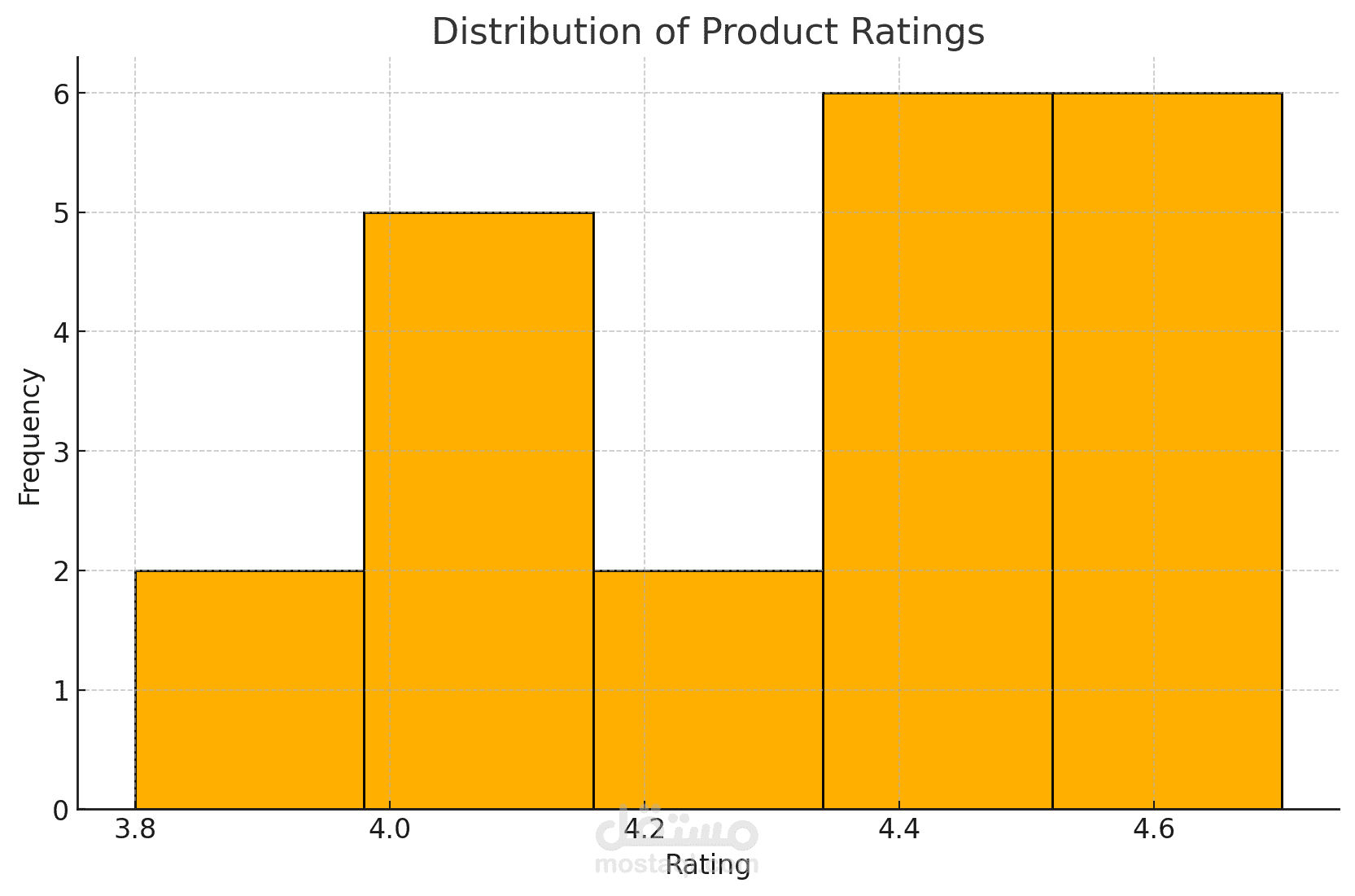
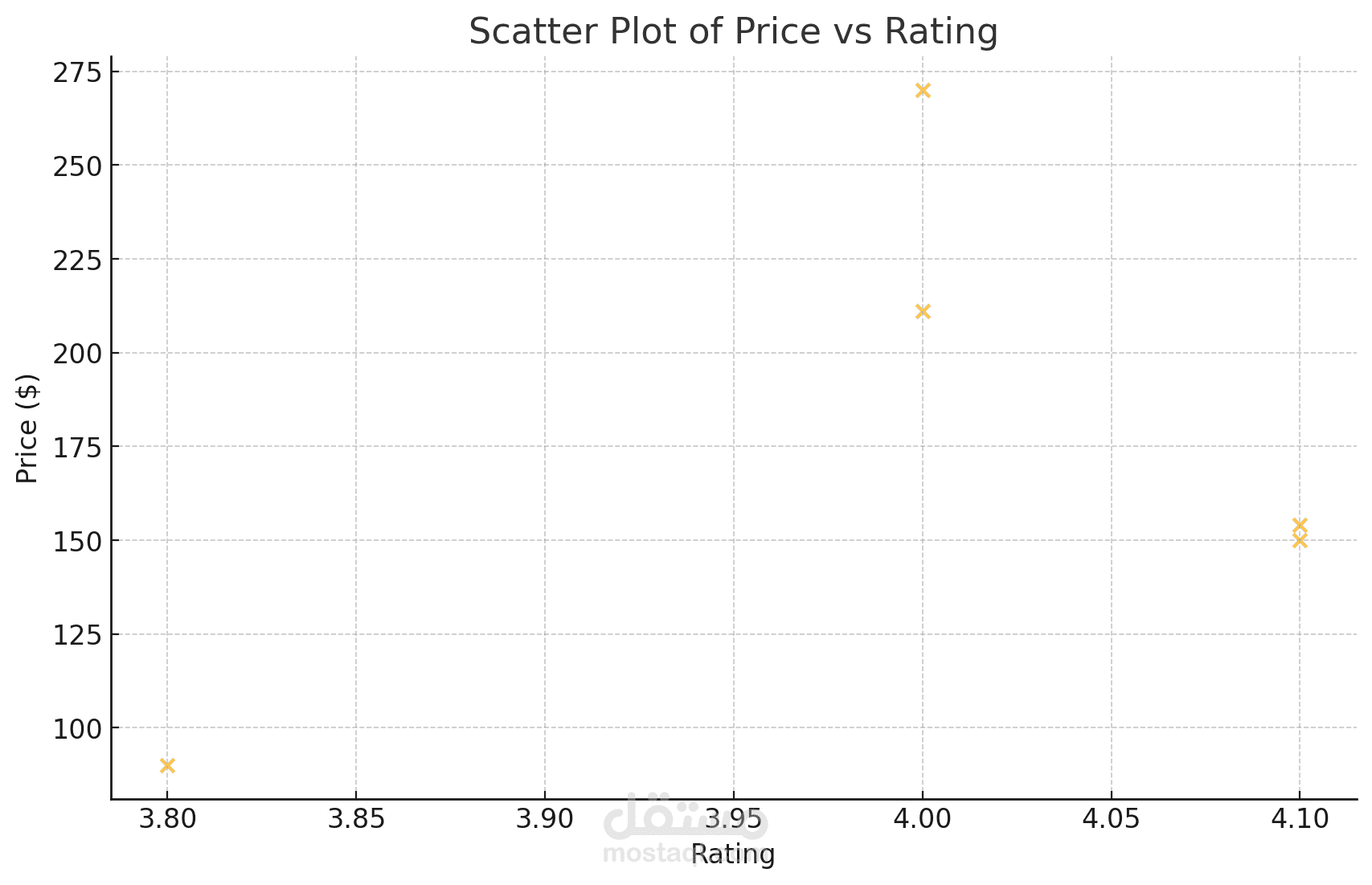
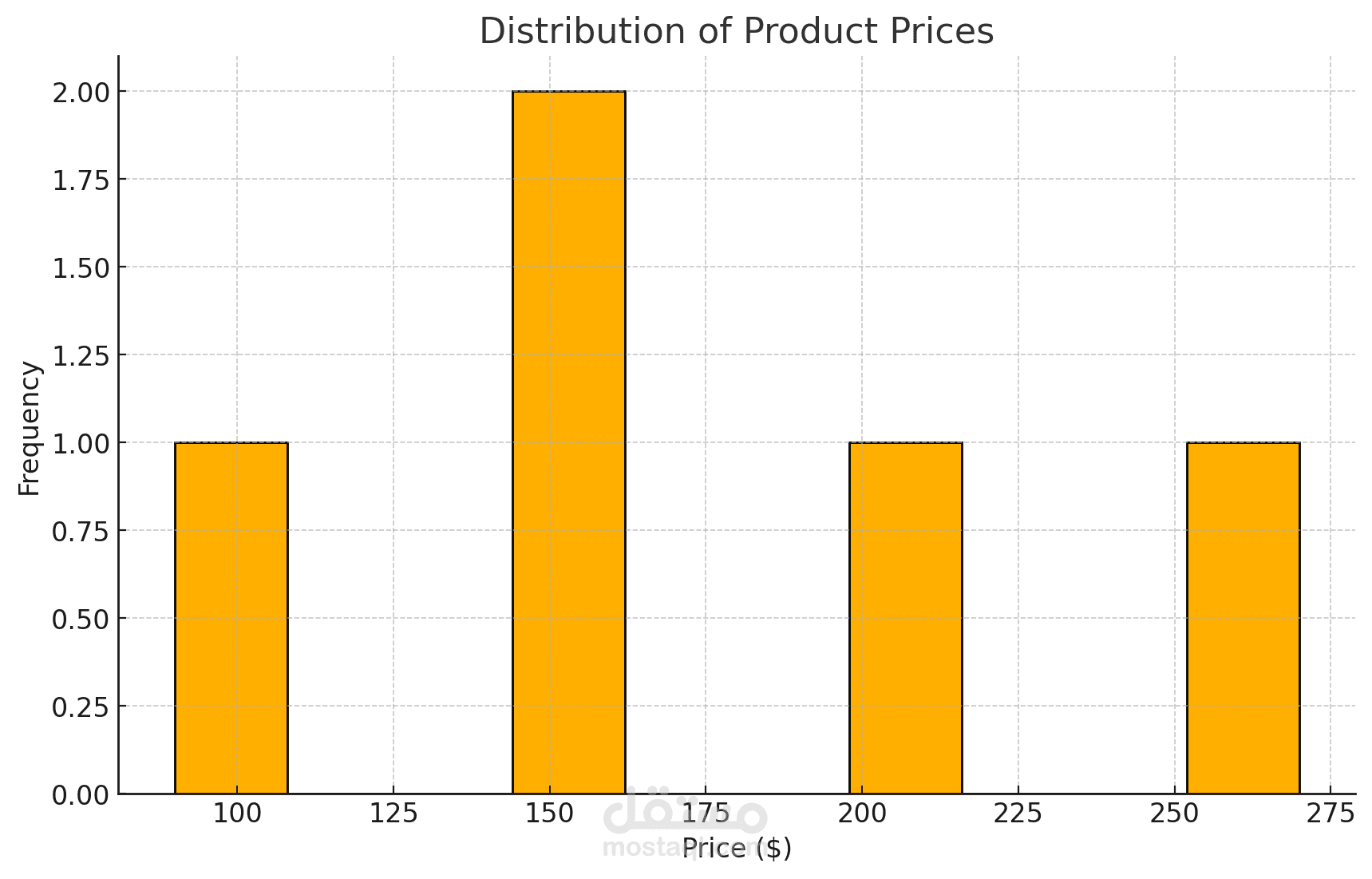
هذا المشروع يعتمد على Python ويهدف إلى استخراج بيانات المنتجات من موقع Amazon، مع التركيز على قوائم PlayStation 4. يقوم المشروع بأتمتة عملية جمع المعلومات مثل أسماء المنتجات، الأسعار، التقييمات، وتوافر المنتجات، مما يسهل عملية جمع البيانات لتحليلها واستخلاص الأفكار.
المكونات الرئيسية:
- Web Scraping: استخدام مكتبة requests لإرسال طلبات HTTP ومكتبة BeautifulSoup لتحليل محتوى HTML، لضمان استخراج دقيق للبيانات من صفحات المنتجات في Amazon.
- تخزين البيانات: يتم حفظ المعلومات المستخرجة في ملف CSV (`amazon_data.csv`)، مما يسهل الوصول إليها وتحليلها لاحقًا.
- تصوير البيانات (Data Visualization): يشمل المشروع أدوات لتصور البيانات المستخرجة، مما يساعد في فهم اتجاهات السوق وتفاصيل المنتجات بشكل أفضل.
التقنيات المستخدمة:
- Python 3.7+
- مكتبات: `requests`, `BeautifulSoup`, `pandas`
- Jupyter Notebook لتشغيل الأكواد وعرض البيانات
طريقة الاستخدام:
1. قم بنسخ (Clone) المستودع وتثبيت المكتبات المطلوبة.
2. افتح Jupyter Notebook (`Amazon Web Scraping.ipynb`) ونفذ الأوامر لاستخراج البيانات.
3. سيتم حفظ البيانات الناتجة في ملف `amazon_data.csv` للرجوع إليها وتحليلها بسهولة.
يعرض هذا المشروع مهارات أساسية في Web Scraping ويمكن تكييفه للعمل مع منصات التجارة الإلكترونية المختلفة وفئات المنتجات، مما يوفر رؤى قيمة حول الأسعار وتوافر المنتجات.
ملفات مرفقة
بطاقة العمل
| اسم المستقل | Kirolos D. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 9 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |