Medical-chatbot
تفاصيل العمل



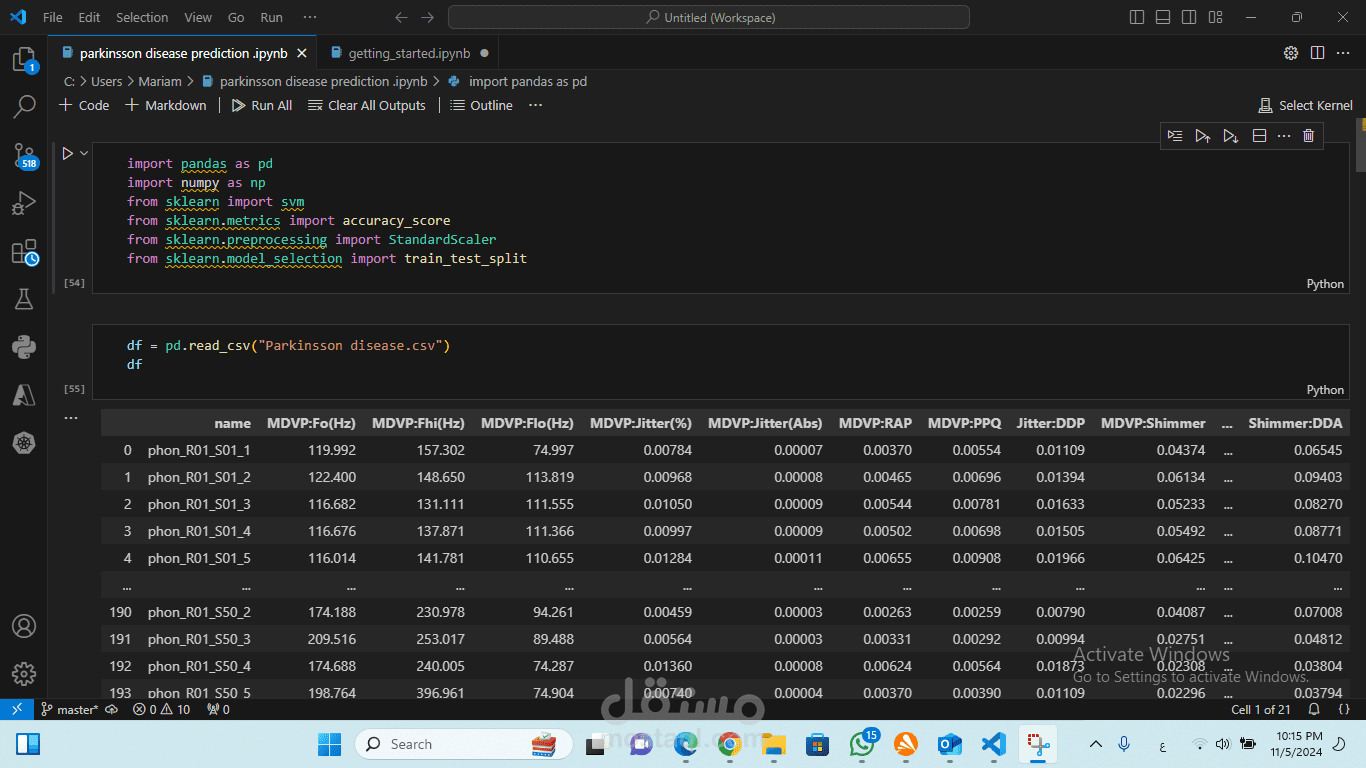
تجميع البيانات:
جمع بيانات الأسئلة والأجوبة الطبية من مصادر موثوقة مثل المواقع الطبية أو قواعد بيانات المعرفة العامة.
جمع البيانات قد يشمل أيضًا بيانات من سجلات المحادثات الطبية لتدريب النموذج على فهم الأسئلة الشائعة.
معالجة البيانات:
تنظيف النصوص للتخلص من الضوضاء مثل الرموز أو البيانات غير المرغوبة.
استخدام تقنيات مثل تحويل الكلمات إلى جذورها (Stemming) أو تصحيح الأخطاء الإملائية لتحسين جودة البيانات.
تحويل النصوص:
تحويل النصوص إلى تمثيلات عددية باستخدام تقنيات مثل TF-IDF أو Word Embeddings (مثل Word2Vec أو GloVe).
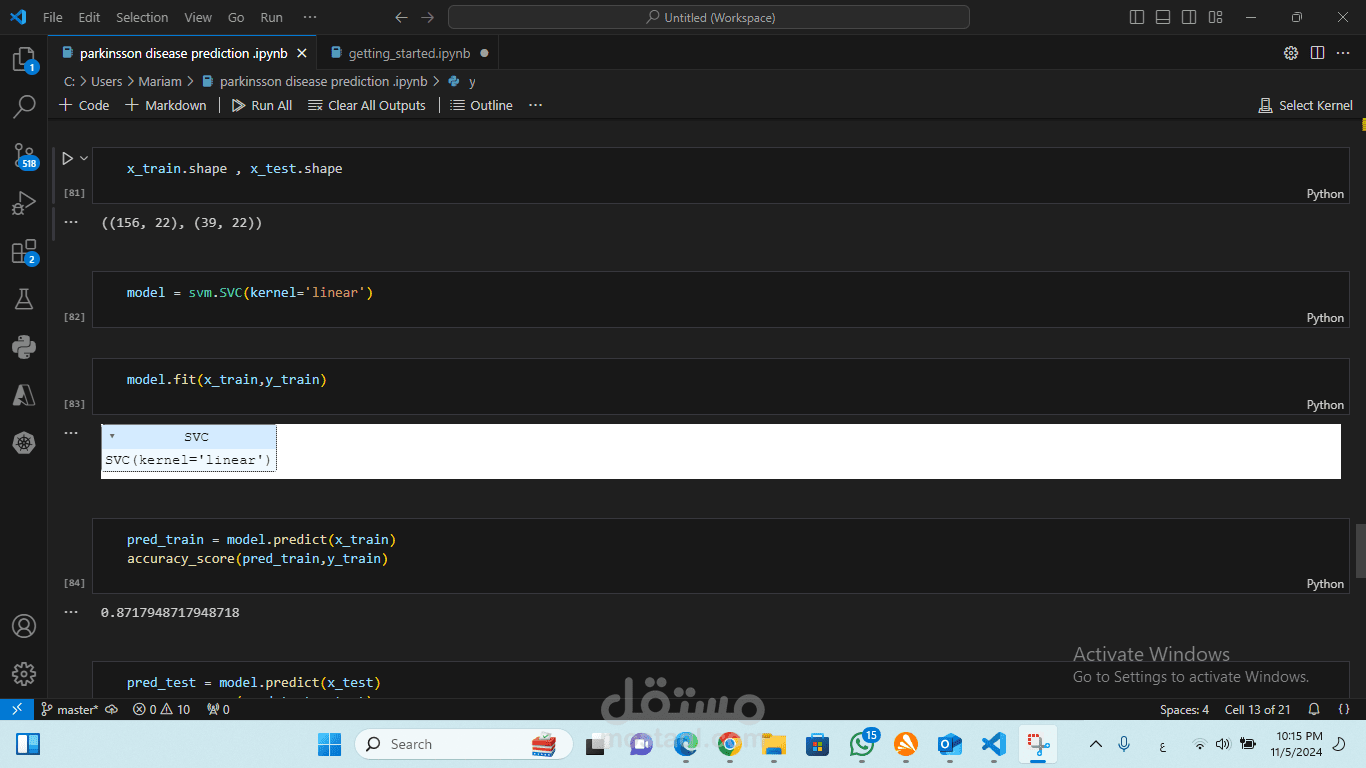
بناء النموذج:
اختيار خوارزميات مناسبة مثل نماذج الشبكات العصبية (RNN، LSTM) أو استخدام نماذج جاهزة مثل BERT.
تدريب النموذج باستخدام مكتبات مثل TensorFlow أو PyTorch.
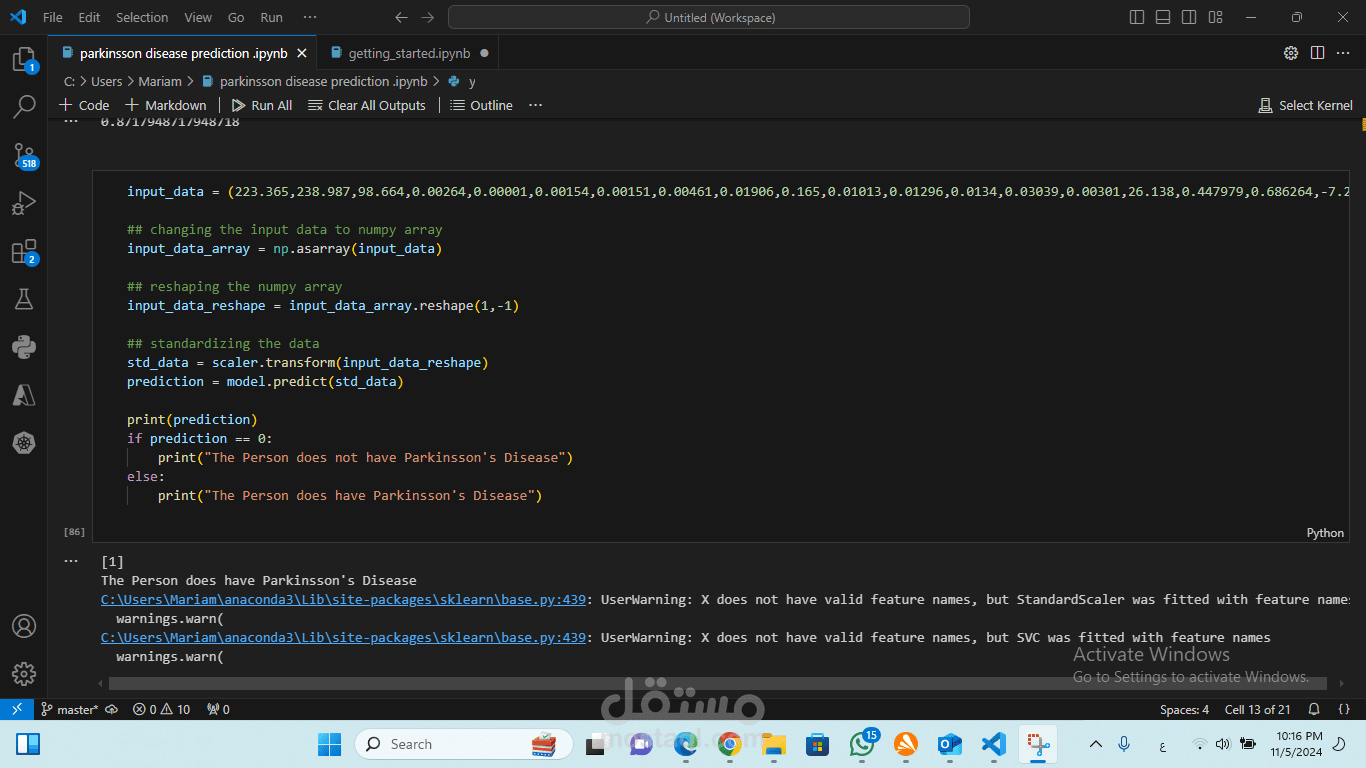
تقييم النموذج:
استخدام مجموعة من مقاييس الأداء مثل الدقة، معدل الاستجابة، وF1-score لضمان كفاءة النموذج.
إجراء اختبارات على نماذج الاختبار للتحقق من دقة الردود وجودة الإجابات.
نشر الشات بوت:
تطوير واجهة مستخدم تفاعلية باستخدام أطر عمل مثل Flask أو FastAPI.
دمج الشات بوت مع منصات الرسائل مثل WhatsApp أو Telegram لتوفير وصول أكبر.
ضمان استمرارية التحديث والتعلم من المحادثات السابقة لتحسين أداء الشات بوت.
الأدوات والتقنيات المستخدمة:
لغة البرمجة: Python
مكتبات: Pandas، NLTK، SpaCy، TensorFlow، PyTorch
بيئة البرمجة: Jupyter Notebook، VS Code
نشر الشات بوت: Flask أو FastAPI
أدوات إضافية: Docker للحاويات، Git للتحكم في الإصدارات، أدوات لتحليل البيانات مثل Matplotlib وSeaborn