Happiness dataset Regression Modeling
تفاصيل العمل

المشروع يتعلق بتحليل بيانات مؤشر السعادة العالمي وبناء نموذج للتنبؤ به.
اللغات المستخدمه : python
المكتبات المستخدمه :
المكتبات المستخدمة:
Pandas:
لتحميل البيانات ومعالجتها بسهولة. تتيح إجراء عمليات مثل الفلترة، والتجميع، وتنظيف البيانات.
NumPy:
لدعم العمليات الرياضية والمعالجة العددية، حيث يسهل التعامل مع المصفوفات والحسابات الإحصائية.
Matplotlib وSeaborn:
لإنشاء الرسوم البيانية والمرئيات المختلفة، بما في ذلك الرسوم البيانية المبعثرة، المخططات الخطية، وخرائط الارتباط، لفهم العلاقات بين المتغيرات وتصوير نتائج التحليل.
Scikit-Learn:
لبناء وتدريب نماذج الانحدار الخطي البسيط والمتعدد، وتقييم النموذج باستخدام مقاييس الأداء مثل MAE، MSE، RMSE، وR-squared. كما يتم استخدامها لتقسيم البيانات إلى مجموعة تدريب واختبار.
مراحل هذا المشروع:
جمع البيانات: يتم تحميل مجموعة بيانات تحتوي على معلومات عن العديد من الدول، بما في ذلك مؤشر السعادة، الناتج المحلي الإجمالي للفرد، الدعم الاجتماعي، متوسط العمر المتوقع الصحي، الحرية في اتخاذ قرارات الحياة، الكرم، والتصورات حول الفساد.
تحليل البيانات: يتم تحليل البيانات باستخدام مجموعة متنوعة من التقنيات الإحصائية والمرئية، مثل:
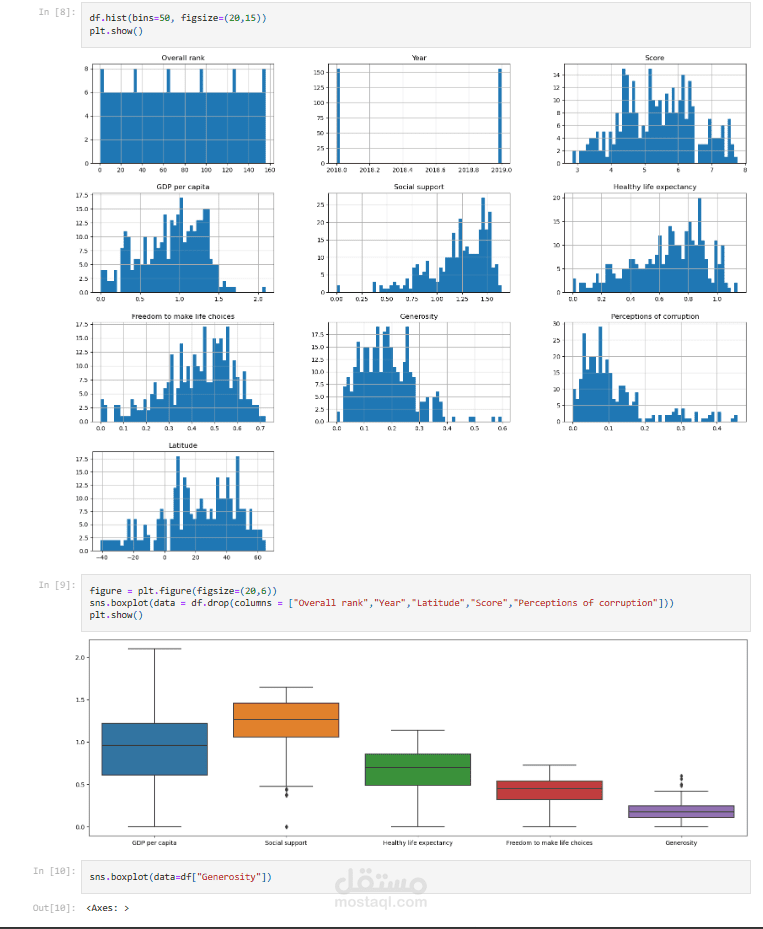
الإحصاء الوصفي: لحساب المتوسط والانحراف المعياري والحد الأدنى والحد الأقصى للقيم.
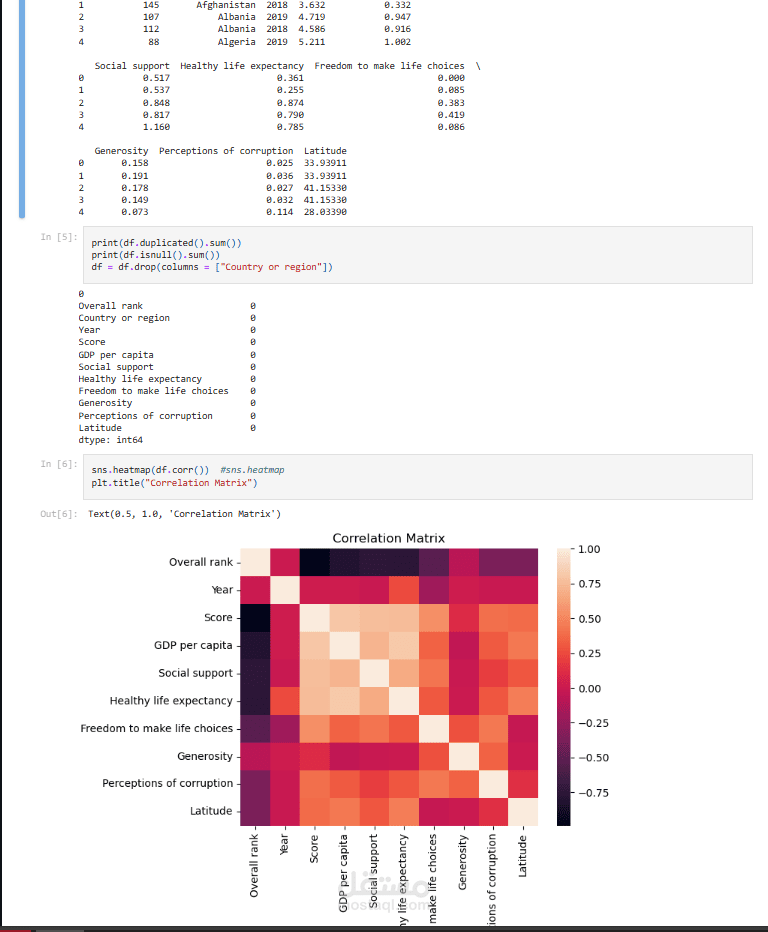
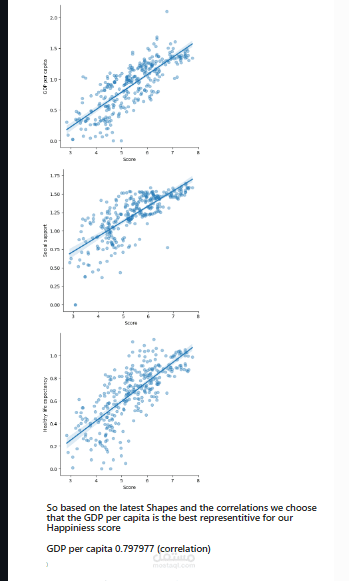
تحليل الارتباط: لمعرفة العلاقة بين مؤشر السعادة والعوامل الأخرى.
التصورات: مثل الرسوم البيانية والرسوم البيانية المبعثرة لفهم التوزيعات والعلاقات.
تنظيف البيانات: يتم التعامل مع القيم الشاذة والبيانات المفقودة لتحسين جودة البيانات.
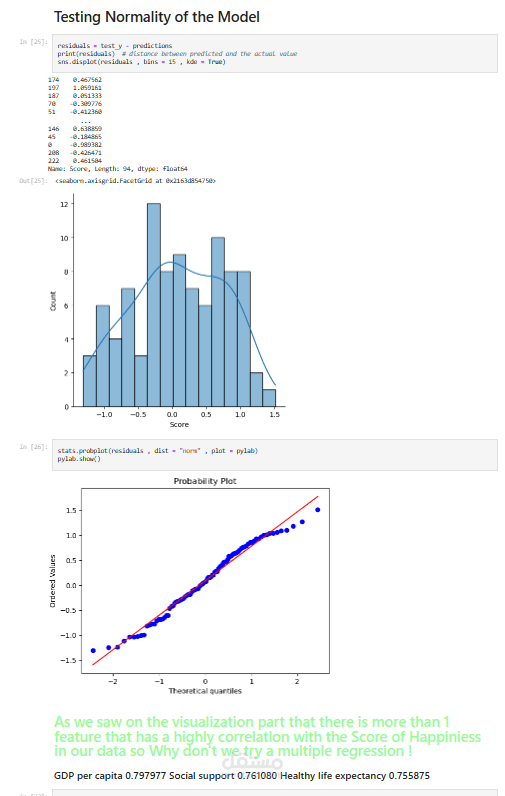
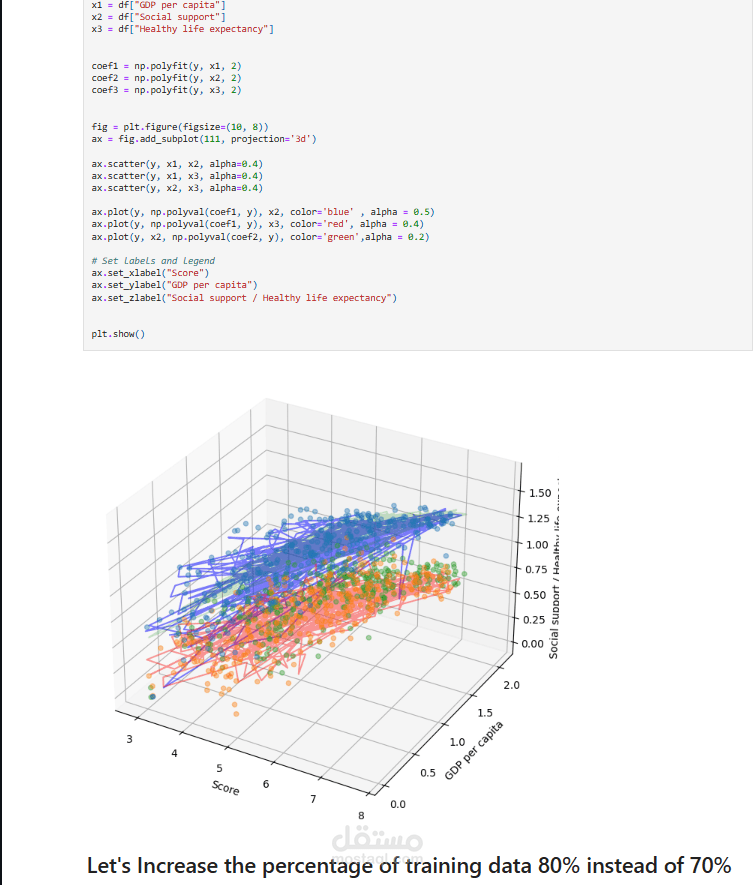
بناء النموذج: يتم بناء نموذج انحدار خطي للتنبؤ بمؤشر السعادة بناءً على العوامل المتعلقة به. تم تجربة نماذج مختلفة، بما في ذلك الانحدار الخطي البسيط والانحدار الخطي المتعدد.
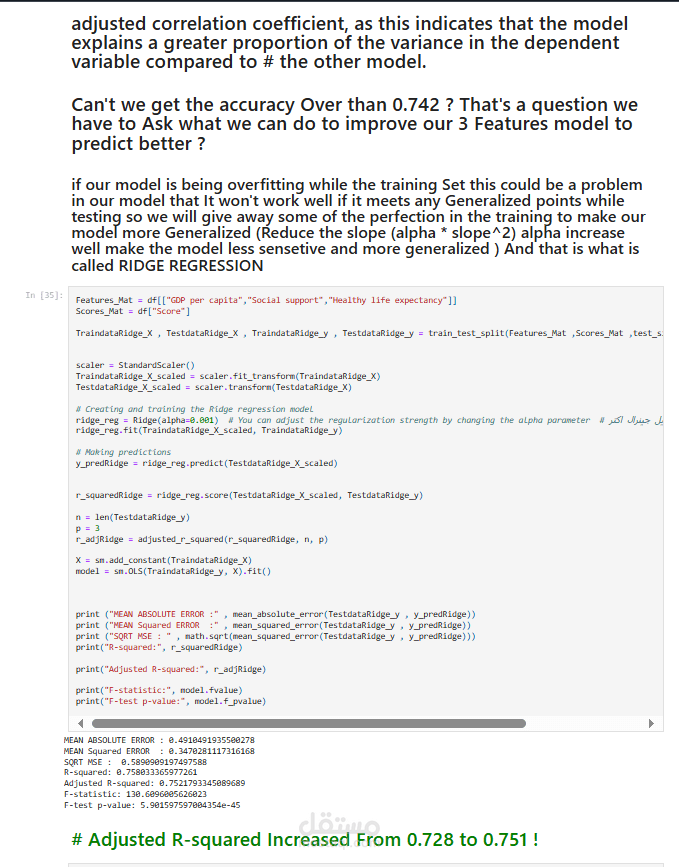
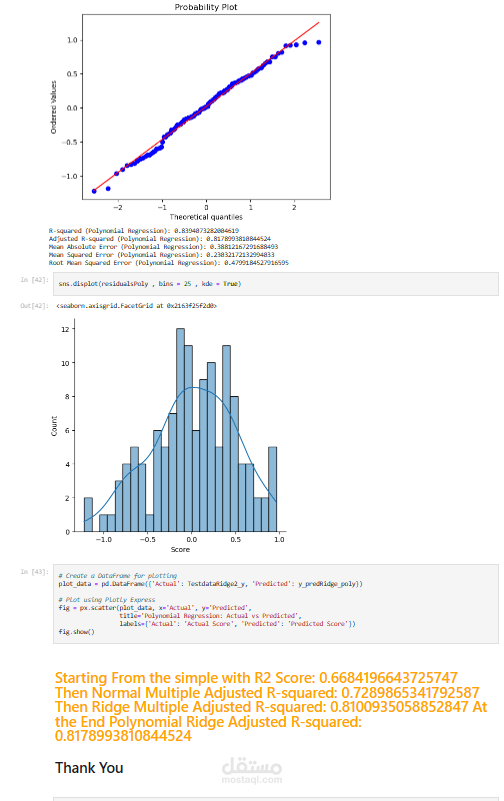
تقييم النموذج: يتم تقييم أداء النموذج باستخدام مقاييس مختلفة مثل الخطأ المطلق المتوسط، والخطأ التربيعي المتوسط، وجذر متوسط الخطأ التربيعي، ومعامل التحديد (R-squared).
تحسين النموذج: يتم إجراء تعديلات على النموذج لتحسين دقته، مثل إزالة المتغيرات غير ذات الصلة أو إضافة متغيرات جديدة.