Crop Prediction system (ML and web interface)
تفاصيل العمل
Project: Crop Prediction Using Random Forest Classifier
Objective
The objective of this project was to develop a machine learning model capable of predicting the type of crop suitable for cultivation based on various environmental and soil features.
About Dataset
Source : Get it in kaggel
Context
Precision agriculture is in trend nowadays. It helps the farmers to get informed decision about the farming strategy. Here, I present you a dataset which would allow the users to build a predictive model to recommend the most suitable crops to grow in a particular farm based on various parameters.
Context
This dataset was build by augmenting datasets of rainfall, climate and fertilizer data available for India.
Data fields
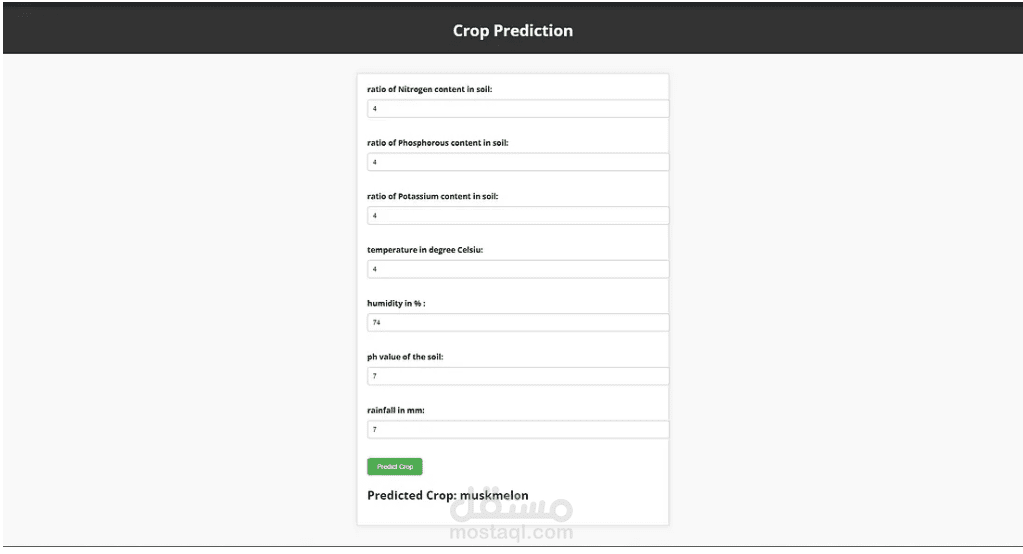
N - ratio of Nitrogen content in soil
P - ratio of Phosphorous content in soil
K - ratio of Potassium content in soil
temperature - temperature in degree Celsius
humidity - relative humidity in %
ph - ph value of the soil
rainfall - rainfall in mm
web interface
Data Preprocessing
Shape of the Data: The dataset was checked for its dimensions, and it was found to contain a specific number of rows and columns.
Data Cleaning:
Duplicate rows were identified and counted.
Missing values were identified and counted.
Encoding the Target Variable:
The categorical label column was encoded into numerical values using LabelEncoder.
A new column, label_encode, was created to store these encoded values.
Correlation Analysis:
A correlation matrix was computed to understand the relationship between the features and the target variable.
A heatmap was generated to visualize these correlations.
Feature Importance Analysis
Importance Calculation:
Feature importance was assessed using the absolute correlation values between features and the target variable.
Visualization:
A horizontal bar plot was generated to display the importance of each feature.
Model Development
Model Selection:
A Random Forest Classifier was chosen for its robustness and ability to handle complex data patterns.
Data Splitting:
The dataset was split into training and testing sets with an 80–20 ratio.
Model Training:
The model was trained using the training dataset.
Model Evaluation:
The model’s performance was evaluated on the testing dataset.
An accuracy score was computed, and a classification report was generated.
A confusion matrix was plotted to visualize the model’s prediction performance.
Model Deployment
Model Testing:
The trained Random Forest model was used to make predictions on new, unseen data.
Example test samples were provided, and the model predicted the corresponding crop types.
Model Persistence:
The trained model was saved using joblib for future use.
The saved model was later loaded and used for additional predictions.
Technologies Used
Programming Language: Python
Libraries:
Pandas: For data manipulation and analysis.
Matplotlib & Seaborn: For data visualization.
Scikit-learn: For machine learning model development and evaluation.
Joblib & Pickle: For model persistence and deployment.
Results
The Random Forest Classifier was successfully trained and evaluated, achieving a satisfactory accuracy on the test dataset. The model was able to predict the appropriate crop type based on environmental and soil features. The use of feature importance analysis provided insights into which features most influenced the predictions.
Future Work
Hyperparameter Tuning: Further tuning of the model’s hyperparameters could potentially improve accuracy.
Feature Engineering: Introducing new features or transforming existing ones might enhance model performance.
Model Deployment: Consider deploying the model as a web service for real-time crop prediction.
Nootebook : Here
This Flask application sets up a web service for predicting crop types based on environmental and soil features using a pre-trained Random Forest model. Below is a breakdown of the code:
Overview
Flask: A lightweight web framework for Python used to create the web service.
CORS: Cross-Origin Resource Sharing is enabled to allow requests from different domains.
Pickle: Used for loading the pre-trained Random Forest model.
Flask API Endpoint: An endpoint is created to handle POST requests and return predictions.
Conclusion
This project demonstrates a robust approach to predicting crop types using environmental data. The use of a Random Forest Classifier provided strong performance, and the model’s deployment ensures its practical utility for future predictions.