Building a Robust Loan Approval Prediction Model with 98% Accuracy
تفاصيل العمل

In the financial world, accurate loan approval predictions are crucial. Predicting whether a loan applicant is likely to default helps financial institutions make informed decisions, reducing risk and enhancing profitability. In this project, I developed a machine learning model that predicts loan approval with an impressive accuracy of 98%.
check Notebook in Kaggel
Project Overvie
The goal of this project was to create a predictive model that determines whether a loan should be approved based on various features such as applicant income, loan amount, credit history, and property area. The dataset used is a popular one in the domain of credit scoring, often employed for binary classification problems.
Key Steps in the Project
Data Preprocessing:
Missing Values: Handled missing data by either imputing with appropriate statistical measures or dropping rows where necessary.
Feature Engineering: Created new features and transformed existing ones to better capture the relationships within the data.
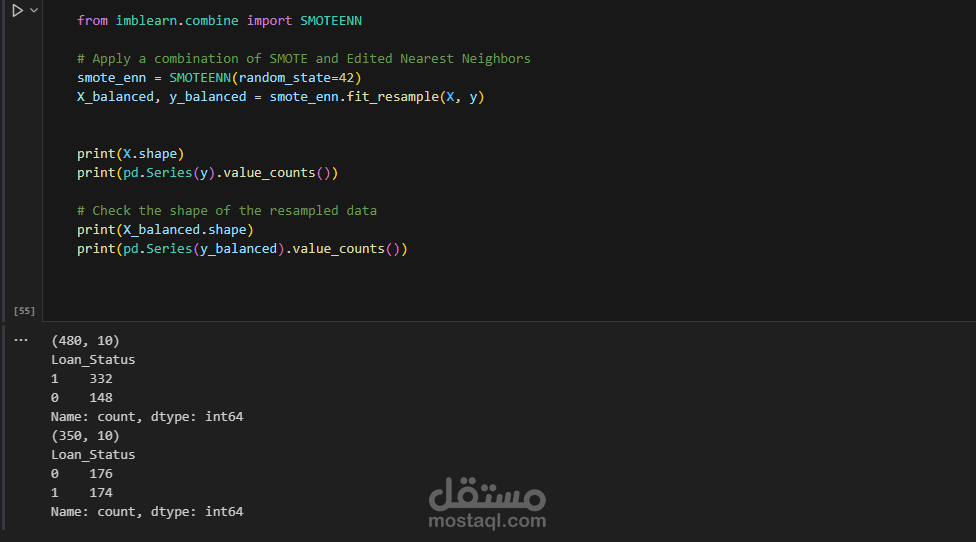
Balancing the Dataset:
Imbalanced datasets can lead to biased models. To address this, I applied the SMOTEENN (Synthetic Minority Over-sampling Technique and Edited Nearest Neighbors) technique. This method not only oversamples the minority class but also cleans the dataset by removing noisy examples.
Model Training:
I chose a RandomForestClassifier for this task, known for its robustness and ability to handle complex data without overfitting.
The model was trained on a balanced dataset to ensure it performs well across all classes.
Model Evaluation:
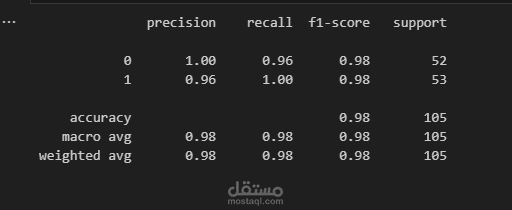
The model was evaluated using metrics such as precision, recall, f1-score, and overall accuracy. The final model achieved a stunning accuracy of 98% on the test set.
Key Insights
Feature Importance: Credit history, loan amount, and applicant income emerged as key features influencing loan approval decisions.
Data Balancing: The use of SMOTEENN was pivotal in achieving high model accuracy, ensuring that the model is not biased toward the majority class.
Challenges Faced
Imbalanced Data: Initially, the model was biased due to an imbalanced dataset. Implementing SMOTEENN helped address this challenge effectively.
Hyperparameter Tuning: Tuning the hyperparameters of the Random Forest model was crucial for optimizing its performance.
Final Model Performance
The model’s performance was evaluated using a holdout test set, achieving the following metrics:
Precision: 98%
Recall: 98%
F1-Score: 98%
Overall Accuracy: 98%
These results indicate that the model is well-balanced and capable of making reliable predictions on unseen data.
Next Steps
Model Deployment: The next phase of this project involves deploying the model using a framework like Flask or Django, making it accessible as an API.
Exploring Other Models: Although RandomForest performed exceptionally well, exploring other models like XGBoost or LightGBM might offer even better performance.
Hyperparameter Optimization: Further tuning of model hyperparameters using GridSearchCV or RandomizedSearchCV could fine-tune the model’s performance.
Conclusion
This project demonstrates the power of data preprocessing, balancing techniques, and robust model selection in building a high-performance machine learning model. By applying SMOTEENN and using a RandomForestClassifier, I was able to achieve an accuracy of 98% on loan approval predictions.
I hope this project inspires others to explore the fascinating world of machine learning and its applications in the financial sector. If you have any questions or suggestions, feel free to reach out or leave a comment below!