التعامل مع Anomalies في اكتشاف التطفل باستخدام التعلم الآلي
تفاصيل العمل
التعامل مع Anomalies في اكتشاف التطفل باستخدام التعلم الآلي
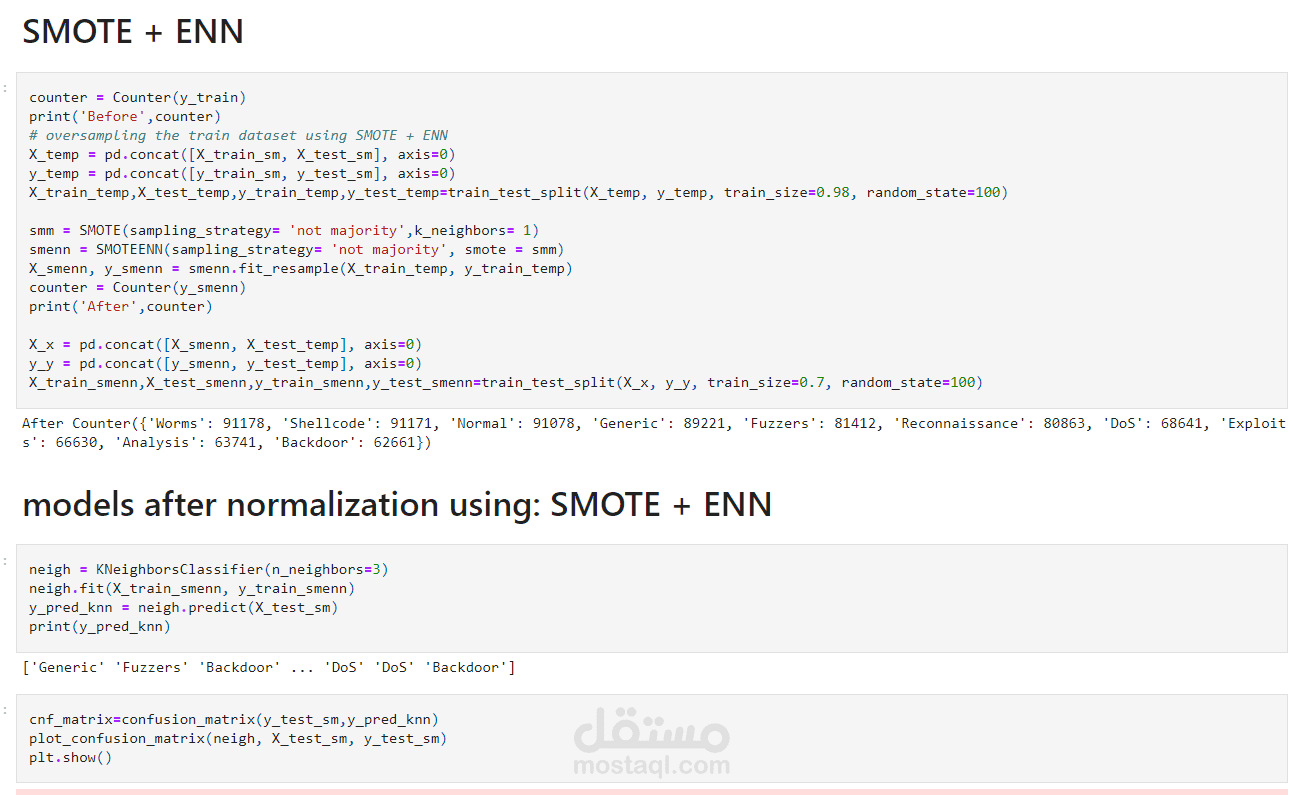
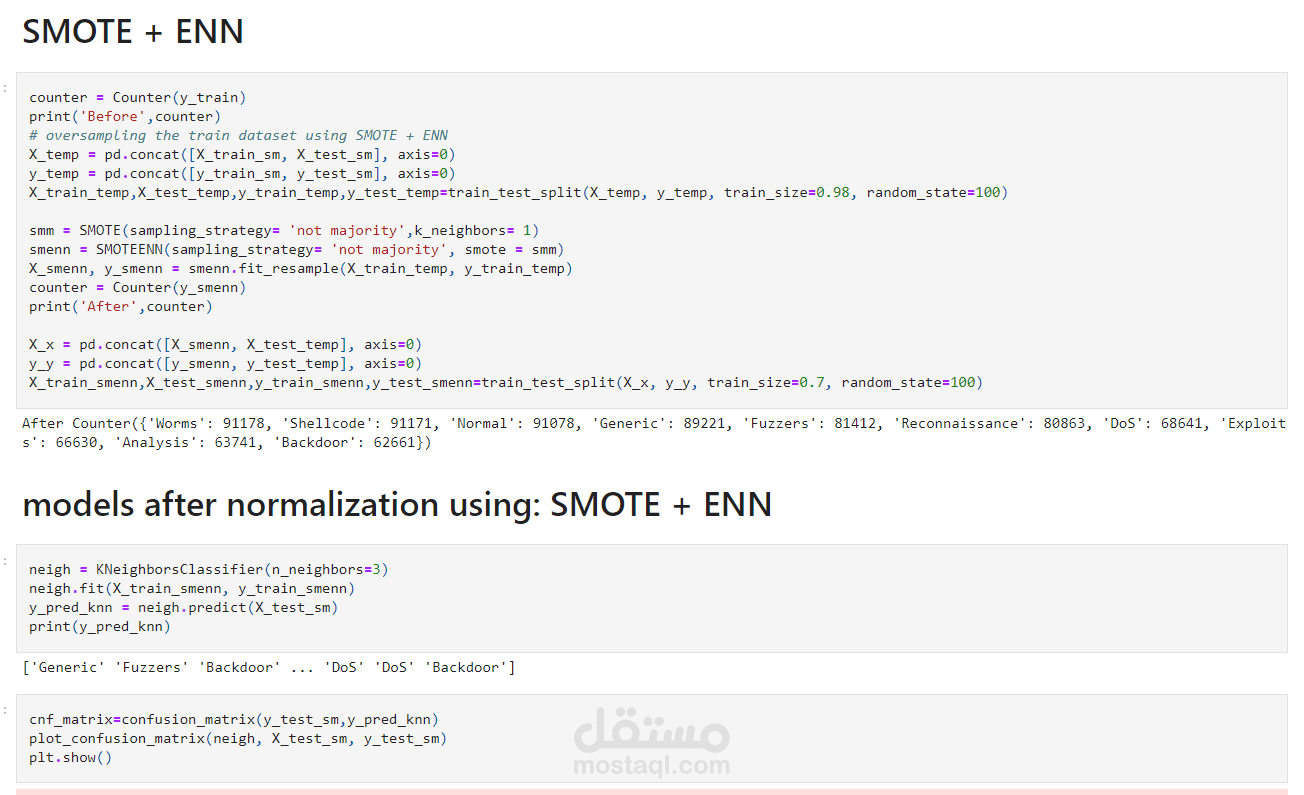
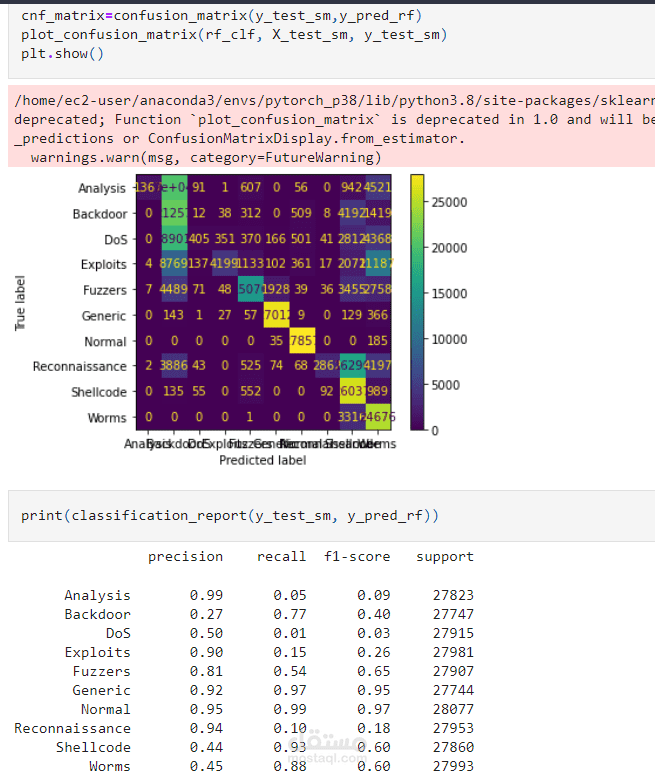
يعد الكشف عن التسلل جانبًا مهمًا من جوانب أمن الشبكة لتحديد أي وصول غير مصرح به إلى أنظمة الكمبيوتر. يمكن استخدام خوارزميات التعلم الآلي لتحديد هذه الحالات الشاذة وتحسين دقة اكتشاف التطفل. يقدم هذا المستودع عرضًا توضيحيًا للتعامل مع الحالات الشاذة في اكتشاف التطفل باستخدام ثلاث خوارزميات للتعلم الآلي: Random Forest (RF) و Support Vector Classifier (SVC) و K-Nearest Neighbors (KNN N) وثلاث مجموعات بيانات: ، NSSDD D D.
الاحتياجات
بايثون 3.x
NumPy
بانداس
ماتبلوتليب
Scikit-learn
التعلم غير المتوازن
مجموعات البيانات
KDD99: تُستخدم مجموعة البيانات هذه على نطاق واسع في أبحاث الكشف عن التسلل وقد تم معالجتها مسبقًا لسهولة الاستخدام.
NSL-KDD: مجموعة البيانات هذه هي تحسن عن مجموعة بيانات KDD99، وتعالج بعض حدودها.
UNSW-NB15: تم تصميم مجموعة البيانات هذه لتعكس سيناريوهات العالم الحقيقي وتحتوي على مزيج من حركة المرور العادية وغير الطبيعية للشبكة.
خوارزميات التعلم الآلي
الغابة العشوائية (RF): RF هي طريقة تعلم جماعية للتصنيف والانحدار والمهام الأخرى التي تعمل عن طريق بناء العديد من أشجار القرار في وقت التدريب وإخراج الفصل الذي هو أسلوب الفصول (التصنيف) أو التنبؤ (الانحدار) من الأشجار الفردية.
Support Vector Classifier (SVC): SVC هو نموذج خطي لتحليل التصنيف والانحدار. يتم استخدامه للعثور على طائرة مفرطة تفصل البيانات بشكل أفضل إلى فئات مختلفة.
K-Nearest Neighbors (KNN): KNN هي خوارزمية بسيطة تخزن جميع الحالات المتاحة وتصنف الحالات الجديدة بناءً على مقياس التشابه. يمكن أن تكون المسافة، على سبيل المثال، مسافة إقليدية.