Cyber Bullying Classification using RoBERTa
تفاصيل العمل
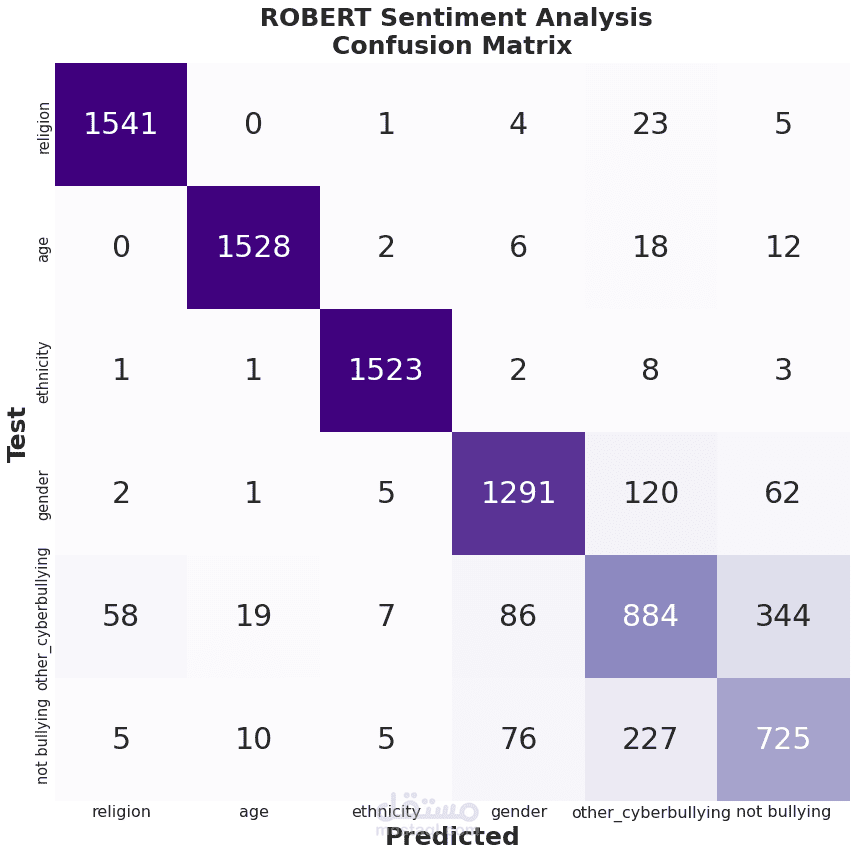
The purpose of the project is to detect bullying in Twitter’s tweets. I have used the Cyberbullying Classification dataset which was available on the Kaggle website. After the dataset cleaning process, I fine-tuned the ROBERTA large language model on the dataset. The achieved accuracy was 87%.