Spam Detection System
تفاصيل العمل

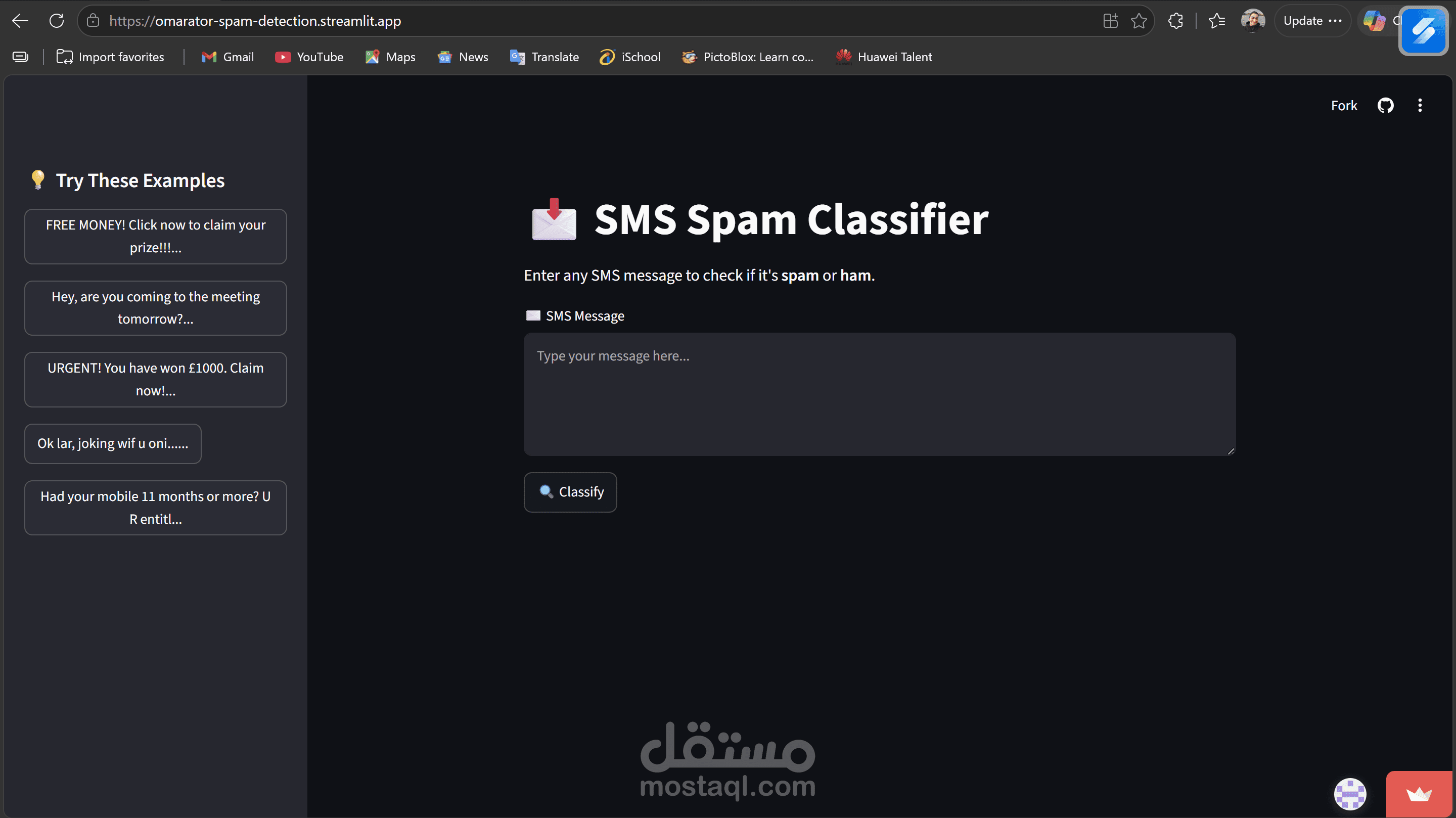
تطوير وبناء نظام متكامل يعتمد على معالجة اللغات الطبيعية (NLP) وخوارزميات التعلم الآلي لتصنيف وكشف الرسائل والنصوص المزعجة (Spam). يتضمن المشروع تصميم خط معالجة بيانات متقدم (Text-Processing Pipeline) لتنظيف النصوص واستخلاص الميزات بدقة عالية، مما ساهم في تحقيق نسبة دقة تصنيف فائقة تجاوزت %94. تم نشر النموذج وتطبيقه بالكامل في بيئة إنتاجية تفاعلية باستخدام إطار عمل Streamlit، مع تحسين الأكواد البرمجية لتقليل زمن استجابة وتنفيذ عمليات الفحص (Execution Latency) بنسبة %40 لضمان معالجة فورية وسلسة