data analysis
تفاصيل العمل
What's This About?
This is a data mining project focused on predicting customer churn — meaning, figuring out which customers of a telecom company are likely to leave. The dataset used is the well-known Telco Customer Churn dataset from Kaggle, which includes details about ~7,000 customers: their demographics, the services they subscribe to, billing information, and whether they ended up leaving the company.
The Dataset
Each customer record covers 21 attributes, including things like gender, whether they're a senior citizen, how long they've been a customer (tenure), their internet and phone services, contract type, payment method, monthly charges, and of course — whether they churned or not.
What Was Done
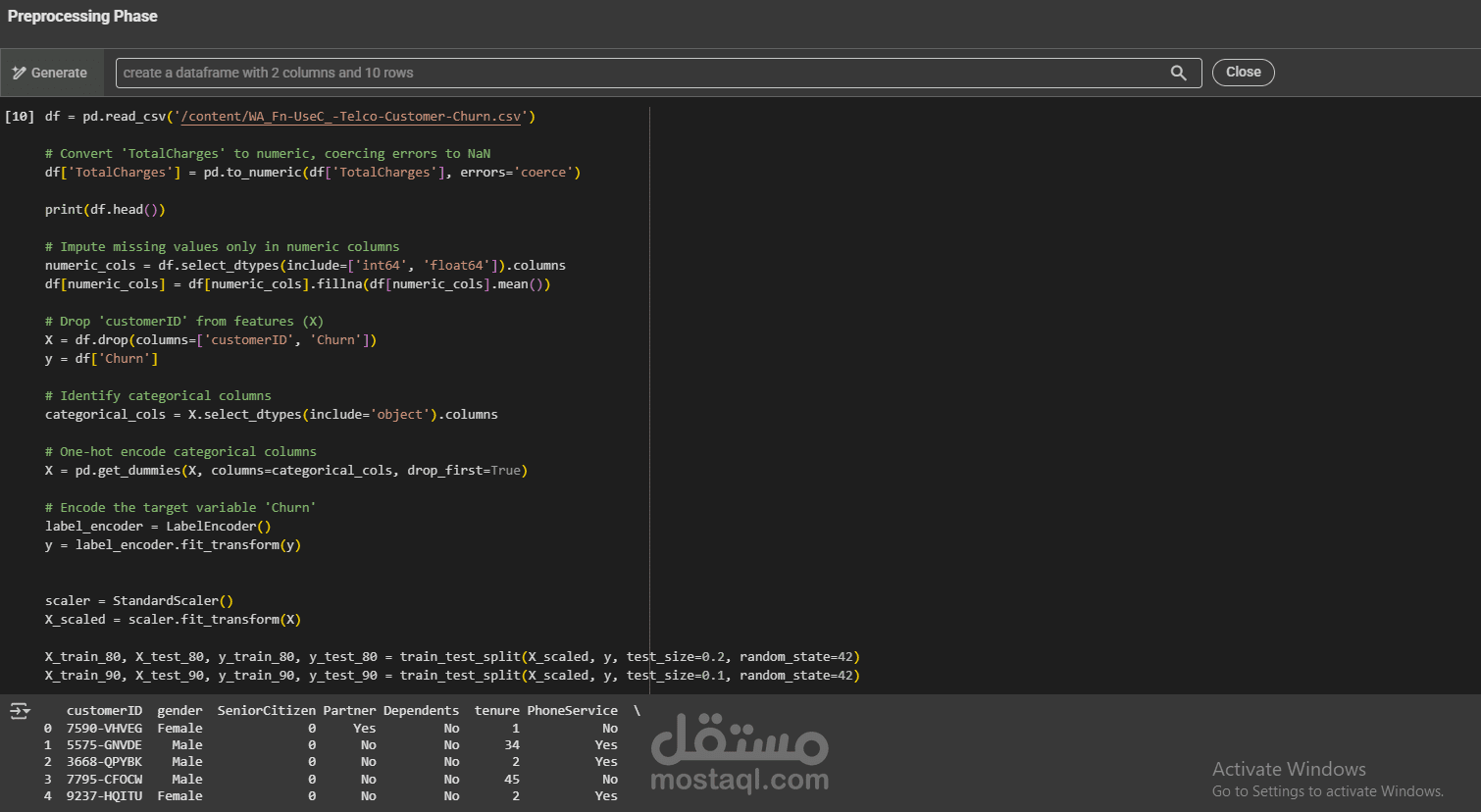
The workflow followed a classic data mining pipeline:
Data loading & inspection — The CSV was loaded and given an initial once-over.
Preprocessing — Missing values were filled in (using column means for numerical data), the customerID column was dropped (it's not useful for prediction), categorical columns were one-hot encoded, and all numerical features were scaled using StandardScaler.
Train/test splitting — The data was split two ways: an 80/20 split and a 90/10 split, to see how model performance varies with more or less training data.
Model training — Three classification algorithms were trained and compared:
Logistic Regression
Decision Tree
K-Nearest Neighbors (KNN, with k=3)