Big Data
تفاصيل العمل
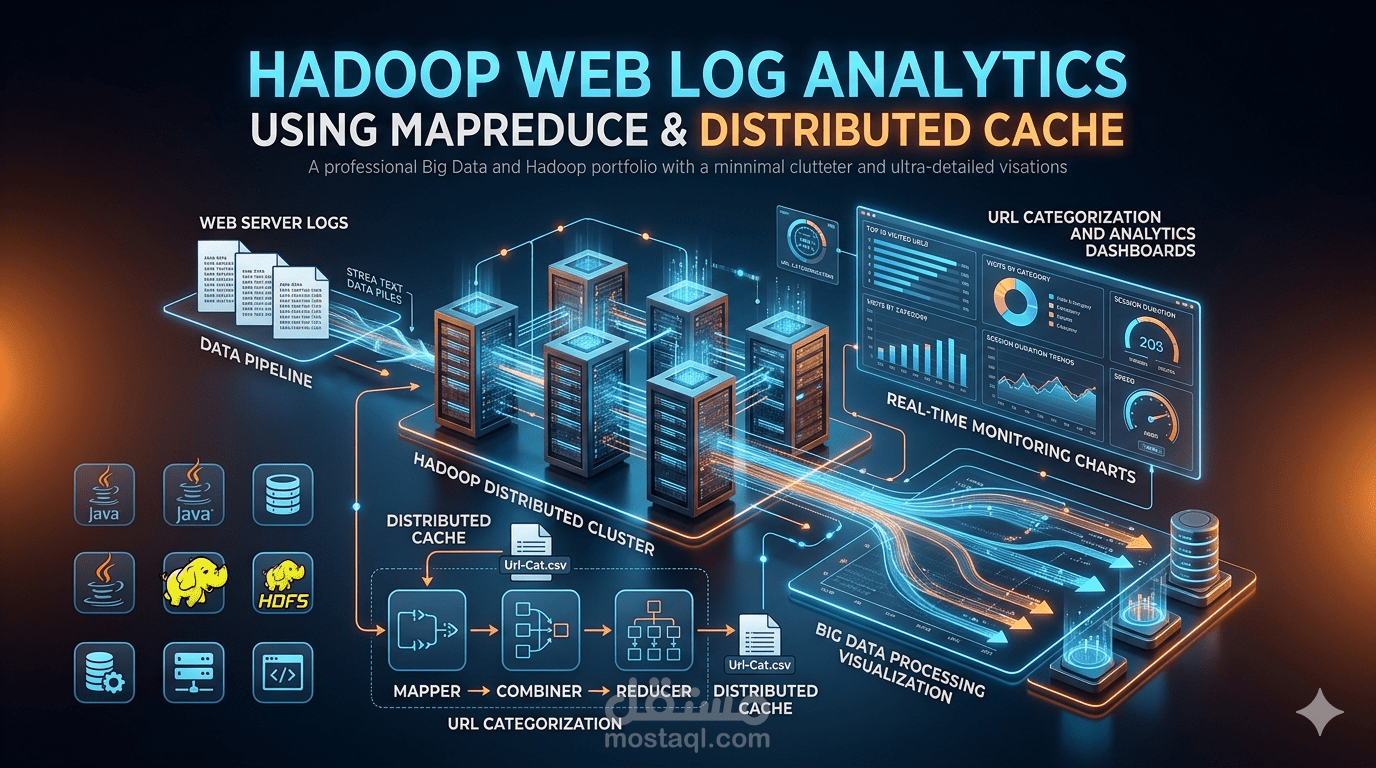
قمت بتطوير مشروع Big Data باستخدام Hadoop MapReduce لتحليل Web Server Logs وتصنيف طلبات URLs باستخدام Distributed Cache داخل بيئة Hadoop، بهدف تحسين تحليل الأداء واستخراج إحصائيات دقيقة عن استخدام صفحات الويب.
يعتمد المشروع على قراءة ملفات Log ضخمة ومعالجة ملايين الطلبات باستخدام MapReduce مع تصنيف الروابط إلى فئات مختلفة مثل صفحات المنتجات، البحث، تسجيل الدخول، الصور، وعربة التسوق.
يتضمن المشروع:
تصميم وتنفيذ Mapper وReducer وCombiner وDriver باستخدام Java
استخدام Hadoop Distributed Cache لتحميل ملف تصنيف الـ URLs داخل الـ Mapper
تحليل ملفات Web Logs كبيرة الحجم داخل بيئة Hadoop
تصنيف الطلبات حسب نوع الصفحة (ProductPage, SearchPage, Auth, Cart وغيرها)
حساب عدد الطلبات ومتوسط زمن الاستجابة وعدد الأخطاء لكل فئة
استخدام Combiner لتحسين الأداء وتقليل حجم البيانات المنقولة بين مراحل المعالجة
تنفيذ Data Validation للتعامل مع السجلات غير الصحيحة أو التالفة
تشغيل المشروع باستخدام HDFS داخل بيئة Cloudera Hadoop
كما تم اختبار المشروع على Dataset كبيرة الحجم لمحاكاة أنظمة تحليل الـ Logs الحقيقية وتحسين كفاءة المعالجة الموزعة واستخراج مؤشرات الأداء الخاصة بالخادم.