Hadoop MapReduce Grade Level Partitioning System
تفاصيل العمل
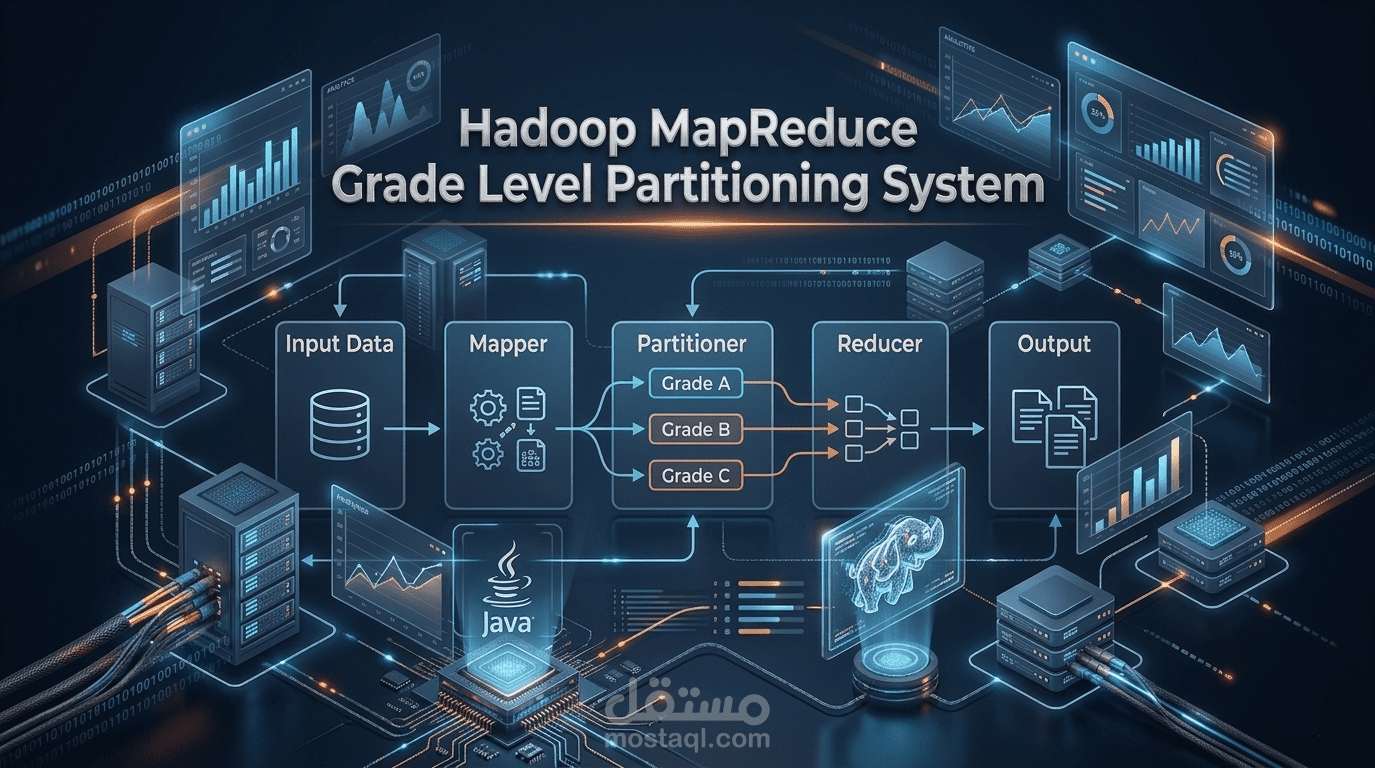
وصف العمل
قمت بتطوير مشروع Big Data باستخدام Hadoop MapReduce لتحليل ومعالجة بيانات المدارس بكفاءة عالية، مع تطبيق Custom Partitioner لتوزيع البيانات على عدة Reducers بحيث يقوم كل Reducer بمعالجة Grade Level محدد بشكل مستقل لتحسين الأداء وتنظيم المعالجة الموزعة.
يتضمن المشروع:
تصميم وتنفيذ مكونات Hadoop الأساسية: Mapper وReducer وPartitioner وDriver باستخدام Java
معالجة وتحليل ملفات بيانات ضخمة تتجاوز 1GB داخل بيئة Hadoop
تطبيق Custom Partitioner لتوزيع البيانات حسب Grade Level لتحسين كفاءة التنفيذ
حساب عدد الطلاب والمعلمين وإجمالي السجلات لكل صف دراسي
تنفيذ Data Validation للتعامل مع السجلات غير الصحيحة أو غير المكتملة
استخدام Hadoop Counters لتتبع الأخطاء ومراقبة جودة البيانات أثناء التشغيل
تشغيل المشروع باستخدام HDFS داخل بيئة Cloudera Hadoop
دعم Multi-Reducer Execution لمحاكاة أنظمة المعالجة الموزعة في مشاريع Big Data الحقيقية
كما تم اختبار المشروع على Dataset كبيرة الحجم لمحاكاة بيئات العمل الواقعية وتحسين كفاءة توزيع البيانات والمعالجة المتوازية.