شركة طيران (بايثون)
تفاصيل العمل
أُجريت مرحلة المعالجة المسبقة في Google Colab باستخدام مكتبة Pandas. تم تحميل كل جدول من ملفات Excel منفصلة إلى DataFrame مستقل، وفُحص باستخدام الدالة .info() لتحديد المشكلات الهيكلية قبل تطبيق أي عملية تنظيف.
تم تحديد المشكلات التالية وحلها: حُذف عمودان فارغان غير مُسميين في جدول الحجوزات لعدم احتوائهما على بيانات. تم تخزين القيم الفارغة في عمودي actual_departure و actual_arrival كسلسلة نصية '\N' بدلاً من القيم الفارغة الحقيقية، وتم استبدالها بـ pd.NaT قبل تحويلها إلى تنسيق التاريخ والوقت. تم تخزين جميع أعمدة التاريخ والوقت في جداول الرحلات والحجوزات والتقييمات كسلاسل نصية عادية، ثم تم تحويلها إلى تنسيق التاريخ والوقت الصحيح باستخدام pd.to_datetime().
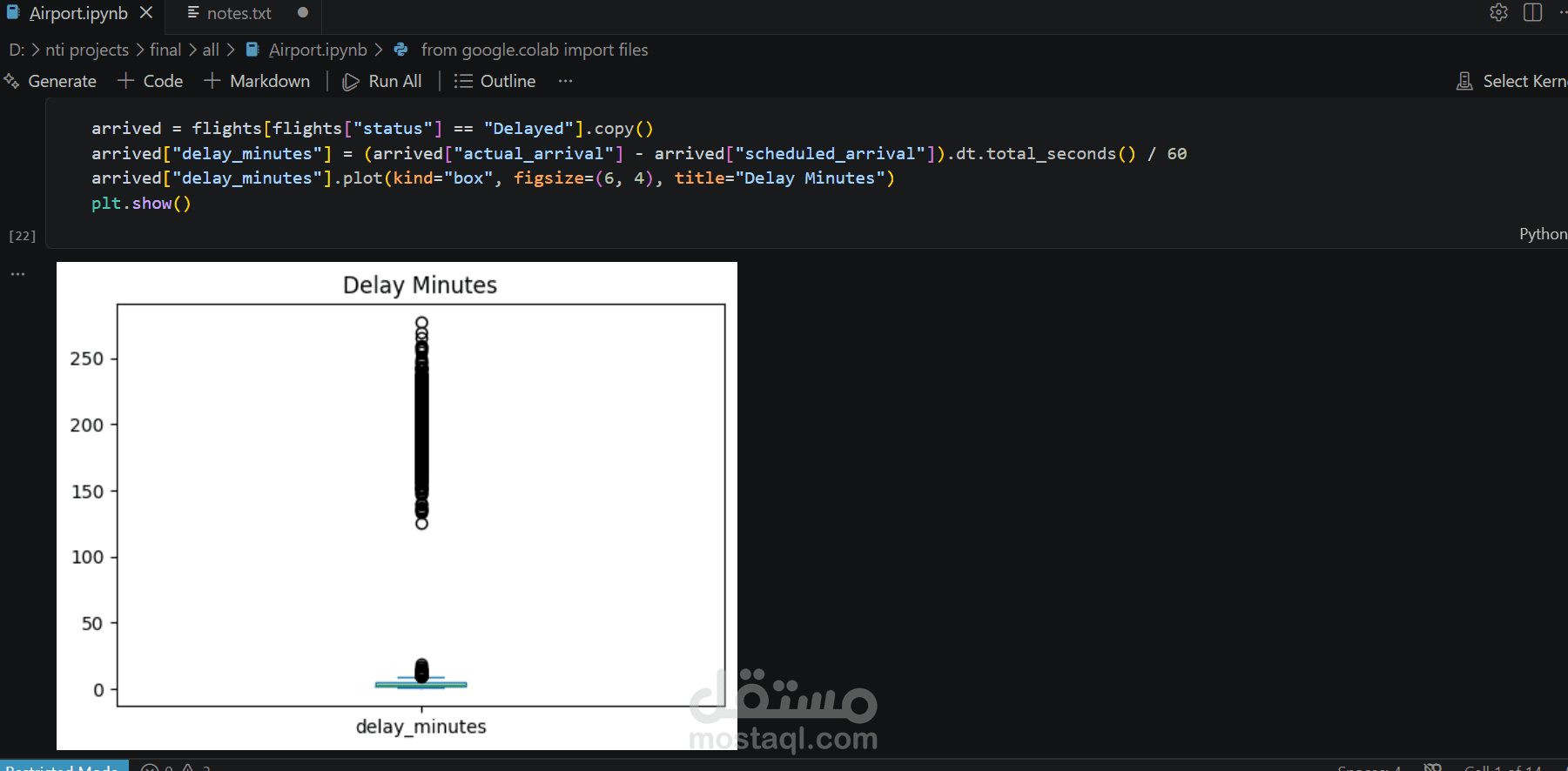
تم تخزين أسماء طرازات الطائرات وأسماء المطارات وأسماء المدن بتنسيق JSON ثنائي اللغة يحتوي على نصوص باللغتين الإنجليزية والروسية. تم استخراج القيم الإنجليزية باستخدام مطابقة أنماط التعبيرات النمطية على المفتاح 'en'. تم تحديد 41 رحلة متأخرة بدون أوقات مغادرة فعلية على أنها تناقضات في البيانات، وتم حذفها. أُعيد تصنيف الرحلات إما كمتأخرة أو في الموعد المحدد، وذلك بمقارنة وقت الوصول الفعلي بوقت الوصول المقرر. الرحلات التي تجاوز وقت وصولها الفعلي وقت الوصول المقرر صُنفت كمتأخرة. وأخيرًا، تم فحص القيم الشاذة في دقائق التأخير، وقيمة التذاكر، وإجمالي الحجوزات، ومدى الطائرة، وتبين أن جميع القيم الشاذة قابلة للتفسير، فتم الاحتفاظ بها في مجموعة البيانات.