Titanic Data- leaning
تفاصيل العمل
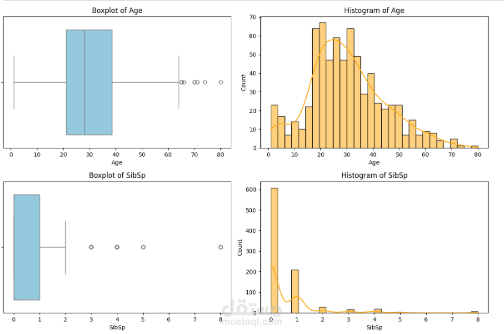
This repository contains a comprehensive data cleaning and preprocessing pipeline for the Titanic dataset. The primary objective of this project is to transform raw, unstructured data into a high-quality dataset suitable for advanced statistical analysis and machine learning applications.