Airflow Data Engineering Pipeline
تفاصيل العمل
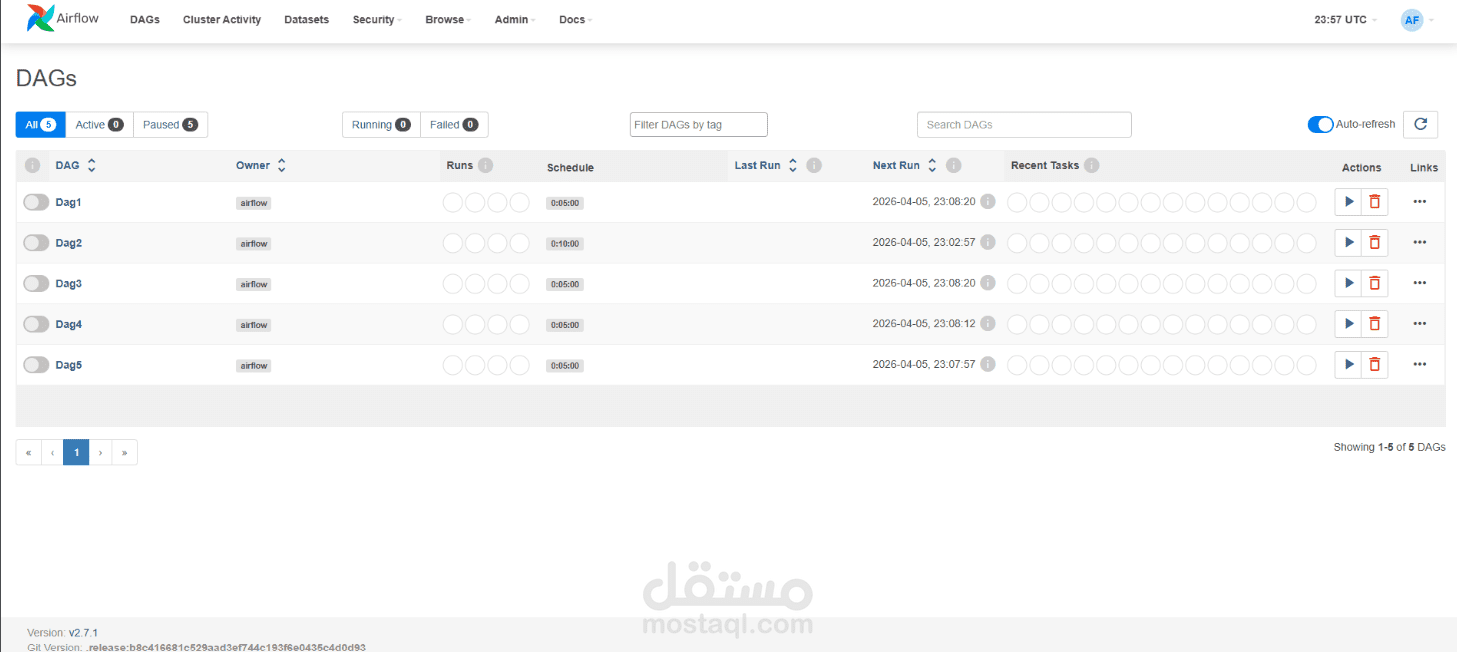
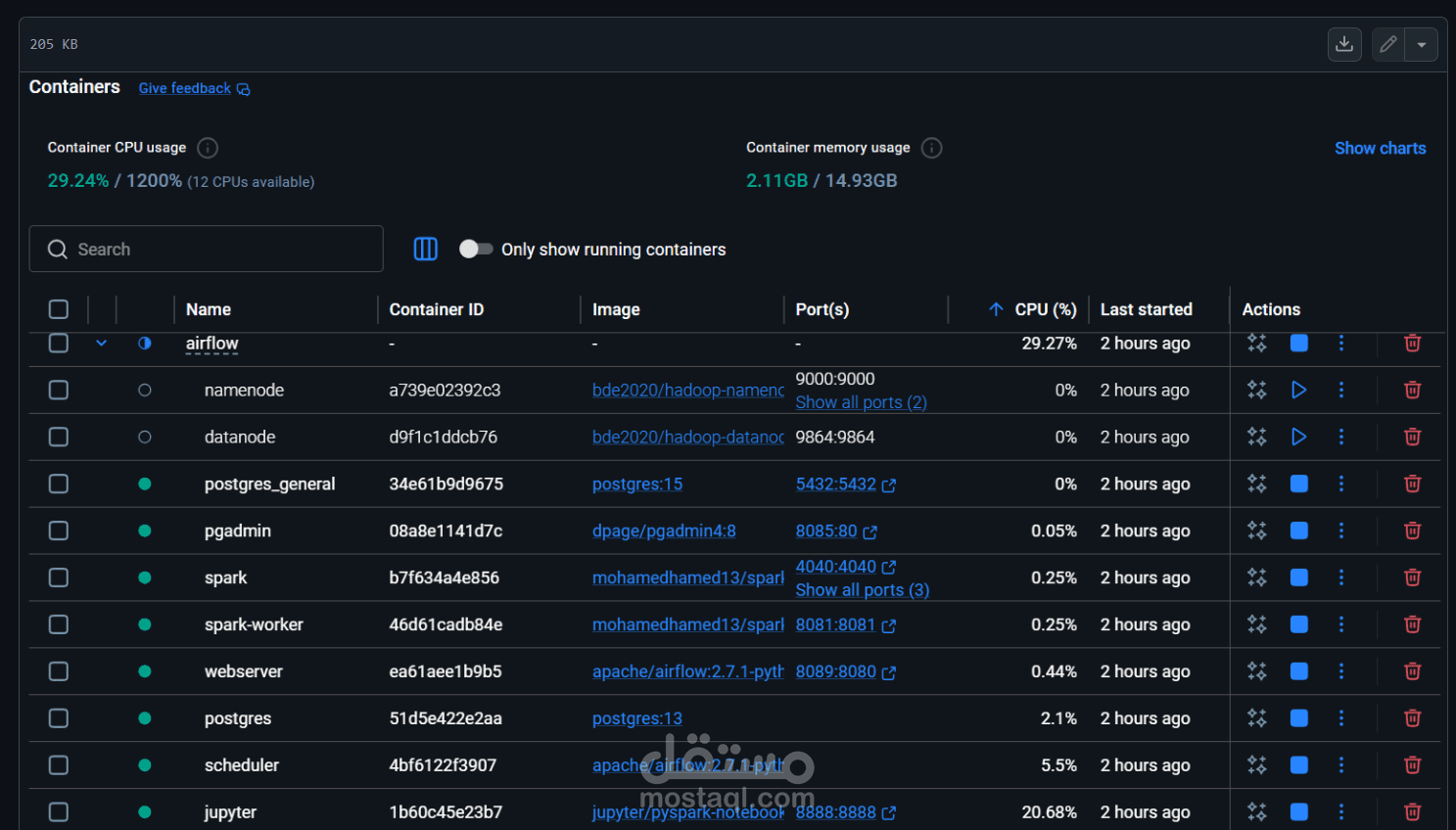
This project demonstrates a production-grade Data Engineering architecture built using Docker Compose to simulate a scalable and modular big data environment. It follows a multi-node distributed setup that integrates several industry-standard tools to manage data workflows, storage, and processing.
At the orchestration layer, **Apache Airflow** is used to define, schedule, and monitor end-to-end data pipelines, ensuring reliable and automated workflow execution. The data storage layer is handled by **PostgreSQL**, acting as a structured data warehouse for storing processed and analytics-ready datasets.
For large-scale data processing, the system leverages a **Spark and Hadoop-based distributed computing environment**, enabling efficient handling of high-volume transaction data through parallel processing and fault-tolerant execution.
The pipeline automates the full lifecycle of data ingestion, including extracting raw transactional data, transforming it through cleaning, aggregation, and standardization logic, and loading it into the warehouse for downstream analysis.
Overall, the project simulates a real-world production data platform, focusing on scalability, automation, and reliability in processing transactional data workflows.