Income Prediction Using Supervised Machine Learning
تفاصيل العمل




نظام توقع مستوى الدخل باستخدام Supervised Machine Learning
في هذا المشروع قمت ببناء نموذج تعلم آلة للتنبؤ بما إذا كان دخل الفرد أكبر من 50,000 دولار سنويا أم لا، باستخدام بيانات Census Income Dataset.
بدأ العمل بمرحلة استكشاف البيانات لفهم شكل البيانات، عدد السجلات، توزيع الفئات، وأنواع الأعمدة الرقمية والتصنيفية. بعد ذلك تم تنفيذ مرحلة المعالجة المسبقة للبيانات، والتي شملت فصل الخصائص عن الهدف، التعامل مع الأعمدة الرقمية والتصنيفية، تحويل القيم شديدة الانحراف باستخدام Log Transformation، تحويل البيانات النصية إلى بيانات رقمية باستخدام One-Hot Encoding، ثم تطبيق Standard Scaling على الأعمدة الرقمية.
بعد تجهيز البيانات، تم تقسيمها إلى Training Set و Testing Set، ثم تدريب أكثر من نموذج تعلم آلة للمقارنة بينهم، وهي:
Logistic Regression
Random Forest Classifier
XGBoost Classifier
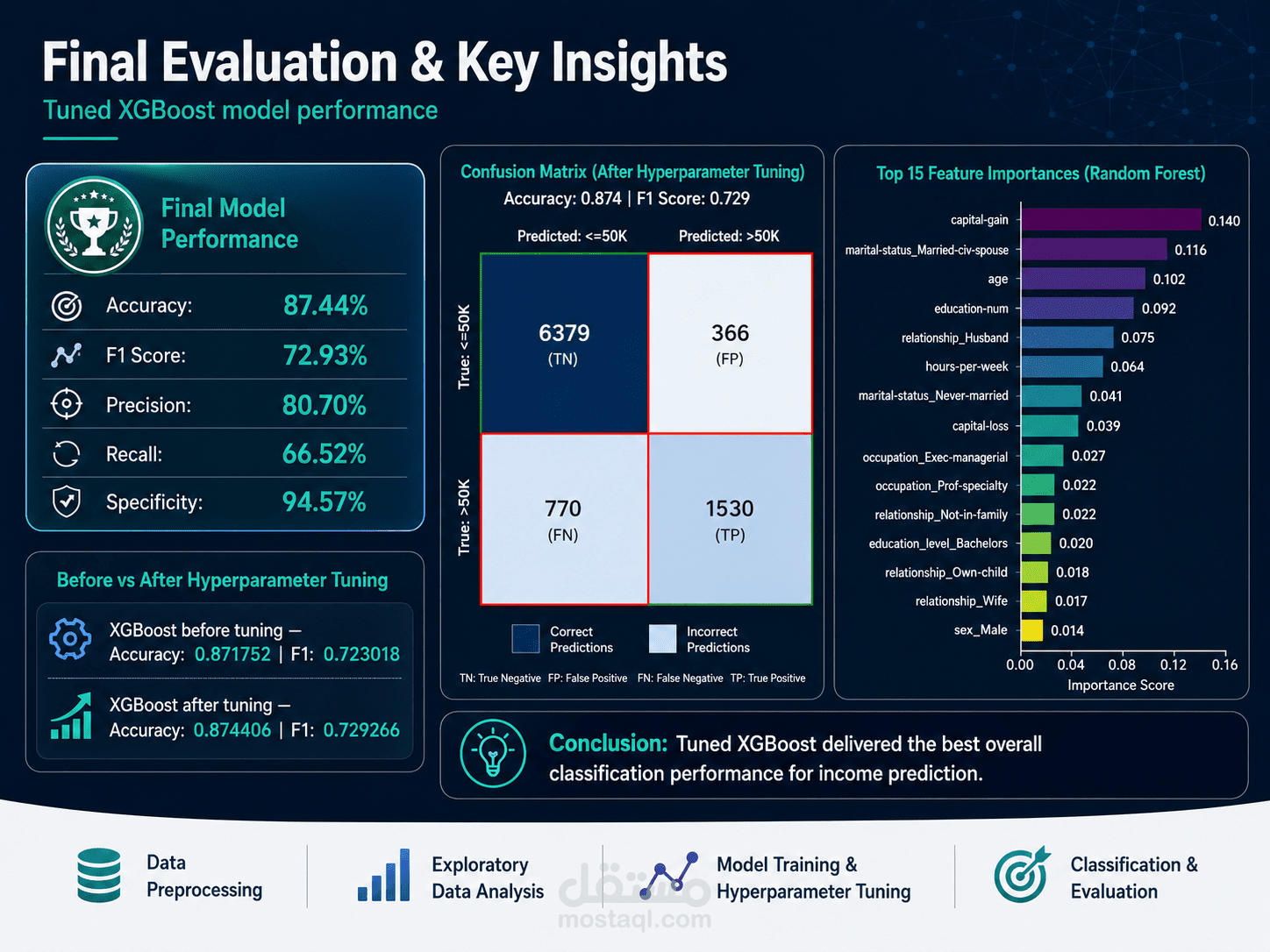
تم تقييم النماذج باستخدام Accuracy و F1 Score و Training Time، ثم تم اختيار نموذج XGBoost كأفضل نموذج لأنه حقق أعلى أداء مقارنة بباقي النماذج.
بعد ذلك تم تحسين أداء النماذج باستخدام GridSearchCV لاختيار أفضل Hyperparameters. وكانت النتيجة النهائية أن نموذج XGBoost بعد التحسين حقق:
Accuracy: 87.44%
F1 Score: 72.93%
Precision: 80.70%
Recall: 66.52%
Specificity: 94.57%
كما تم عرض Confusion Matrix لتوضيح أداء النموذج بالتفصيل، بالإضافة إلى تحليل أهم الخصائص المؤثرة في التوقع مثل capital-gain و age و education-num و marital-status.
المشروع يوضح دورة عمل كاملة لمشروع Machine Learning بداية من تحليل البيانات وحتى تقييم النموذج النهائي واستخراج النتائج.