Real-Time User Data Pipeline
تفاصيل العمل
? مشروع Real-Time Data Pipeline — Kafka · Spark · HDFS · Airflow
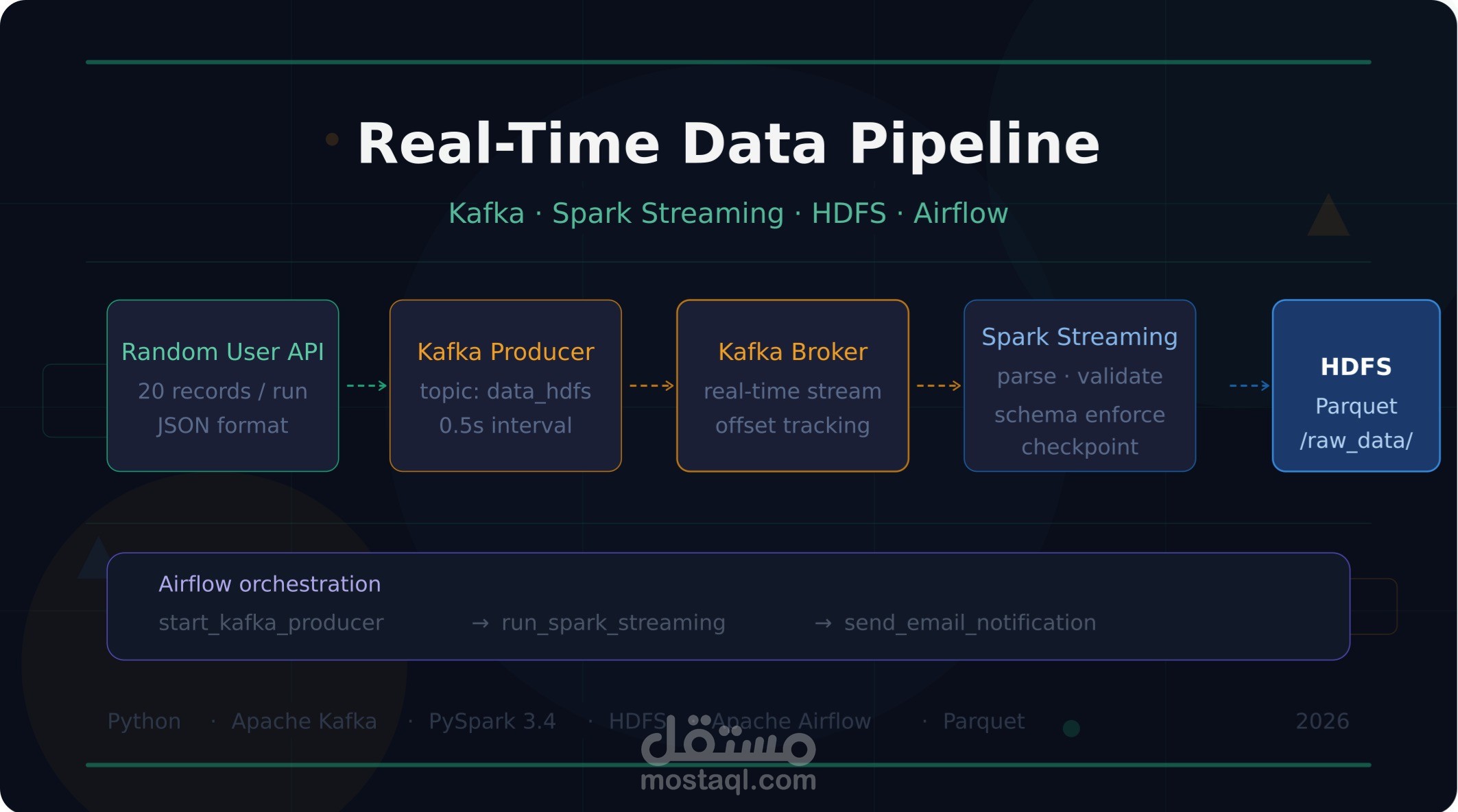
قمت ببناء pipeline لمعالجة البيانات بشكل فوري (Real-Time) باستخدام أحدث أدوات هندسة البيانات، وذلك عبر 4 مراحل متكاملة:
1️⃣ جمع البيانات (Data Ingestion)
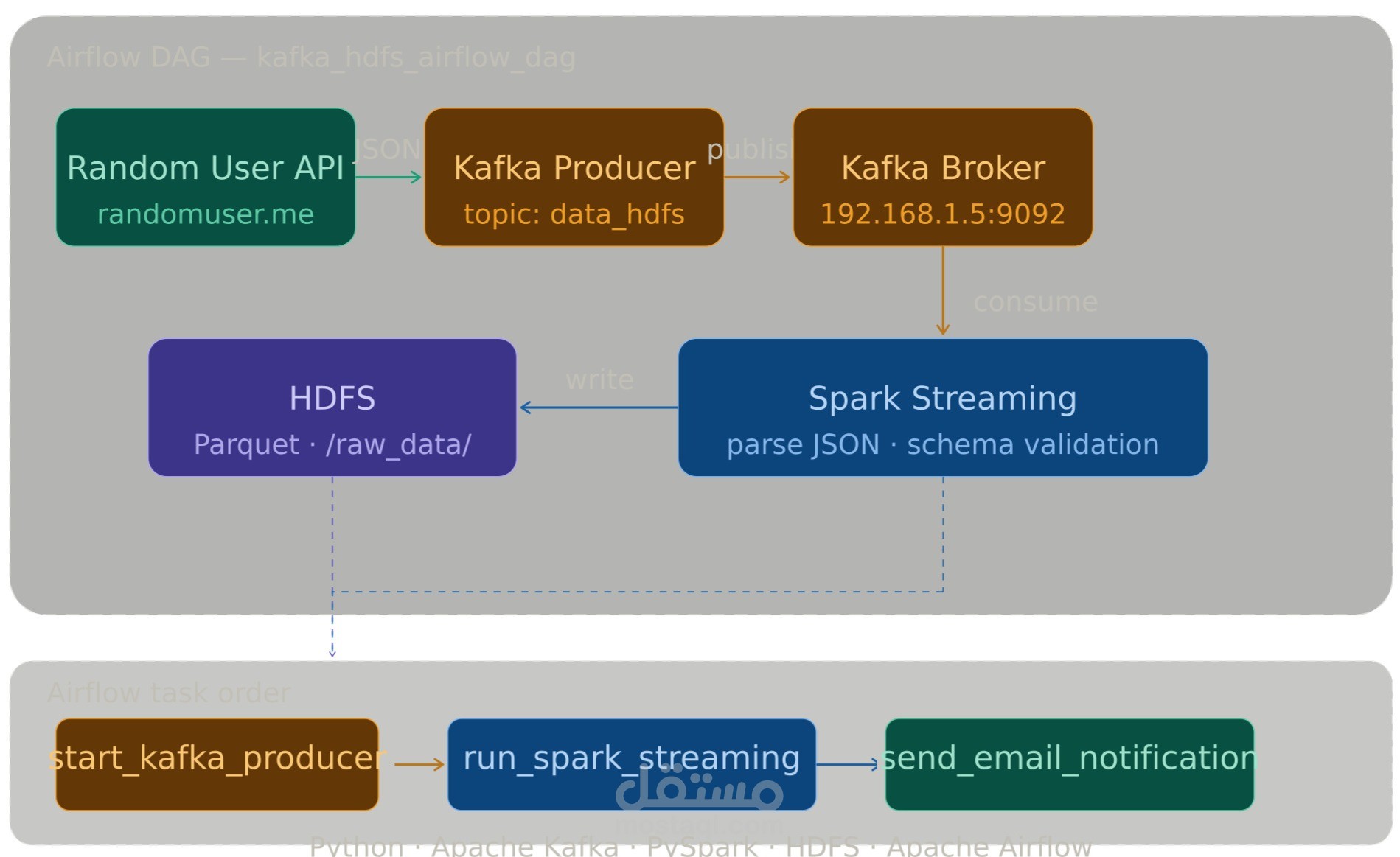
بناء Kafka Producer بـ Python يجلب بيانات المستخدمين من Random User API ويرسلها لـ Kafka Topic كل 0.5 ثانية بصيغة JSON.
2️⃣ المعالجة الفورية (Stream Processing)
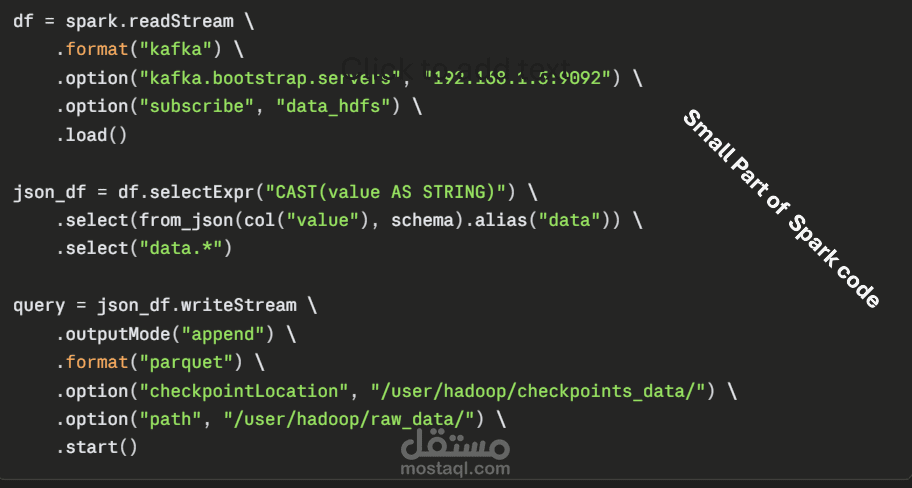
استهلاك الـ stream باستخدام PySpark Structured Streaming مع تطبيق Schema Validation وتحويل البيانات من JSON لـ DataFrame منظم.
3️⃣ التخزين (Storage)
كتابة البيانات المعالجة على HDFS بصيغة Parquet مع Checkpoint لضمان عدم فقدان البيانات عند أي انقطاع.
4️⃣ الأتمتة والمراقبة (Orchestration)
أتمتة كامل الـ pipeline باستخدام Apache Airflow بترتيب:
Kafka Producer → Spark Streaming → Email Notification عند الانتهاء.
?️ التقنيات المستخدمة:
Python — Apache Kafka — PySpark— HDFS — Apache Airflow — Parquet
? المشروع يُظهر قدرة على بناء pipeline لمعالجة البيانات الفورية من الصفر وليس مجرد batch processing.